Command Palette
Search for a command to run...
世界动作模型是零样本策略
世界动作模型是零样本策略
摘要
目前最先进的视觉-语言-动作(Vision-Language-Action, VLA)模型在语义泛化方面表现出色,但在面对新环境中未知的物理运动时却难以实现有效泛化。为此,我们提出了 DREAM ZERO,这是一种基于预训练视频扩散骨干网络构建的世界动作模型(World Action Model, WAM)。与 VLA 不同,WAM 通过预测未来的世界状态和动作来学习物理动力学,并将视频作为世界演化的密集表示。通过对视频和动作进行联合建模,DREAM ZERO 能够从异构机器人数据中高效地学习多样化的技能,而无需依赖重复性的示范演示。在真实机器人实验表明,与目前最先进的 VLA 相比,DREAM ZERO 在新任务和环境中的泛化能力提升了 2 倍以上。关键在于,通过模型和系统层面的优化,我们使得一个拥有 140 亿参数(14B)的自回归视频扩散模型能够以 7Hz 的频率执行实时闭环控制。最后,我们展示了两种形式的跨具身迁移(cross-embodiment transfer):仅使用其他机器人或人类产生的视频示范数据,在仅投入 10–20 分钟数据的情况下,未见过任务的性能相对提升了 42% 以上。更令人惊讶的是,DREAM ZERO 实现了少样本具身适应(few-shot embodiment adaptation),仅需 30 分钟的游戏(play)数据即可迁移至新的具身形态,同时仍保持零样本(zero-shot)泛化能力。
一句话总结
DREAM ZERO 是一个世界动作模型,建立在预训练的 14B 自回归视频扩散骨干网络之上,通过预测未来的世界状态和动作来学习物理动力学,能够从异构机器人数据中学习多样化的技能而无需重复演示,相比最先进的视觉 - 语言 - 动作模型,泛化能力提升超过 2 倍,实现 7Hz 的实时闭环控制,并通过仅视频的跨本体迁移在未见任务上实现超过 42% 的相对改进。
核心贡献
- DREAM ZERO 被引入为一种世界动作模型,建立在预训练的视频扩散骨干网络之上,利用视频作为物理动力学的密集表示,联合预测未来的世界状态和动作。这种方法在真实机器人实验中,相比最先进的 VLAs,在新任务和环境上的泛化能力提升超过 2 倍。
- 模型和系统优化使 14B 自回归视频扩散模型能够以 7Hz 进行实时闭环控制。该能力避免了替代世界模型架构通常所需的测试时优化或搜索过程。
- 演示了跨本体迁移,其中来自其他机器人或人类的仅视频演示仅需 10 到 20 分钟的数据,在未见任务性能上带来超过 42% 的相对改进。该方法还支持少样本本体适应,通过仅 30 分钟的操作数据迁移到新本体,同时保留零样本泛化能力。
引言
最先进的视觉 - 语言 - 动作模型在语义泛化方面表现出色,但由于缺乏时空先验,难以适应未见的物理动作或新环境。这些模型通常依赖重复演示,且在没有大量特定任务数据的情况下无法在不同机器人本体之间转移技能。作者引入了 DREAM ZERO,这是一个建立在预训练视频扩散骨干网络之上的 14B 世界动作模型,联合预测未来的世界状态和动作。该架构允许系统从异构机器人数据中学习多样化技能,同时从网络规模视频预训练中继承丰富的物理动力学。因此,与现有 VLAs 相比,该模型在零样本泛化方面实现了超过 2 倍的改进,并支持使用最小仅视频演示进行跨本体迁移。系统优化进一步实现了 7Hz 的实时闭环控制。
数据集
-
数据集组成与来源
- 利用两个主要来源进行预训练:专有的 AgiBot G1 遥操作数据和公开的 DROID 数据集。
- AgiBot 数据涵盖 22 个真实世界环境,包括家庭、餐厅和办公室,总计约 500 小时,跨越 7.2K 集。
- DROID 作为在 Franka 单臂机器人上收集的异构验证集,以确保可复现性。
- 后训练依赖于在 AgiBot 机器人上收集的三个特定下游任务。
-
各子集的关键细节
- AgiBot 预训练集平均时长为 4.4 分钟,每集包含约 42 个子任务。
- 后训练子集包括叠衣服(33 小时)、水果包装(12 小时)和清理桌子(40 小时)。
- DROID 子集用于评估在开源异构数据上的性能。
-
模型使用与训练配置
- 训练使用 Wan2.1-I2V-14B-480P 图像到视频扩散骨干网络。
- 预训练运行 100K 步,AgiBot 和 DROID 数据集的全局批量大小均为 128。
- 后训练每个特定任务包含 50K 步。
- 文本编码器、图像编码器和 VAE 保持冻结,而 DiT 块和动作编码器进行更新。
- 数据准备期间过滤掉空闲动作。
-
处理与收集策略
- 数据收集优先考虑多样性而非重复性,在多样的真实世界设置中收集,而非受控实验室。
- 每集结合三个不同的任务,以最大化多样性并鼓励学习平滑的任务转换。
- 任务在收集 50 集后从收集表中弃用,以强制扩展任务分布。
- 相对关节位置作为默认动作表示。
- 评估协议包括在初始场景上应用图像叠加,以减少后训练评估期间的方差。
方法
作者提出了 DreamZero,这是一个旨在将预训练视频扩散模型转换为有效世界动作模型 (WAMs) 的框架。如概述所示,该系统利用多样化、非重复的预训练数据,实现对未见任务和环境零样本泛化,以及对新本体的少样本适应。

核心架构是联合视频 - 动作扩散 Transformer (DiT)。参考详细说明了训练和推理流程的框架图。模型输入包括视频、动作、本体感知和语言。视频帧通过 VAE 编码器编码为潜变量,而动作由动作编码器处理。本体感知和语言由状态/文本编码器处理。这些模态被融合并传入因果 DiT 块。模型训练目标是联合去噪视频潜变量和动作块。
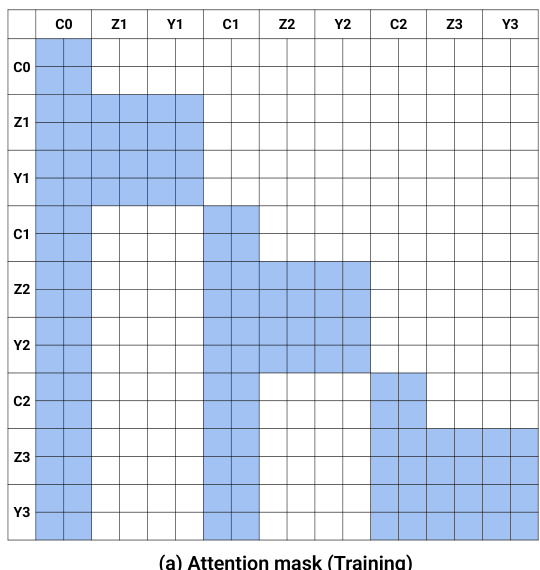
训练期间,采用流匹配目标。模型预测视频和动作模态的速度场。为了处理可变长度的轨迹,模型以自回归、分块的方式运行。每个块包含固定数量的潜变量帧,匹配动作视界。注意力掩码(如网格图所示)确保当前噪声块可以关注先前块的干净上下文,同时防止来自未来 tokens 的信息泄露。该设计促进了教师强制,即模型训练为基于干净的先前块对当前块进行去噪。
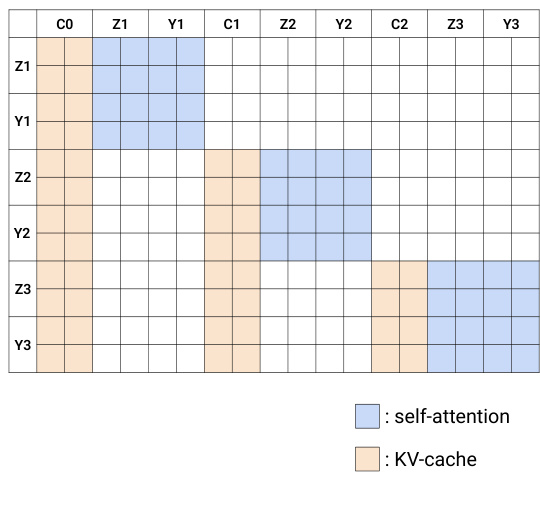
对于推理,系统利用闭环真实世界执行策略。与可能遭受模态未对齐或需要视频下采样的双向模型不同,自回归设计允许视频帧和机器人动作之间的精确对齐。如时间线比较所示,双向方法通常在视频和动作采样点之间引入不匹配。相反,自回归方法保持了一致的视频上下文。此外,系统利用了机器人的闭环特性:在动作块执行后,预测的未来帧在 KV cache 中被替换为真实观测值。这消除了累积误差,并通过 KV cache 实现了高效推理。

为了解决扩散模型的延迟瓶颈,作者引入了 DREAMZero-Flash。该优化解耦了视频和动作的噪声调度。参考可视化此解耦的噪声调度图。虽然标准训练使用共享的统一时间步,但 Flash 使用 Beta 分布将视频时间步偏向高噪声状态,同时保持动作时间步统一。这训练模型从噪声视觉上下文中预测干净动作,允许在推理期间使用更少的扩散步数而不降低动作质量。这为实时控制带来了显著加速。
实验
在 AgiBot 和 Franka 机器人上进行的实验验证,与基线视觉 - 语言 - 动作模型相比,DREAMZero 在未见任务和环境上实现了卓越的零样本泛化,尤其是在利用多样化训练数据时。联合视频 - 动作公式实现了稳健的跨本体迁移和少样本适应,仅使用视觉信息,而基线模型往往过拟合重复演示。此外,消融研究表明,自回归架构和系统优化在增强时间一致性和推理效率的同时保持了性能质量。
该表格评估了使用 DREAMZERO 框架的跨本体迁移学习对未见任务任务进度的影响。它比较了基线模型与增强有人类演示和其他机器人本体视频数据的版本,表明两种迁移方法都显著提升了性能。Human2Robot 和 Robot2Robot 迁移策略均比基线 DREAMZERO 模型产生更高的任务进度。Robot2Robot 迁移实现了最高性能,相比基线产生了最大的改进。Human2Robot 迁移也展示了任务进度的显著增益,验证了人类视觉数据的效用,尽管存在形态差异。

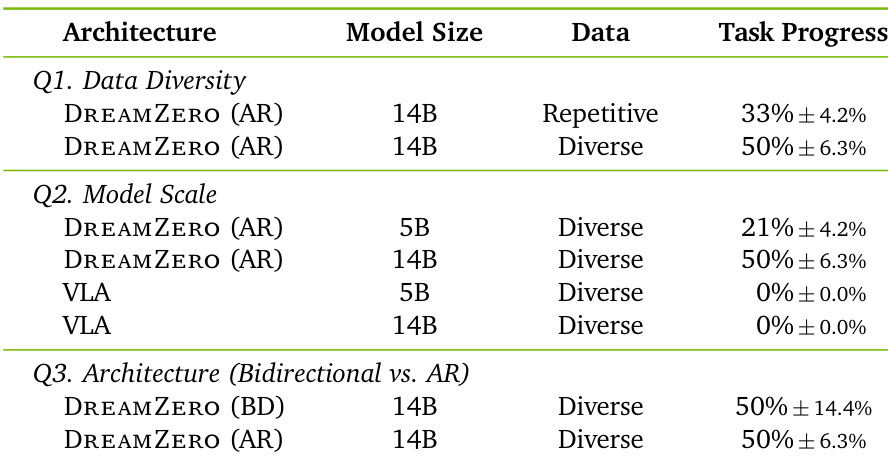
作者使用 DREAMZERO 和 VLA 基线评估了数据多样性、模型规模和架构对任务进度的影响。结果表明,多样化和更大的模型规模显著提升了 DREAMZERO 性能,而 VLAs 无论规模如何都无法从多样化数据中学习。此外,双向和自回归架构产生了可比的任务进度分数。与重复数据相比,DREAMZERO 在多样化数据上训练时实现了更高的任务进度。更大的 DREAMZERO 模型优于较小的模型,而 VLAs 在所有规模上进展微乎其微。自回归和双向架构实现了相似的任务进度水平。
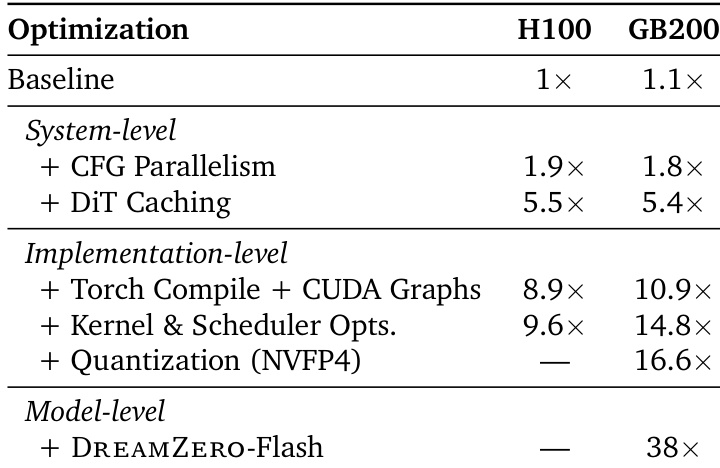
该表格展示了在 H100 和 GB200 硬件上堆叠系统、实现和模型级优化所实现的累积推理加速。结果表明,系统和实现优化产生了显著收益,最终模型级优化在 GB200 架构上提供了显著的性能提升。量化和模型级技术被证明仅适用于 GB200 硬件。系统和实现优化在 H100 上产生了约 9 倍的累积加速,在 GB200 上约为 16 倍。在模型级别添加 DREAMZERO-Flash 导致 GB200 硬件上加速 38 倍。量化和最终模型级优化在此评估中仅限于 GB200 架构。
作者通过减少去噪步数评估了推理速度和任务性能之间的权衡。虽然标准模型在单步推理下遭受显著的精度下降,但 DREAMZERO-Flash 变体在保持速度优势的同时恢复了大部分性能水平。这表明 Flash 变体为实时部署场景提供了更优的平衡。将标准模型减少到单个去噪步会导致任务进度大幅下降。Flash 变体在单步下实现了比标准单步配置显著更高的任务进度。单步推理配置相比多步基线提供了显著的加速。

该评估在跨本体迁移学习、数据多样性和推理效率方面评估了 DREAMZERO 框架,以验证其泛化和速度能力。实验表明,与 VLA 基线相比,迁移策略和多样化训练数据显著改善了任务进度,而更大的规模进一步增强了不同架构的性能。最后,累积优化实现了显著的推理加速,其中 DREAMZERO-Flash 变体在适合实时应用的单步推理中保持了高精度。