Command Palette
Search for a command to run...
Sartorius: 深度 EDA + 解释 + 模型
摘要
一句话总结
本文作者提出了广义正则化证据深度学习模型,通过引入一类通用的激活函数及对应的证据正则化项,从理论上刻画并克服了主观逻辑框架中固有的、依赖于激活函数的学习停滞现象,从而确保证据更新的连贯性。该研究在四个基准分类问题(MNIST、CIFAR-10、CIFAR-100 和 Tiny-ImageNet)、两个少样本分类问题以及一项盲人脸恢复任务上进行了广泛实验,实证验证了该方法的有效性。
核心贡献
- 该研究从理论上刻画了证据深度学习中由激活函数引发的学习停滞现象,揭示了非负证据约束与特定激活函数如何限制低证据区域的梯度流动。
- 引入了一类广义激活函数及对应的证据正则化项,以缓解该停滞问题,并使模型在不同激活机制下均能实现连贯的证据更新。
- 在 MNIST、CIFAR-10、CIFAR-100、Tiny-ImageNet、两个少样本分类问题及一项盲人脸恢复任务上的实证评估验证了理论分析,并证明了所提出的广义正则化证据模型的有效性。
引言
深度学习模型在各类应用中取得了优异性能,但经常产生过度自信的预测结果,这在医疗诊断等对安全性要求极高的领域中构成风险,因为这些领域必须依赖准确的不确定性量化。证据深度学习提供了一种计算高效的机制,可在无需基于采样方法带来的额外开销下量化细粒度不确定性,然而现有模型在复杂数据集上常因训练动态不稳定而导致性能下降。作者指出,主观逻辑所要求的非负证据参数化与常见激活函数结合时,会形成梯度消失的零证据区域,从而阻碍有效学习。为克服这一停滞问题,作者开发了一种广义正则化证据框架,该框架采用正证据正则化及广泛的激活函数类,使模型在分类与恢复任务中均能实现连贯的证据累积并提升鲁棒性。
方法
作者采用了一种扩展标准分类模型的框架,通过引入证据深度学习来系统性地量化不确定性。证据模型的核心架构始于一个神经网络 FΘ,该网络处理输入 x 以生成 logits o。随后,这些 logits 通过非负激活函数 A 被转换为非负证据值 e=A(o)。这些证据值用于定义狄利克雷参数 α=e+1,该参数为预测多项分布 Mult(y∣p) 上的狄利克雷先验进行参数化。模型的预测 y 通过对潜在参数 p 进行边缘化推导得出,从而使模型能够同时输出预测结果与置信度度量,其不确定性程度由空虚度(vacuity)ν=K/S 刻画,其中 S=∑k=1K(ek+1) 表示狄利克雷强度。
模型通过结合证据损失函数与正则化项进行训练。主要的证据损失函数(如基于平方和或交叉熵的贝叶斯风险)旨在最大化正确类别的证据值并最小化错误类别的证据值。此外,还引入了一项错误证据正则化项,以进一步惩罚错误类别的高证据值。作者分析了该训练过程的梯度动态并发现一个关键问题:当样本被映射到零证据区域(即 e=0)时,标准证据损失函数的梯度会消失,导致模型出现学习停滞行为,无法从此类样本中更新参数。这一现象的发生是因为对于 ReLU、SoftPlus 和指数函数等所有常见激活函数,当 ek→0 时,证据的梯度 ∂ok∂ek 趋近于零,从而向模型参数传递了零梯度信号。
为解决该问题,作者提出了一种新颖的正确证据正则化(CER)项,表示为 Lcor(x,y)=−λcorogt,该正则化项仅在真实标签对应的 logit ogt 为负数时激活。该项的设计目的是在零证据区域提供非消失的梯度信号,具体而言是将样本推离该区域。正则化强度由空虚度 λcor=ν 进行调节,当证据值较低时该强度较大(趋近于 1),并随证据值增加而递减。这确保了正则化在低证据区域发挥最主要的作用,而在高证据样本处逐渐减弱,从而使标准证据损失函数主导这些区域的学习过程。
作者进一步引入了广义正则化证据模型(GRED),该模型将标准证据损失 Levid、错误证据正则化 Linc 以及提出的正确证据正则化 Lcor 整合为单一优化目标。该组合损失确保模型能够从所有训练样本中进行学习,不受其证据水平限制。该框架如图 2 所示,图中表明标准证据训练会将样本推向高证据区域,但零证据区域的样本不会获得任何参数更新。相比之下,GRED 正则化(红色箭头)会主动将这些样本推离零证据区域,从而在整个证据空间内维持连续的学习信号。
作者还分析了不同激活函数对学习过程的影响。研究发现,与 ReLU 和 SoftPlus 相比,指数激活函数 A(ok)=exp(ok) 能为靠近零证据区域的样本提供最大的梯度更新,因为其梯度 ∂ok∂ek=exp(ok) 即使在 logit 为负数时仍保持非零。然而,这可能导致在较大正数 logit 下出现证据值爆炸。为平衡这一问题,作者提出了一种新颖的平移指数线性单元(SELU)激活函数。该激活函数在 logit 为负数时表现类似于指数函数(确保低证据区域具有强梯度),在 logit 为正数时表现为线性函数(防止证据爆炸)。整体训练过程旨在增加正确类别的证据值、降低错误类别的证据值,并确保低证据或零证据区域的样本能够获得有意义的学习信号。
实验
评估工作涵盖标准分类、少样本学习、对抗鲁棒性、分布外检测及图像恢复等多个任务,并应用于多种网络架构,旨在验证传统证据模型的理论局限性以及所提出正确证据正则化的有效性。学习动态与消融实验表明,标准方法在零证据区域面临梯度消失问题,导致学习停滞且对正则化强度高度敏感。泛化性与不确定性分析证明,所提方法通过恢复低证据样本的梯度、使预测准确率与不确定性估计保持一致,并在数据稀缺场景下实现有效的预测过滤,从而持续提升了模型可靠性。总体而言,实验结果证实,正确证据正则化能有效缓解学习停滞,同时在复杂视觉任务中提供稳健的不确定性量化能力。
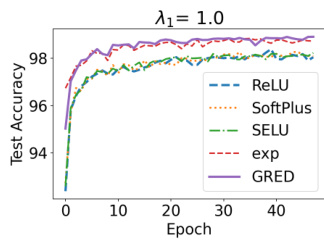
作者评估了不同激活函数及其正则化变体下,正则化强度对模型准确率的影响。结果表明,采用正确证据正则化的模型即使在较高正则化强度下仍能保持性能稳定,而基线模型的性能则显著下降。指数(exp)激活函数始终取得最高准确率,且所提正则化改善了所有激活类型的学习动态。与显著退化的基线模型不同,采用正确证据正则化的模型在不同正则化强度下均保持稳定。在所有正则化强度下,指数激活函数的准确率均优于其他激活函数。正确证据正则化优化了学习动态,使模型能够从所有训练样本(包括低证据或零证据样本)中进行学习。
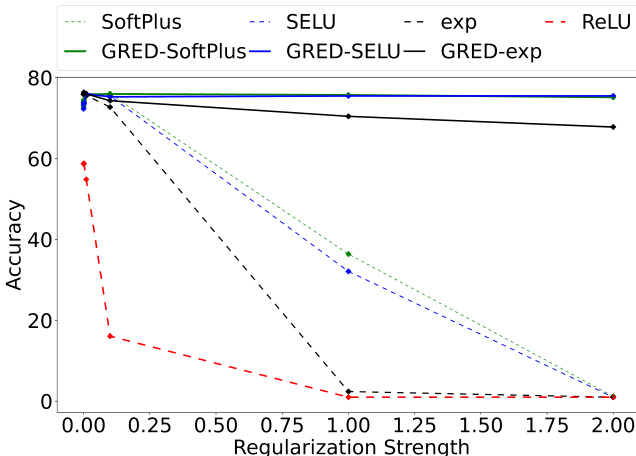
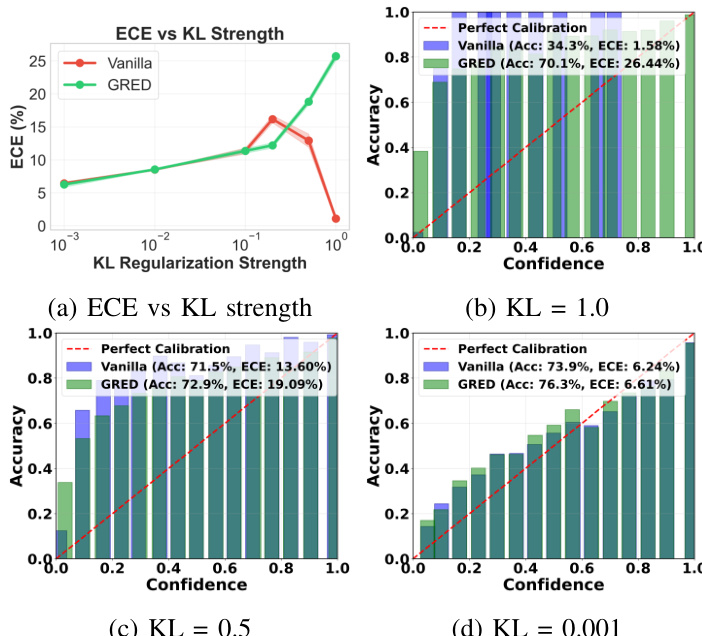
作者在不同基准数据集与设置下评估了所提出的广义正则化证据模型(GRED),证明其相较于基线证据模型在提升泛化能力与不确定性量化方面的优势。结果表明,GRED 在强正则化与对抗条件下仍能保持更优性能,同时提升了分布外检测与少样本学习效果。模型增强的校准特性与不确定性行为在不同数据集与架构中保持一致。GRED 通过启用对零证据区域样本的学习来改善泛化与不确定性量化。与基线模型相比,GRED 在强正则化与对抗条件下维持了更佳的性能。GRED 通过提供更可靠的不确定性估计,增强了分布外检测与少样本学习能力。
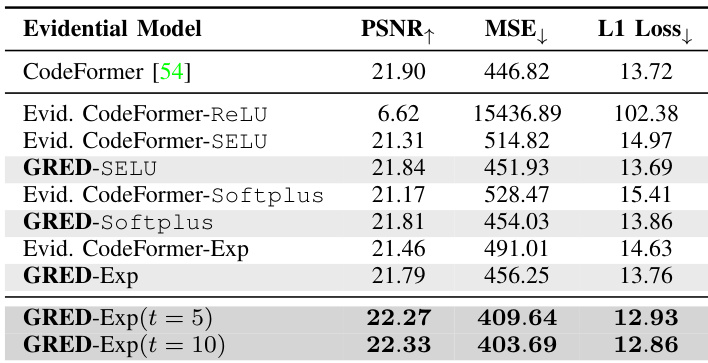
作者基于 CodeFormer 架构在盲人脸恢复任务上评估了证据模型的性能,对比了不同激活函数与正则化策略。结果表明,采用正确证据正则化的所提 GRED-Exp 模型在所有指标上均取得最佳性能,优于基线模型,并展现出改善的泛化能力与不确定性量化效果。在盲人脸恢复任务中,采用正确证据正则化的 GRED-Exp 模型在所有指标上表现最佳。相较于基线证据模型,所提 GRED 框架提升了泛化与不确定性量化能力。不同的激活函数与正则化强度对模型性能产生显著影响,其中指数激活函数结合正确证据正则化取得了更优结果。
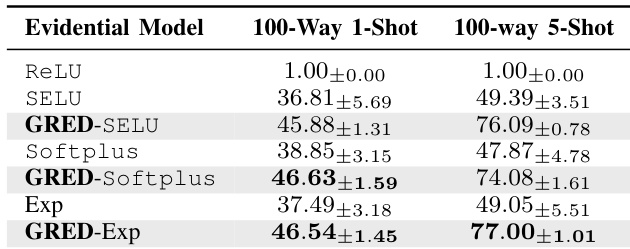
作者评估了证据模型在少样本学习任务中的性能,重点考察正确证据正则化的影响。结果表明,所提 GRED 框架在不同激活函数与少样本设置下均持续优于基线模型,准确率显著提升,尤其在数据稀缺场景下表现突出。与标准证据模型相比,GRED 变体展现出更强的泛化能力与更可靠的不确定性估计。GRED 在所有激活函数与少样本设置下均稳定超越基线证据模型。所提出的正确证据正则化在低数据场景下实现了更好的泛化与更可靠的不确定性估计。GRED 取得了显著的准确率提升,特别是在 100-way 1-shot 设置中,其中 Exp 激活函数表现最佳。
作者评估了不同激活函数及所提正确证据正则化在多个数据集与架构上对模型性能的影响。结果表明,相较于基线证据模型,引入正确证据正则化的所提 GRED 模型持续改善泛化能力与学习动态,尤其在强错误证据正则化条件下表现更为明显。指数(exp)激活函数展现出优异性能,且 GRED 模型在其他模型性能下降时仍能维持稳定训练。采用正确证据正则化的所提 GRED 模型在多种激活函数与数据集上提升了泛化能力。指数激活函数优于其他激活函数,且 GRED 在强错误证据正则化下仍能保持学习稳定。GRED 使模型能够从所有训练样本(包括零证据区域样本)中学习,从而提升整体性能与不确定性可靠性。
实验在涵盖盲人脸恢复与少样本学习等多种基准上评估了引入正确证据正则化的所提 GRED 框架,并系统性地调整了激活函数与正则化强度。这些研究验证了模型在强正则化与数据稀缺条件下,通过有效利用证据极少的训练样本来维持稳定性能并优化学习动态的能力。指数激活函数始终产生更优的准确率,且相较于基线证据模型,所提正则化显著增强了泛化能力、不确定性校准与鲁棒性。总体而言,研究结果证明 GRED 为不同任务与架构下的证据深度学习提供了一种更为可靠且适应性强的框架。