Command Palette
Search for a command to run...
LingxiDiagBench:一种用于在中文精神科咨询与诊断中基准测试大语言模型的多 Agent 框架
LingxiDiagBench:一种用于在中文精神科咨询与诊断中基准测试大语言模型的多 Agent 框架
摘要
精神障碍在全球范围内患病率极高,但精神科医师的短缺以及基于访谈的诊断所固有的主观性,为及时且一致的精神健康评估带来了显著障碍。人工智能辅助精神诊断的进展受到基准缺失的制约,这些基准需同时提供逼真的患者模拟、经临床医师验证的诊断标签以及对动态多轮问诊的支持。我们提出了LingxiDiagBench,这是一个大规模多agent基准,用于评估LLMs在中文静态诊断推理与动态多轮精神问诊中的表现。该基准的核心是LingxiDiag-16K数据集,该数据集包含16,000条与电子病历(EMR)对齐的合成问诊对话,旨在重现涵盖12个ICD-10精神疾病分类的真实临床人口统计学特征与诊断分布。通过对当前最先进LLMs的广泛实验,我们得出以下关键发现:(1)尽管LLMs在二元抑郁-焦虑分类任务上取得了较高准确率(最高达92.3%),但在抑郁-焦虑共病识别(43.0%)及12类鉴别诊断(28.5%)任务上的性能显著下降;(2)动态问诊的表现通常不及静态评估,表明低效的信息收集策略会显著削弱下游的诊断推理能力;(3)基于LLM-as-a-Judge评估的问诊质量与诊断准确率仅呈中度相关,这表明仅凭结构严谨的提问并不能保证得出正确的诊断结论。我们公开了LingxiDiag-16K数据集及完整的评估框架,以支持可重复研究,获取地址为:https://github.com/Lingxi-mental-health/LingxiDiagBench。
一句话总结
LingxiDiagBench 是一个多 Agent 基准测试,利用包含 16,000 份跨 12 个 ICD-10 类别的 EMR 对齐合成对话的 LingxiDiag-16K 数据集,评估大语言模型在中文精神科咨询与诊断方面的表现,支持动态多轮交互,并揭示抑郁症-焦虑症共病识别与 12 路鉴别诊断中的显著性能差距。
核心贡献
- 本文引入了 LingxiDiag-16K,这是一个包含 16,000 份合成精神科咨询对话的数据集,源自电子病历,在 12 个 ICD-10 类别中复制了临床人口统计学特征与诊断分布。
- 本研究开发了 Lingxi-iDiagBench,这是一个基于 Agent 的评估框架,将患者模拟、咨询策略执行与诊断推理解耦为专门的自主 Agent。该基准测试通过三个逐步复杂的诊断任务实现评估操作化,范围从二分类的抑郁症-焦虑症分类到 12 路 ICD-10 多标签预测。
- 在最新大语言模型上的广泛实验揭示了与诊断复杂度相关的显著性能差距,二分类准确率达到 92.3%,而共病识别与 12 路鉴别诊断准确率分别降至 43.0% 和 28%。
引言
全球心理健康专业人员的短缺以及临床访谈的主观性,为及时的精神科评估带来了显著障碍,使得可扩展的 AI 诊断工具日益关键。现有的精神科 AI 评估框架因依赖静态问答、忽略经临床医生验证的诊断标签,且极少支持动态多轮咨询,难以支持实际部署。为弥补这一差距,作者引入了 LingxiDiagBench,这是一个大规模多 Agent 基准测试,用于评估大语言模型在中文精神科诊断与咨询中的表现。他们构建了 LingxiDiag-16K,这是一个包含 16,000 份跨 12 个 ICD-10 类别、与真实电子病历对齐的合成对话数据集,并部署了一个基于 Agent 的评估系统,以模拟真实的患者交互与诊断推理。该框架支持对静态分类与交互式信息收集策略的严格测试,为推进 AI 辅助心理健康评估提供了可复现的平台。
数据集
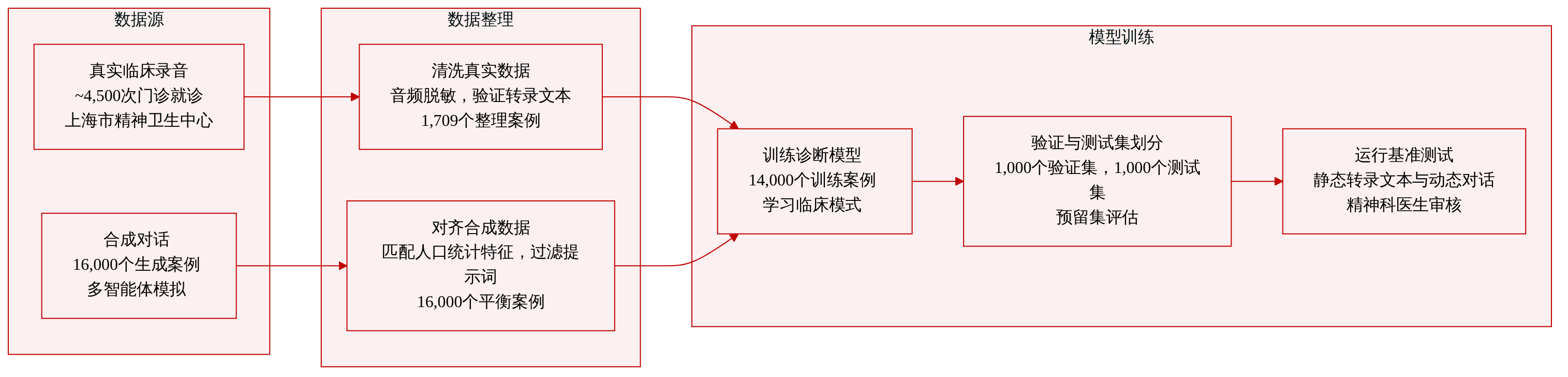
-
数据集构成与来源 作者结合真实临床录音与大规模合成数据集,以平衡诊断真实性与可扩展评估。真实数据源自上海市精神卫生中心的门诊就诊记录,而合成数据通过多 Agent 框架生成,在保护患者隐私的同时复制临床分布。
-
子集详情
- LingxiDiag-Clinical:源自约 4,500 份初始录音,该子集包含 1,709 个筛选后的病例。作者筛选出具有完整电子病历和验证转录的病例。音频经过匿名化处理,通过自动语音识别转录,并进行人工核对。
- LingxiDiag-16K:该合成子集包含 16,000 份咨询对话及配对的生成式 EMR。作者为验证集和测试集各分配 1,000 个样本,其余用于训练,并严格匹配所有划分中的人口统计学与诊断分布。
-
数据使用与处理 作者使用临床子集进行模型训练与基准测试,而合成子集驱动静态与动态评估范式。静态评估依赖固定的合成转录本作为真实标签,而动态评估测试由 Qwen3-32B 驱动的医生 Agent 与模拟患者之间的实时交互。作者通过从真实临床数据的经验分布中采样来控制合成回复长度,并应用针对性提示以防止不自然的措辞和强制的症状披露。
-
元数据构建与额外处理 为使合成输出与现实模式对齐,作者从临床子集中提取人口统计学与临床特征以构建知识图谱,该图谱指导合成 EMR 的概率采样。他们还构建了结合人口统计学、主诉、病史与诊断标签的结构化患者画像,以提示模拟 Agent。两名持证精神科医生随机审查合成样本,以验证临床真实性并确认不存在受保护的健康信息。所有数据收集均遵守 IRB 批准与知情同意协议。
方法
作者提出了一套全面的精神科诊断模拟与评估框架,如图表所示。该系统由数据基础、Agent 系统与基准测试评估模块组成。
数据基础与合成 该系统的基础是 LingxiDiag-16K 数据集,包含 16,000 份合成电子病历(EMR)与对话。该数据集由真实临床门诊病例合成而来,以保留人口统计学与临床分布。合成流程包含七个步骤:采样基本信息(年龄、性别、ICD-10 编码)、生成陪同人员详情、按年龄组创建个人史、生成具有特定症状分布的主诉、撰写现病史叙述、采样辅助字段(躯体疾病、药物过敏),最后将这些字段组装为完整的 EMR 记录。这确保了合成数据与现实分布对齐,同时为训练提供了可扩展的资源。
Agent 系统架构 系统的核心是 Agent 系统,它模拟了一个涉及三个不同 Agent 的临床咨询环境:患者 Agent、医生 Agent 与诊断 Agent。
如下图所示:
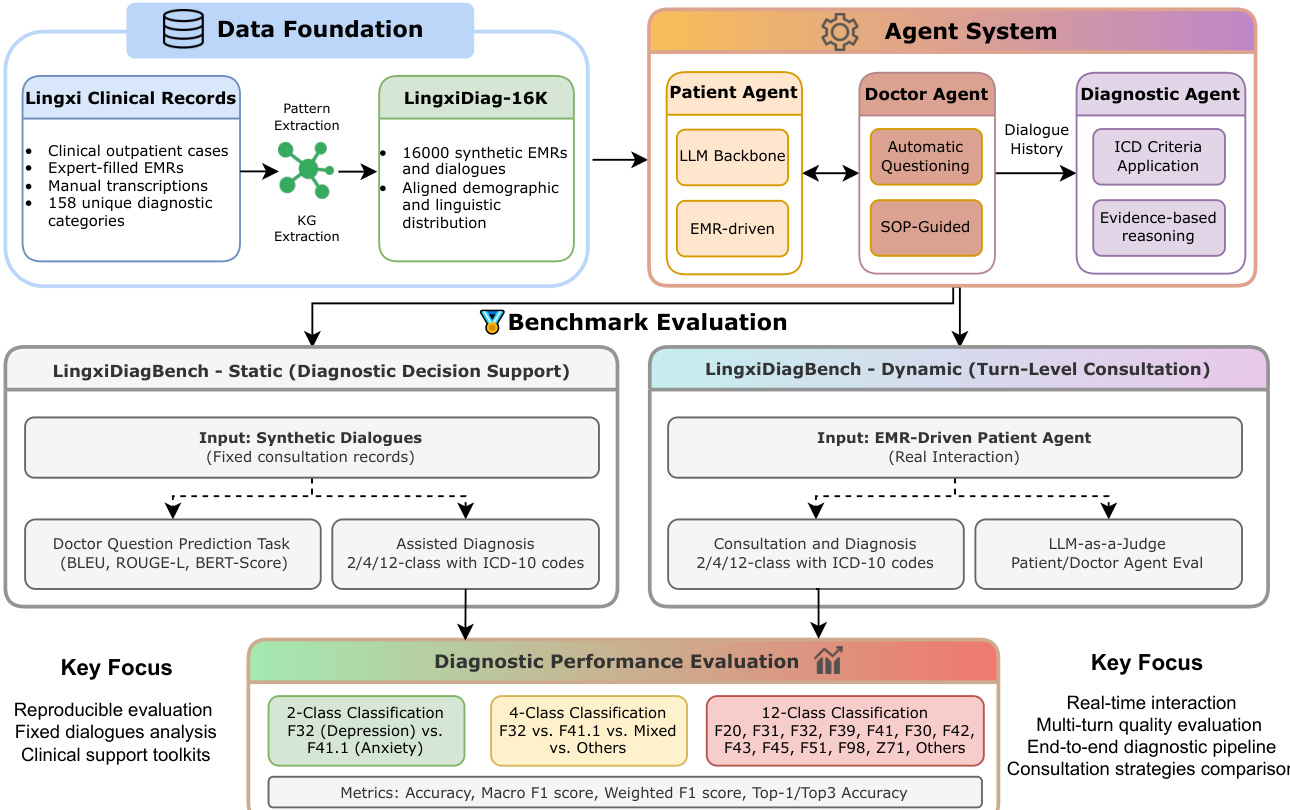
患者 Agent 由合成 EMR 驱动。它在咨询期间扮演患者角色,基于预定义病史生成回复。
医生 Agent 模拟进行访谈的精神科医生。作者实现了四种不同的咨询策略以适应不同的临床推理方法:
- 自由形式策略:大语言模型扮演资深精神科医生,无外部指导,根据患者回复自主选择提问方向。
- 症状树策略:该方法使用源自 MDD-5K 诊断协议的症状决策树。然而,为了解决预定义有限症状集的局限性,作者引入了更灵活的方法。
- APA 指导策略:遵循五个阶段的临床指南:筛查(主诉与症状持续时间)、评估(核心症状细节与功能损害)、深入探究(特定症状与根本原因)、风险评估(自杀与自残筛查)以及结束(关键信息确认)。每个阶段包含强制与可选主题,并带有明确的转换标准。
- APA 指导 + MRD-RAG:这是一种检索增强变体。在评估与深入探究阶段,医生 Agent 检索相关诊断指南。检索过程使用多语言嵌入模型(Qwen3-Embedding-8B)对中文临床指南文档进行嵌入,并在 FAISS 索引中建立索引。检索 top-k(k=5)相似片段,并使用交叉编码器模型(Qwen3-Reranker-8B)进行可选的重新排序步骤,将结果精炼至最相关的 3 个片段。这些片段被注入提示上下文以支持下一问题规划。
诊断 Agent 接收医生与患者 Agent 之间的完整对话历史。与进行实时提问的医生 Agent 不同,诊断 Agent 结合完整转录本应用 ICD 标准,生成最终诊断结论及支持性的临床推理。
基准测试评估 系统使用 LingxiDiagBench 进行评估,分为两种范式:静态与动态。
- 静态(诊断决策支持):在固定咨询记录(合成对话)上评估模型。任务包括医生提问预测(通过 BLEU、ROUGE-L、BERT-Score 衡量)与辅助诊断(2/4/12 类分类,使用 ICD-10 编码)。
- 动态(轮次级咨询):在实时交互场景中评估模型,使用 EMR 驱动的患者 Agent。它评估完整的咨询与诊断过程(2/4/12 类分类),并使用 LLM-as-a-Judge 对患者与医生 Agent 进行评估。
性能在 2 类(例如抑郁症与焦虑症)、4 类和 12 类分类任务上进行衡量,使用的指标包括准确率、Macro F1 分数、Weighted F1 分数以及 Top-1/Top3 准确率。
实验
评估框架结合静态转录本分析与动态交互式咨询,通过多模型 LLM-as-a-Judge 协议,从临床与对话维度评估患者与医生 Agent。实验验证了合成数据能有效捕捉可泛化至现实精神科场景的临床有意义模式,而人类专家评分确认了自动化评分流程的可靠性。定性分析表明,高质量的咨询并不总能转化为更高的诊断准确率,这表明问诊技巧与诊断推理需要分别优化。总体而言,这些发现为开发与完善 AI 驱动的精神科咨询系统奠定了坚实且符合临床实际的基础。
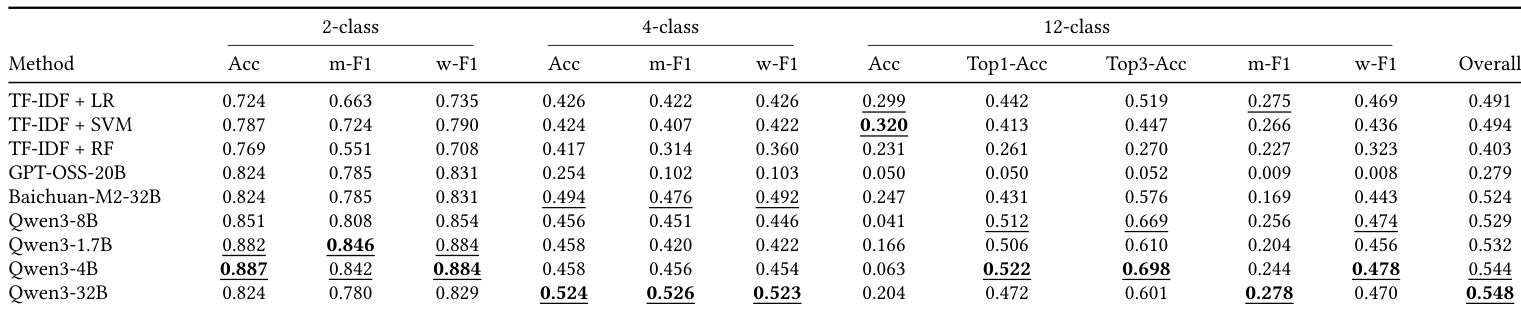
下表对比了 LingxiDiag-Clinical 数据集上的诊断性能,评估了传统机器学习技术与大语言模型。虽然传统方法在二分类任务上保持了合理的准确率,但在多类任务中性能显著下降。相比之下,大语言模型,尤其是 Qwen3 系列,在复杂诊断场景中表现出更优的能力,其中最大模型取得了最佳的整体结果。TF-IDF 等传统方法随着分类任务复杂度从两类增加到十二类,性能出现明显下降。Qwen3-32B 模型在评估的多类任务中实现了最高的整体诊断准确率。Qwen3-4B 模型在十二类分类任务的 Top-3 准确率方面展现出最强能力。
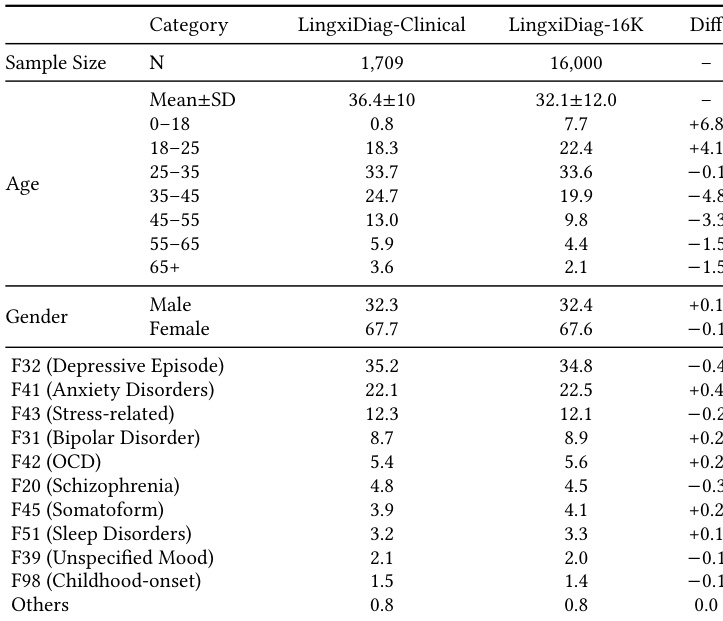
下表对比了真实临床数据集与合成数据集的人口统计学与诊断分布。数据显示,合成数据集在性别平衡与诊断类别流行度方面有效反映了现实临床人群,仅在特定年龄组存在微小偏差。两个数据集的性别分布几乎完全一致,均保持女性占多数。诊断类别比例高度一致,表明合成数据集保留了各种心理健康疾病的临床流行率。合成数据集在年轻人群(特别是 0-18 岁与 18-25 岁年龄段)中的代表比例略高,而在老年群体中比例较低。
作者评估了四种咨询策略下的医生 Agent,发现结合 MRD-RAG 的 APA 指导策略在各种模型上实现了最一致且优越的性能。诊断准确率高度依赖任务复杂度,模型在二分类任务中表现出优异能力,但在细粒度多类诊断中性能显著降低。此外,结果表明咨询质量与诊断能力之间存在脱节,因为交互式对话指标的高分并不能可靠预测更好的诊断结果。与其他方法相比,APA 指导 + MRD-RAG 策略在咨询质量与诊断指标上均持续取得最高性能。随着分类任务变得更加细粒度(从二分类到十二类预测),诊断准确率显著下降。模型性能具有任务特异性,在不同策略下,不同模型在二分类与多类诊断中分别领先。
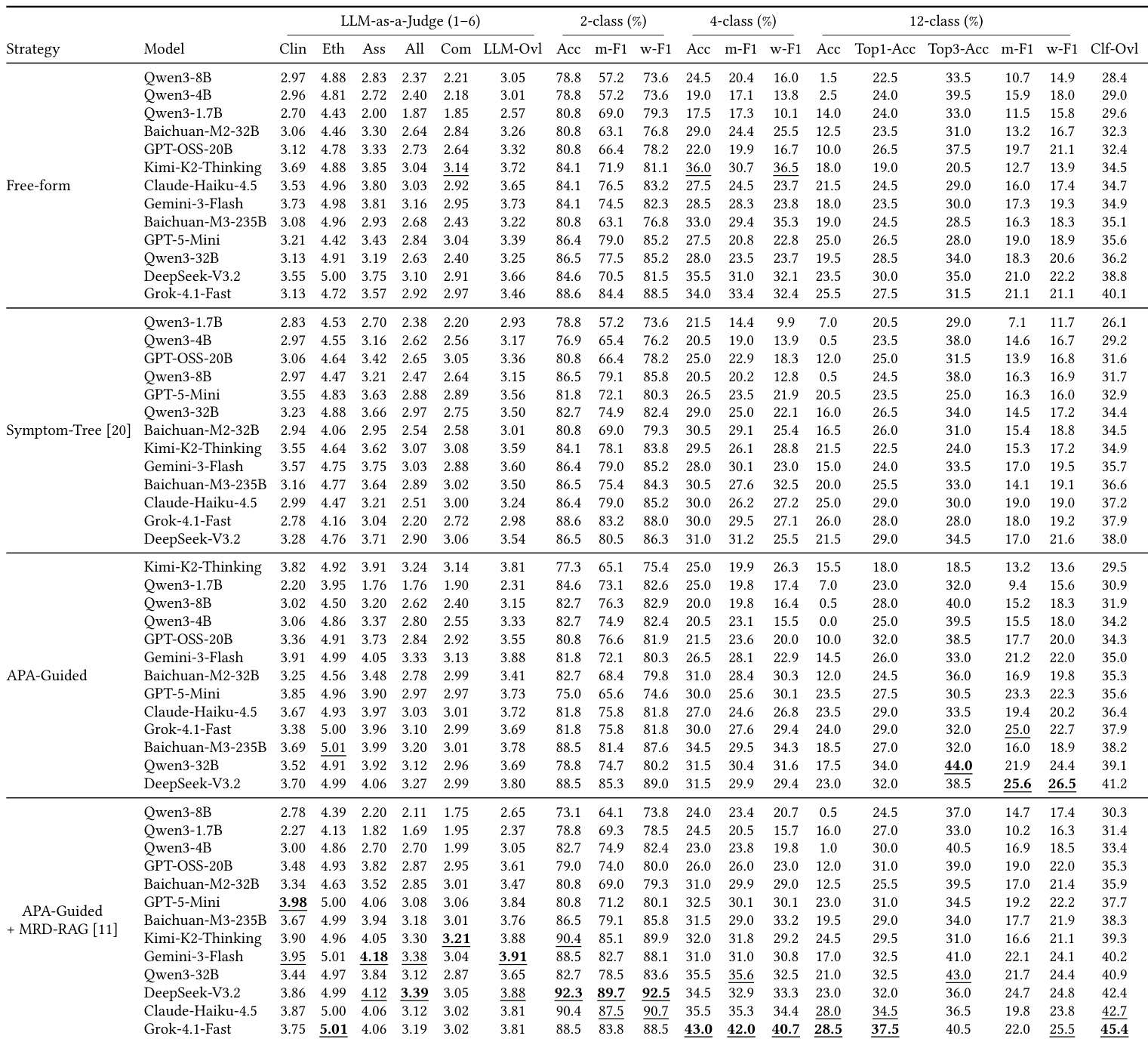
实验在 2 类、4 类和 12 类任务上评估诊断准确率,比较了传统机器学习方法与大语言模型。虽然大多数方法的二分类性能稳健,但随着诊断类别复杂度的增加,准确率下降。传统方法,特别是 TF-IDF 结合逻辑回归,展现出优越的整体性能,在多类 F1 分数方面表现突出,而大模型在此方面表现较弱。Gemini-3-Flash 在 2 类分类任务中准确率领先。TF-IDF + LR 实现了最高的整体得分,在复杂多类指标上优于大语言模型。12 类任务的诊断准确率显著下降,GPT-5-Mini 在该类别中记录了最佳准确率。
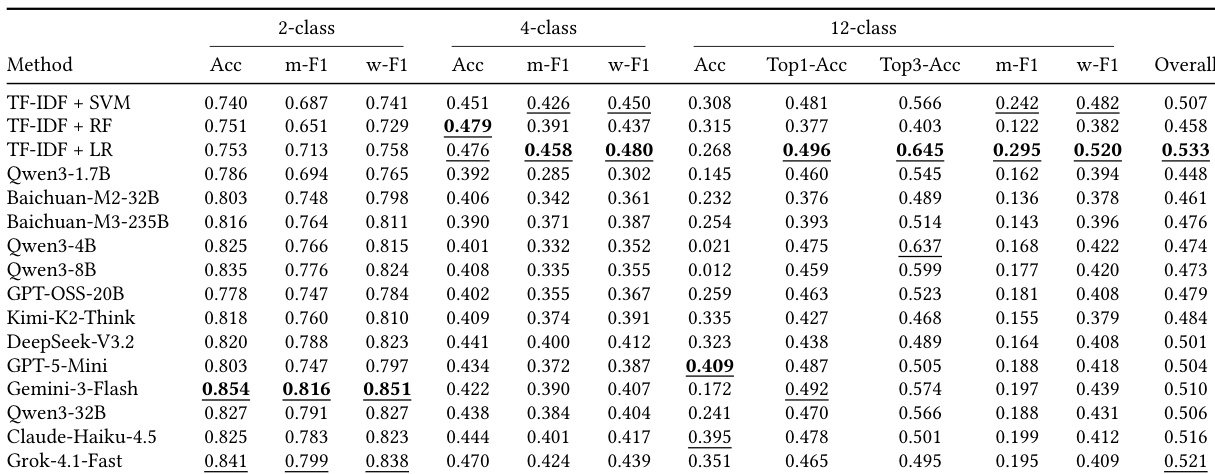
实验在六个维度上评估患者 Agent 质量,将 MDD-5K-Patient 基准测试与 LingxiDiag-Patient 基准测试以及多种骨干模型进行比较。与 MDD-5K-Patient 版本相比,LingxiDiag-Patient 版本在所有维度上持续产生更高的性能得分。此外,表现最佳的 LingxiDiag-Patient 模型所取得的分数与真实世界 LingxiDiag-Clinical 数据集观察到的分数相当。LingxiDiag-Patient 模型在所有六项评估指标上持续优于 MDD-5K-Patient 模型。Qwen3-8B 等模型在使用 LingxiDiag-Patient 版本时展现出显著的性能提升。LingxiDiag-Patient 模型的性能与实际 LingxiDiag-Clinical 数据集的结果高度一致。
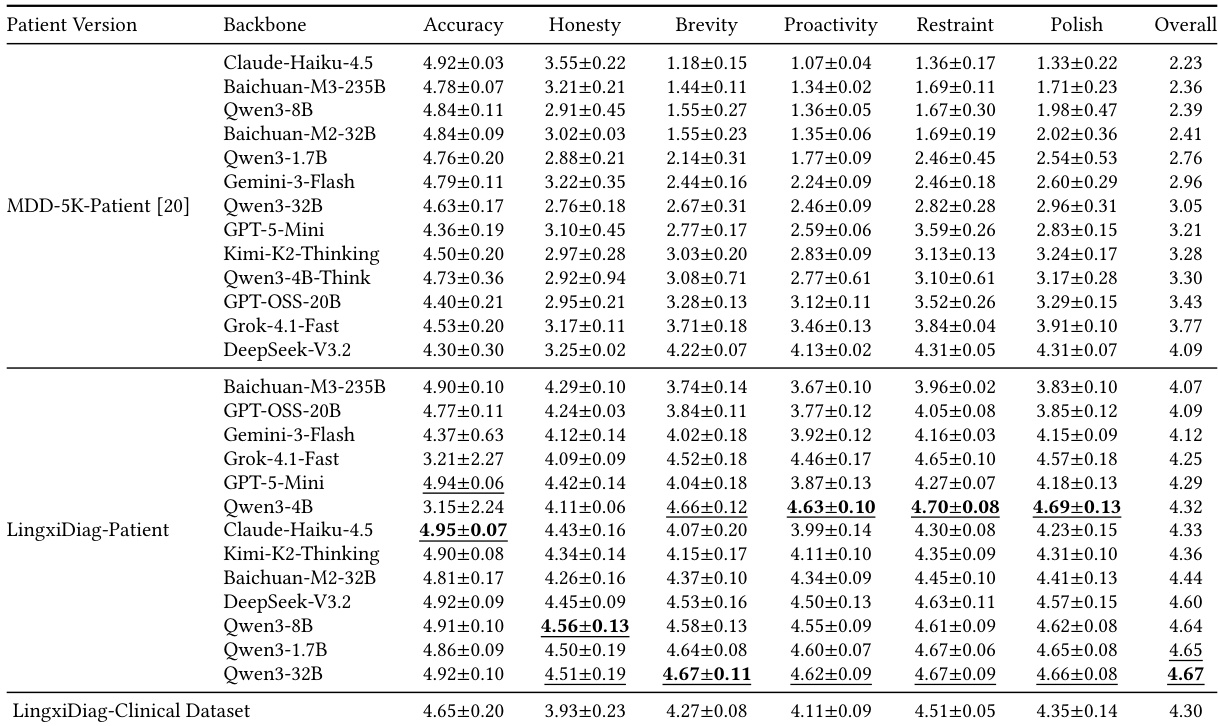
实验在传统机器学习、大语言模型以及合成与真实临床数据集之间评估诊断与对话能力,以评估模型可靠性、咨询策略有效性与数据保真度。研究结果表明,诊断准确率受任务粒度影响显著,二分类保持稳健,而细粒度多类预测暴露了传统算法与大语言模型之间截然不同的架构权衡。结合检索机制的结构化咨询框架持续产生更优结果,表明引导式交互质量比无引导对话指标更可靠地提升诊断性能。此外,合成基准测试成功复制了现实的人口统计学与诊断分布,所提出的患者数据集持续与实际临床交互保持一致,验证了其在稳健模型训练与评估中的效用。