Command Palette
Search for a command to run...
TADA:一种通过文本-声学双对齐实现语音建模的生成式框架
TADA:一种通过文本-声学双对齐实现语音建模的生成式框架
Trung Dang Sharath Rao Ananya Gupta Christopher Gagne Panagiotis Tzirakis Alice Baird Jakub Piotr Cłapa Peter Chin Alan Cowen
摘要
现代文本转语音(TTS)系统越来越多地采用大语言模型(LLM)架构,以实现可扩展的高保真零样本(zero-shot)生成。然而,这些系统通常依赖于固定帧率(fixed-frame-rate)的声学词元化(tokenization),导致生成的语音序列长度显著长于对应的文本序列,且二者在时间上不同步。这种序列长度的差异不仅造成计算效率低下,还常常引发 TTS 系统中的幻觉现象,并加剧了口语建模(SLM)中的模态差距(modality gap)。在本文中,我们提出了一种新颖的词元化方案,该方案在连续声学特征与文本词元之间建立了一对一的时间同步关系,从而使得在单个 LLM 中进行统一、单流(single-stream)建模成为可能。我们证明,这种同步词元在保持高保真音频重构能力方面表现优异,并且可以通过带有流匹配头(flow matching head)的大语言模型在潜在空间(latent space)中进行有效建模。此外,通过在上下文中无缝切换语音模态的能力,我们实现了仅文本引导(text-only guidance)——这是一种将来自纯文本模式和文本-语音模式的 logit 值混合的技术,从而灵活弥合通往纯文本 LLM 智能的差距。
一句话总结
TADA 是一种生成式语音建模框架,它引入同步 tokenization 方案,将声学特征与文本 token 逐一对齐,从而在统一单流 LLM 中进行建模,并采用流匹配头和纯文本引导来弥合模态差距,向纯文本 LLM 智能靠拢,在实现高保真零样本 TTS 的同时减少幻觉与计算低效。
核心贡献
- 一种同步 tokenization 方法强制声学特征与文本 token 之间建立一一对齐,使大语言模型能够进行统一的单流处理,从而避免固定速率声学 token 的序列长度不匹配问题。
- 这些同步 token 在保持高保真音频重建的同时,能够在潜在空间中由配备流匹配头的大语言模型有效学习。
- 引入纯文本引导,这是一种混合纯文本模式与文本‑语音联合模式 logits 的技术,用于弥合模态差距,并将纯文本大语言模型的智能融入口语建模。
引言
作者聚焦语音生成,在该领域中,将语言内容与声学实现对齐仍然是一个核心挑战。以往的方法通常将文本转语音视为序列映射,或依赖单独的对齐模块,这往往导致韵律脆弱、表现力有限。为此,他们引入 TADA,一种通过双对齐机制联合建模文本和声学表示的生成框架,从而实现更自然、更可控的语音合成。
数据集
作者从三个来源构建了一个大规模多语言语音语料库并对其进行了处理,用于训练。关键细节如下。
- LibriLight 语料库:一个公开的英文有声书集合。
- 英语专有数据集:专门为对话语音而整理。
- 多语言专有数据集:包含七种语言的语音(中文、法语、意大利语、日语、葡萄牙语、波兰语、德语)。
所有原始音频通过语音活动检测(VAD)分割为不超过 30 秒的话语片段。最终得到 27 万小时英语数据和 63.5 万小时非英语数据,总计超过 90 万小时。
处理流程与过滤:
- 自动转写:Parakeet-TDT-0.6b-v2 用于转写英语和欧洲语言;Whisper-V3 转写中文和日语。
- 对齐和 token 向量在训练开始前从转写文本中预先提取。
- 基于对齐指标的幻觉过滤:如果对齐位置跨越超过三个连续帧,或者对齐位置之间的间隙超过 150 帧(3 秒),则该片段被丢弃。此类模式通常指示幻觉文本、非语音背景或缺失转写。过滤可使用对齐信息在训练过程中动态进行。
数据直接用于模型训练,并进行在线幻觉过滤。未报告进一步的裁剪或特殊混合比例。
方法
作者提出一种新颖框架,在连续声学特征与文本 token 之间建立一一同步,从而在大语言模型(LLM)中实现统一单流建模。该方法包括两个主要阶段:联合语音‑文本 tokenization 模块和 TADA(文本‑声学双对齐)建模架构。
Tokenization 模块包含时序对齐器、token 编码器和声学解码器。对齐器处理语音波形及其对应的文本 token ID,利用连接时序分类(CTC)和 Viterbi 算法生成文本 token 与音频帧之间的精确映射。
编码器和解码器在变分自编码器(VAE)框架内运作,如下图所示:
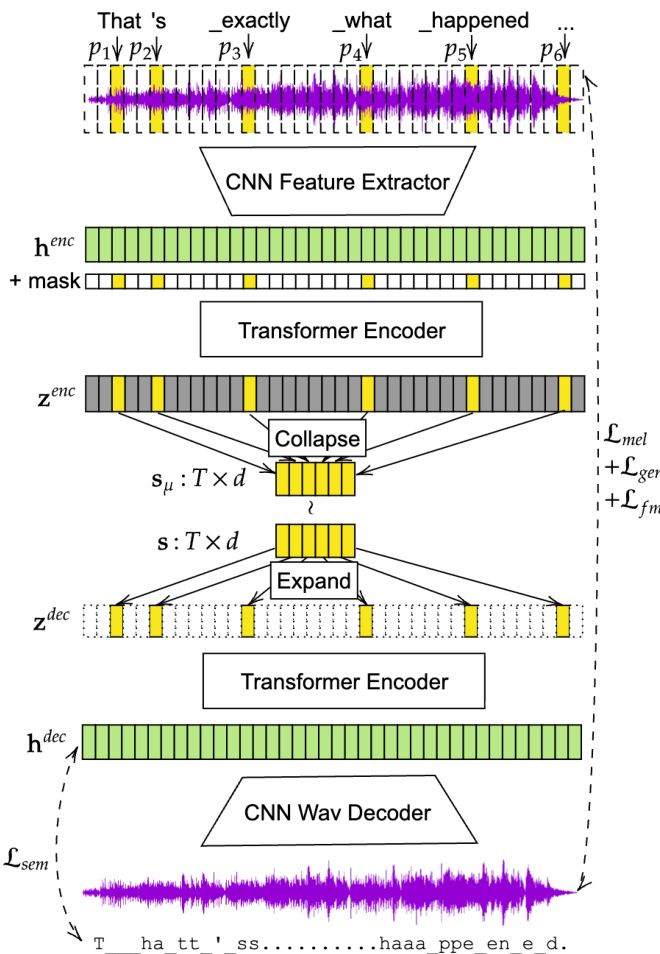
编码器使用基于 CNN 的特征提取器将原始音频投影到帧级表示,然后由结合了对齐位置的基于 Transformer 的编码器进行处理。一个二值指示掩码引导多头注意力机制将声学信息集中到与文本对齐的位置。随后对序列进行压缩,提取出每个语言 token 的潜在均值向量。为确保鲁棒的自回归建模,应用重参数化技巧对潜在表示进行采样。解码器在这些 token 上进行特征扩展,并在对齐位置的引导下生成密集序列,该序列经 Transformer 和基于多层 CNN 的模块转换,最终合成原始波形。VAE 使用复合目标函数进行优化,包括多尺度梅尔谱损失、对抗损失、特征匹配损失、语义损失和 KL 散度。
为对这些同步 token 进行建模,作者引入 TADA,它将 LLM 主干与流匹配头相结合。参考框架图:
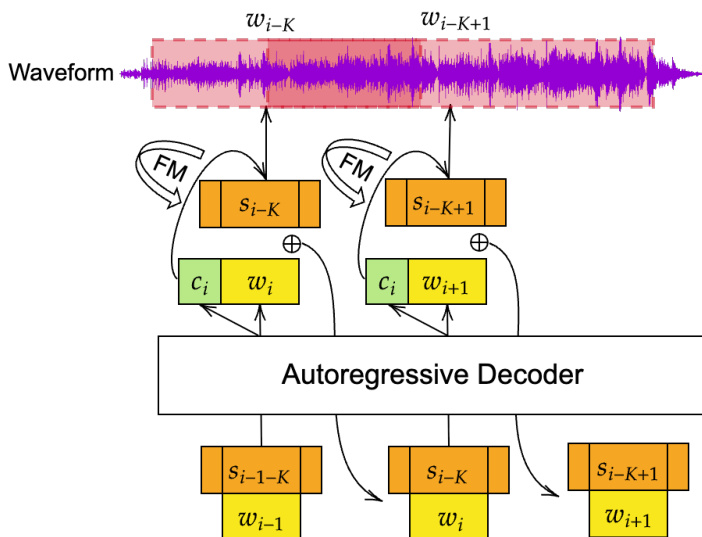
该架构通过将文本和声学输入嵌入相加融合,对传统 LLM 进行了修改。为允许文本前瞻,声学特征被移位 K 个位置,将位置 i 的文本 token 与位置 i−K 的 token 的声学特征耦合。这种同步建模在固定序列长度下最大化音频时间上下文。LLM 每一步的最后一个隐藏状态同时馈入语言模型头和流匹配头。
流匹配头联合预测每个文本 token 对应的声学特征和持续时间。它采用带格雷编码的 Bit Diffusion 对离散帧时长进行建模,具体而言是 token 前后的空白帧数量。以 LLM 隐藏状态 ci 为条件,该头学习一个向量场 vθ(yt,t∣ci),将高斯噪声分布转化为目标分布。训练目标最小化流匹配损失,可选地结合文本交叉熵和知识蒸馏损失。
为缓解引入音频时常给语言模型带来的模态差距,作者提出无语音引导(SFG)。该技术通过调整 logits 的尺度,混合纯文本模式与文本‑语音模式的 logits,使模型能在上下文中无缝切换语音模态,并以极低的推理开销弥合能力差距,向纯文本 LLM 智能靠拢。此外,在步骤级别采用可流式拒绝采样,通过基于与参考说话人嵌入的余弦相似度对流匹配候选进行排序,将生成引导远离低质量输出并确保说话人一致性。
实验
评估涵盖在 SeedTTS-Eval、LibriTTS 和 EARS 上的语音克隆,使用客观和主观指标,以及通过对话困惑度和故事完形填空任务进行的口语建模。TADA 的同步 tokenization 实现了零幻觉和具有竞争力的说话人相似度,并通过无文本引导和拒绝采样提升了长文本表现力。在口语建模中,纯文本引导使模型超越文本‑语音基线并接近纯文本精度,而语音上下文可进一步增强故事理解。分析证实了在低帧率下具有鲁棒的固定速率重建、尽管存在扩散开销但推理高效,以及知识蒸馏对保持语言能力的重要性。
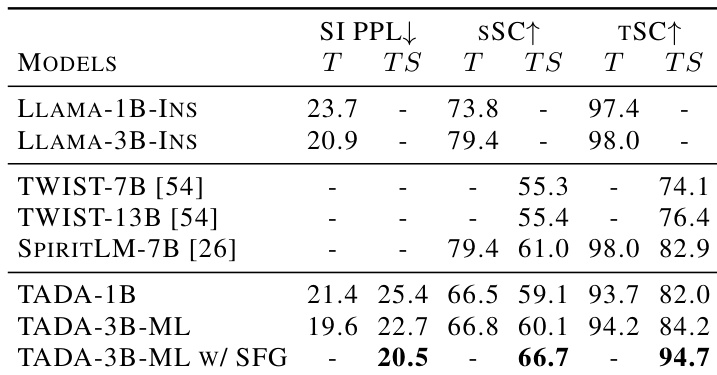
作者在对话困惑度和口语叙事理解基准上评估了其 TADA 模型的语言能力。结果表明,虽然引入语音模态对纯文本性能略有影响,但模型能有效处理文本‑语音任务,并在特定基准上优于更大的基线模型。应用纯文本引导进一步提升了性能,使模型超越其他文本‑语音基线,并紧密接近纯文本精度。得益于在口语文本分布上进行微调,TADA 模型取得了较强的纯文本困惑度分数,优于基础 Llama 模型。在文本‑语音模式下,尽管参数更少,TADA-3B-ML 在 tSC 基准上优于更大的 SpiritLM-7B。纯文本引导的应用使 TADA-3B-ML 超越所有文本‑语音基线,紧密接近其纯文本性能水平。
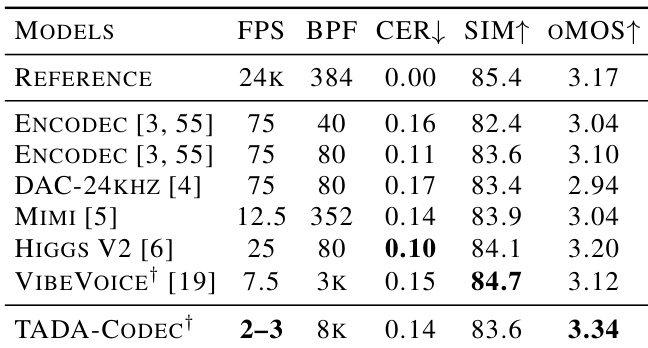
作者将 TADA-Codec 与多种离散和连续基线进行比较,以评估其作为建模目标的可行性。结果表明,尽管帧率显著更低,TADA-Codec 的重建质量与固定速率 tokenizer 相当。值得注意的是,它在评估模型中获得了最高的感知音频质量分数。TADA-Codec 的运行帧率远低于 EnCodec 和 DAC 等基线,同时保持有竞争力的重建保真度。TADA-Codec 取得了最高的客观平均意见分数,在感知质量上优于参考模型和其他模型。虽然其他模型在字符错误率或说话人相似度等特定指标上领先,但 TADA-Codec 在所有维度上均具有竞争力。
作者进行了消融研究,分析不同语言保留损失配置下语言保留与音频质量之间的权衡。结果显示,所有变体的文本转语音性能保持一致,而包含知识蒸馏损失实现了最佳语言保留。不同损失权重配置下文本转语音质量指标保持稳定。与基础配置相比,增加交叉熵损失权重可改善困惑度。结合交叉熵损失和知识蒸馏损失可获得最低困惑度,表明语言保留效果最佳。
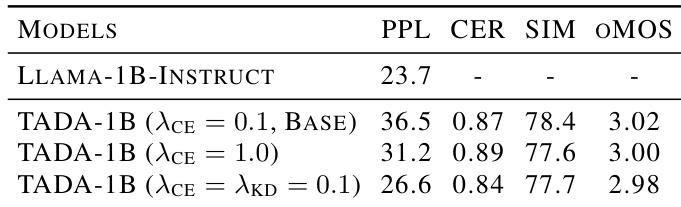
从 EARS 数据集的评估结果来看,TADA-3B 模型从无文本引导和在线拒绝采样中显著获益,以对抗长文本生成中的说话人漂移。增强后的模型取得了有竞争力的主观性能,在比较系统中说话人相似度和自然度均排名第二。无文本引导和在线拒绝采样的加入大幅提高了 TADA-3B 的说话人相似度,使其接近表现最好的基线。在主观评估中,增强后的 TADA 模型在说话人相似度和自然度上均排名第二,表明其高表现力。FireRedTTS-2 的字符错误率远高于其他模型,表明尽管相似度分数相当,但其内容保存的可靠性较低。
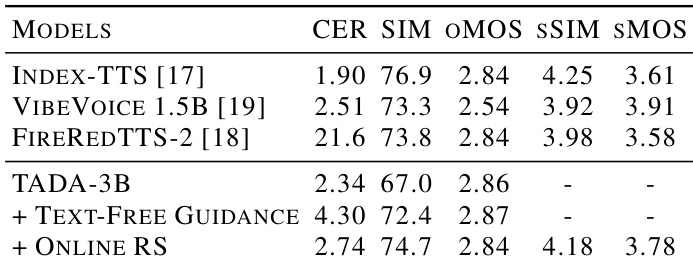
作者评估了 TADA-1B 在不同流匹配采样步数下的计算开销和文本转语音性能。结果表明,语音质量在中等采样步数下收敛,这提供了低错误率与高相似度和自然度分数的最佳平衡。尽管更多采样步数会增加每 token 的延迟,但模型保持了低实时因子,并因其降低的帧率而实现了整体推理速度的显著提升。语音生成质量在中等流匹配采样步数下收敛,在所有质量指标上达到最佳性能。增加采样步数会增加流匹配组件的每 token 延迟,但整体实时因子仍保持高效。尽管存在扩散头的开销,凭借其显著降低的帧率,模型实现了相比基线的显著推理加速。
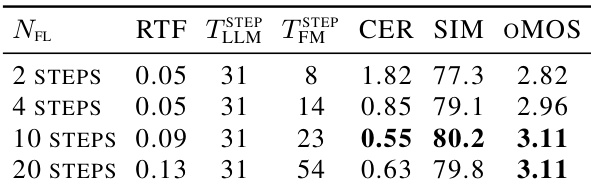
实验评估了 TADA 在对话语言理解、编解码器重建、损失配置消融、长文本生成和推理效率方面的表现。模型在有效处理语音模态的同时保留了语言能力,而低帧率编解码器在测试的 tokenizer 中取得了最高的感知质量。无文本引导结合在线拒绝采样改善了长文本合成中的说话人相似度,中等流匹配步数在质量和速度之间取得了最佳平衡,并利用模型降低的帧率实现了显著的推理加速。