Command Palette
Search for a command to run...
旋转位置嵌入作为相位调制:长上下文Transformer中RoPE基数的理论界限
旋转位置嵌入作为相位调制:长上下文Transformer中RoPE基数的理论界限
Feilong Liu
旋转式位置编码 (Rotary Positional Embeddings, RoPE)
摘要
旋转位置嵌入(RoPE)被广泛用于大型语言模型中,通过乘法旋转来编码标记位置,但其在长上下文长度下的行为仍未得到充分表征。在本工作中,我们将RoPE重新解释为应用于复振荡器组的相位调制,从而能够通过经典信号处理理论进行分析。在此框架下,我们推导了为在目标上下文长度内保持位置一致性而必需的RoPE基数参数的原则性下界。这些下界包括一个类似于奈奎斯特极限的基本混叠界限,以及一个约束低频位置模式中相位漂移的直流分量稳定性界限。我们进一步将这一分析扩展到深层Transformer,表明跨层的重复旋转调制会累积角度失配,随着深度增加而收紧对基数的要求。作为对这些结果的补充,我们从有限浮点分辨率出发,推导出了RoPE基数的精度依赖型上界。超过此界限后,增量相位更新在数值上变得不可区分,导致即使在没有混叠的情况下也会发生位置信息擦除。综上所述,上下界共同定义了一个依赖于精度和深度的可行性区域——即长上下文Transformer的“黄金地带”。我们通过针对最先进模型的全面案例研究验证了该框架,包括LLaMA、Mistral和DeepSeek变体,结果表明观察到的成功、失败以及社区的改造措施与预测的界限高度一致。值得注意的是,违反稳定性界限的模型表现出注意力崩溃和长程性能退化,而试图扩展至一百万个以上标记的尝试则遇到了独立于架构或训练的硬性精度墙。我们的分析确立了RoPE基数选择是一项基本的必要架构约束,而非可调超参数,并为在现实数值限制下设计、扩展和改造长上下文Transformer提供了实用指导。
一句话总结
通过经典信号处理理论将旋转位置编码重新解释为复振荡器上的相位调制,本文推导了精度与深度相关的 RoPE 基参数上下界,从而定义了长上下文 Transformer 的可行区域。对 LLaMA、Mistral 和 DeepSeek 变体的案例研究证实,基参数选择作为一种基础架构约束而非可调超参数发挥作用。
核心贡献
- 将旋转位置编码重新解释为复振荡器上的相位调制,借此开展信号处理分析,推导出在扩展上下文与深层 Transformer 层中维持位置一致性的基参数原则性下界。
- 建立由有限浮点分辨率限制的基参数精度依赖上界,定义深度与上下文感知的可行区域,防止长序列处理过程中的位置信号丢失。
- 通过对 LLaMA、Mistral 和 DeepSeek 变体的案例研究验证理论边界,证明所推导的限制能够准确预测在扩展至超过一百万 tokens 时遭遇的注意力崩溃、长程性能退化及数值障碍。
引言
随着大语言模型规模扩展至数十万 tokens,旋转位置编码已成为保留长程依赖的标准方法,但其在极端上下文长度下的可靠性仍难以预测。先前研究依赖经验缩放规则与几何解释,忽略了旋转相位误差如何在 Transformer 层间累积,以及在有限浮点精度下如何退化。作者利用信号处理框架,将旋转位置编码重构为复振荡器上的相位调制,并推导出基频率参数的显式稳定性与精度边界。该分析建立了一个严格的可行区域,解释了长上下文失效模式,并为模型设计提供了基于原理且感知架构的指导,且未引入新的启发式修改。
数据集
- 数据集构成与来源:作者仅提供了论文标题与联系方式。输入文本中未包含数据集构成或来源详情。
- 各子集关键详情:提供的内容中未包含任何子集规模、来源或过滤规则。
- 数据使用与处理:给定文本中未明确训练集划分、混合比例或任何处理流程。
- 裁剪与元数据:未描述任何裁剪策略、元数据构建或其他处理步骤。
提供的材料缺乏必要的方法论或数据章节。请分享相关段落以便完成完整的数据集描述。
方法
作者利用旋转位置编码(RoPE)的信号处理解释,将该机制重构为施加于复振荡器阵列上的相位调制。该视角 enables 对长上下文 Transformer 位置编码稳定性的严格分析。该框架从标准 RoPE 构建开始,通过对成对特征维度应用位置相关旋转来变换查询与键表示。该旋转可等效使用复值特征表示,其中每个二维向量对对应一个复数 zi=x2i−1+jx2i,RoPE 变换简化为乘法运算:zi′(p)=zi⋅ejpθi。该公式表明 RoPE 执行角频率为 θi=base−2(i−1)/d 的相位调制,其中基参数控制振荡器频率的几何间隔。
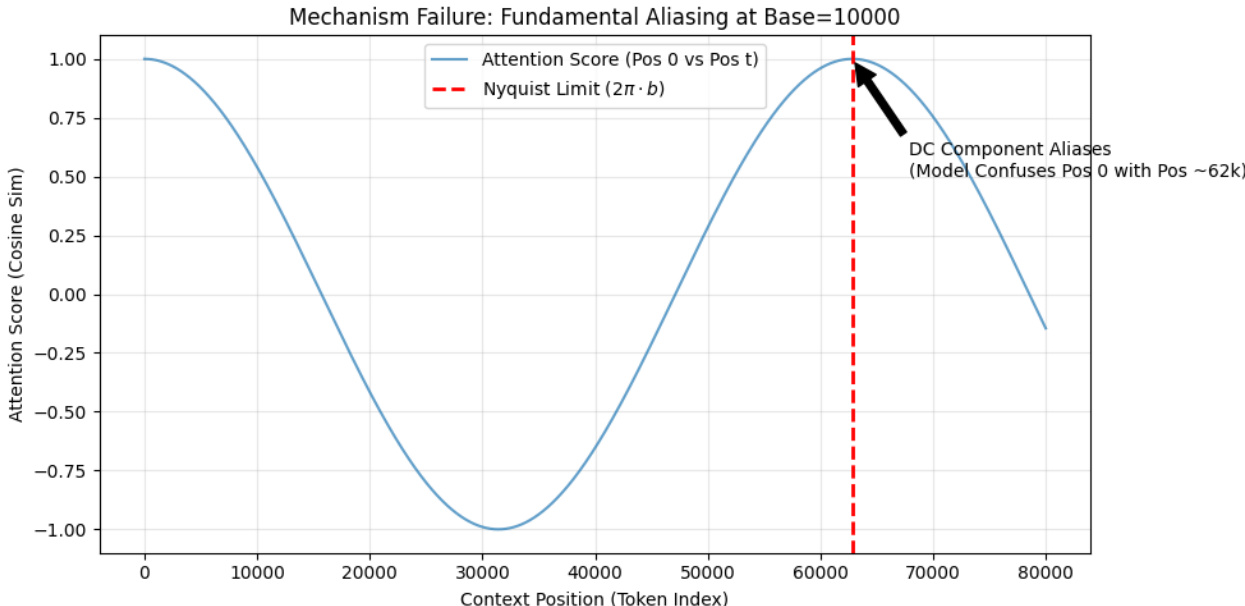
如图下方所示,该振荡器阵列视角将 RoPE 与经典信号处理概念联系起来。该图展示了使用基数为 10,000 时,位置 0 处的一个 token 与序列中不同位置 tokens 之间的注意力得分(余弦相似度)。图表显示平滑的余弦衰减,但在奈奎斯特极限处发生灾难性失效,由 2π⋅base≈62,832 处的红色虚线标记。超过该点后,模型在根本上无法区分位置 0 与位置 62,832,因为基础振荡器的相位完成一个完整周期,导致“碰撞视界”及全局位置网格的崩溃。这直观展示了分析中推导出的基础混叠极限。
该框架进一步分析最低频(准直流)分量的稳定性,这对保留长程对齐至关重要。作者推导出稳定性边界,表明在上下文长度 L 内维持最低频模式相邻旋转的最小余弦相似度 ϵ,RoPE 基必须满足 base≥L/arccos(ϵ)。该条件确保全局位置参考框架不会过度漂移。分析扩展至深层 Transformer,其中 RoPE 在层间重复应用会累积微小的角度偏差。这种层间累积效应收紧了稳定性要求,导出深度依赖边界:base≥L/arccos(ϵ1/N),其中 N 为层数。这解释了为何更深层次的模型需要更大的基参数以维持长程一致性。
最后,该框架纳入数值精度约束。在有限精度算术中,相位增量 Δθ=1/base 必须超过机器精度 ϵmach 方可区分。这确立了 RoPE 基的上界:base<1/ϵmach。该“精度墙”限制了可实现的最大上下文长度,因为将基参数提升至该阈值之上会导致增量相位更新在数值上无法区分,从而在无混叠情况下仍会抹除位置信息。深度与长度依赖的下界及硬件依赖的上界相结合,定义了长上下文 Transformer 中 RoPE 基参数选择的精度与深度依赖可行区域,即“黄金区域”。
实验
该评估将广泛使用的先进 Transformer 模型所部署的 RoPE 配置与既有的经验启发式方法及新推导的理论稳定性边界进行对比。通过根据各架构的 RoPE 基是否落入理论定义的安全运行范围进行分类,分析揭示出多个长上下文模型因配置违反基础约束而系统性退化。最终,该研究证明所提出的理论边界成功诊断了现实架构限制,并解释了现有经验规则无法说明的性能失效问题。
作者分析多个先进 Transformer 模型,以评估其 RoPE 基配置是否符合由一致性与数值精度约束推导出的理论稳定性边界。结果显示部分模型运行于安全范围之外导致不稳定,而其他模型保持在边界内并表现稳定。部分模型因 RoPE 基超出理论稳定性边界被归类为不稳定。特定模型标记为高度稳定,表明其 RoPE 基位于推导的理论范围内。一个假设的目标模型被判定为不可行,暗示其 RoPE 基超出稳定性的实际限制。

实验设置通过将 RoPE 基配置与由一致性与数值精度约束推导出的理论稳定性边界进行对比,来评估先进 Transformer 模型。该分析验证特定嵌入设置是否维持数值稳定性或存在操作失败风险。结果根据模型与这些边界的吻合度,定性将其分类为稳定、不稳定或不可行,证明正确的 RoPE 基选择对于可靠部署至关重要,因为超出实际阈值的配置不可避免地会损害稳定性。