Command Palette
Search for a command to run...
RadImageNet-VQA:用于放射学视觉问答的大规模CT和MRI数据集
RadImageNet-VQA:用于放射学视觉问答的大规模CT和MRI数据集
Leo Butsanets Charles Corbiere Julien Khlaut Pierre Manceron Corentin Dancette
摘要
在本工作中,我们介绍了 RadImageNet-VQA,这是一个旨在推进 CT 和 MRI 检查中放射学视觉问答(Visual Question Answering, VQA)的大规模数据集。现有的医学 VQA 数据集在规模上较为有限,主要以 X 射线成像或生物医学插图为主,且容易受到基于文本捷径(text-based shortcuts)的影响。相比之下,RadImageNet-VQA 由专家精心策划的注释构建而成,包含 750K 张图像及与之配对的 7.5M 个问答(QA)样本。该数据集涵盖了三个关键任务:异常检测、解剖结构识别和病理识别,涉及 8 个解剖区域和 97 种病理类别,并支持开放式、封闭式和多项选择题型。 extensive 实验表明,目前最先进的视觉-语言模型(vision-language models)在细粒度病理识别方面仍面临挑战,尤其是在开放式问答设置中,即使在经过微调后依然如此。仅基于文本的分析进一步揭示,若无图像输入,模型的准确率会降至接近随机水平,这证实了 RadImageNet-VQA 避免了语言捷径问题。完整的数据集和基准测试已公开发布在:https://huggingface.co/datasets/raidium/RadImageNet-VQA。
一句话总结
作者提出了 RadImageNet-VQA,这是一个用于放射学视觉问答的大规模 CT 和 MRI 数据集,包含 750,000 张图像,并配有 750 万个专家策划的问答样本,涵盖异常检测、解剖结构识别和病理识别,涉及 8 个解剖区域和 97 个病理类别。该数据集被证实不存在语言捷径,并揭示了当前最先进的视觉语言模型在细粒度病理识别方面仍然存在困难,尤其是在开放式场景下,即便经过微调也是如此。
核心贡献
- RadImageNet-VQA 提供了一个大规模的放射学 VQA 数据集,包含 750K 张 CT 和 MRI 图像、7.5M 个问答对、三项任务(异常检测、解剖结构识别、病理识别)、八个解剖区域、97 个病理类别,以及开放式、封闭式和多项选择格式。
- 最先进的视觉语言模型在细粒度病理识别方面仍然存在困难,尤其是在开放式场景下,且纯文本分析显示在没有图像输入的情况下准确率接近随机水平,证实了该数据集不存在语言捷径。
- 在 RadImageNet-VQA 上进行微调为所有模型家族带来了显著提升,而经过医学预训练的视觉编码器并未改善下游性能。
引言
作者提出了 RadImageNet-VQA,这是一个用于视觉问答的大规模放射学数据集,将 750,000 张 CT 和 MRI 图像与 750 万个生成的问答样本配对。该资源针对领域内的一个空白:虽然视觉问答为评估视觉语言模型中的临床推理提供了一种可控且可解释的方式,但现有的基准测试缺乏对 CT 和 MRI 等横断面成像模态的充分覆盖。先前的工作主要集中在胸部 X 光片和报告生成上,其自动评估指标与临床正确性的相关性较差,导致在探索细粒度放射学理解方面缺乏可靠的选择。作者的主要贡献是发布了这个涵盖八个解剖区域和 97 种病理的数据集,并进行了系统性评估,结果表明最先进的视觉语言模型能够处理解剖结构和基本的异常检测,但在精确的病理识别方面存在困难,而在该数据上进行微调能带来显著的性能提升。
数据集
数据集描述:RadImageNet-VQA
作者提出了 RadImageNet-VQA,这是一个基于专家策划的 CT 和 MRI 图像构建的大规模放射学视觉问答数据集。它旨在解决现有医学 VQA 基准测试规模有限和解剖覆盖范围狭窄的问题,同时消除让模型在不依赖图像的情况下回答问题的语言捷径。
数据集构成与来源
- 源数据来自 RadImageNet,这是一个由专家标注的医学影像数据集,其中每张图像都带有模态(CT 或 MRI)、身体部位和病理标签。
- 作者仅使用了该资源中的 CT 和 MRI 子集。
- 最终的训练语料库包含大约 750K 张图像和 7.5M 个样本,其中包括 750K 个图像-标题对和 6.75M 个问答对。
- 一个单独的精选基准测试子集包含 1,000 张 CT/MRI 图像和 9,000 个问答对。
各子集的关键细节
- 训练集: 通过将完整的标题生成和 VQA 生成流程应用于整个 RadImageNet 训练分割而创建。它涵盖 8 个解剖区域和 97 个病理类别。
- 基准测试子集: 一个包含 1,000 张图像和 9,000 个问答对的精选评估集,在解剖结构、异常和病理任务上以开放式、封闭式和多项选择格式进行了平衡。
数据使用方式
- 训练集有两个用途:用于医学视觉-文本对齐的放射学标题,以及用于指令微调的 VQA 数据。
- 基准测试子集用于评估最先进的视觉语言模型在三项任务上的表现:
- 解剖结构识别(识别成像区域)
- 异常检测(确定是否存在任何异常发现)
- 病理识别(在解剖背景下区分特定疾病)
处理与构建细节
- 标题生成: 通过从多样化的放射学感知模板中随机采样,将元数据字段(模态、解剖区域、病理类别)转换为结构化的放射学标题,生成诸如“一张显示[病理]的[解剖结构][模态]扫描”的表述。
- VQA 样本生成: 使用特定于任务的问答模板,将每张图像转换为结构化的 VQA 样本。对于每个任务和问题类型,定义了 2 到 7 种语言变体,以防止模型利用文本捷径。
- 封闭式设计: 对于解剖结构和病理问题,会生成正例和负例变体,预期答案为“是”(存在)或“否”(不存在)。这探究了模型在器官或病理不存在时是否会产生幻觉。
- 多项选择干扰项: 对于解剖结构识别,干扰项从数据集中的其他解剖区域采样。对于病理识别,干扰项仅限于来自同一解剖区域的临床合理疾病,防止模型仅通过匹配解剖结构来解决问题。每个病理多项选择题中都包含“未见病理”选项,以减少模型假设病理始终存在的偏差。
实验
RadImageNet-VQA 基准测试使用开放式、封闭式和多项选择题,在 CT 和 MRI 图像上评估视觉语言模型在三项任务上的表现——解剖结构识别、异常检测和病理识别。零样本评估显示,解剖结构识别任务几乎已被解决,但细粒度病理识别仍然是一个严重的瓶颈,尤其是在开放式回答中,即使是最好的模型得分也很低。在放射学数据上进行微调带来了巨大改进,几乎饱和了解剖结构识别和异常检测的性能,但病理鉴别仍然具有挑战性,并且标准视觉编码器的表现与经过医学预训练的编码器相当或更优。纯文本消融实验表明,该数据集有效地消除了语言捷径,迫使模型依赖视觉证据而非文本先验。
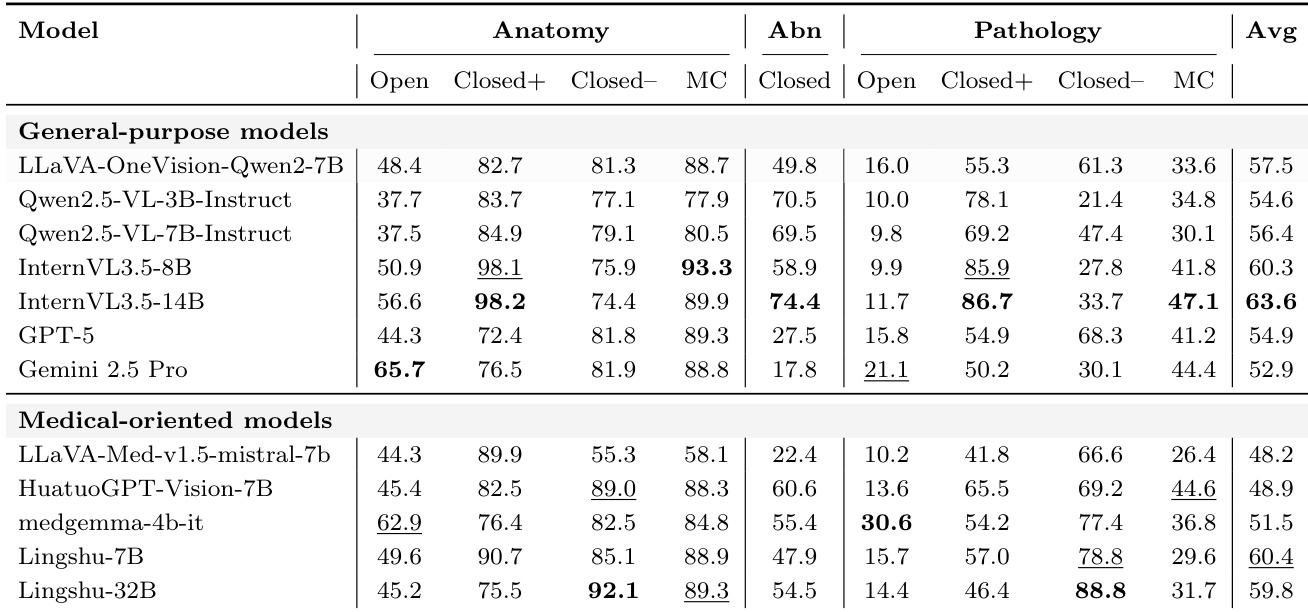
作者在放射学视觉问答基准测试上评估了最先进的通用和面向医学的视觉语言模型。结果表明,虽然解剖结构识别在很大程度上已被解决,但细粒度的病理识别仍然是一个显著的瓶颈,特别是对于开放式问题。通用模型通常比面向医学的变体获得更高的总体准确率,尽管后者在开放式病理任务中显示出特定优势。解剖结构识别得分在不同模型间始终很高,尤其是在多项选择和封闭式格式中,而开放式病理识别的性能最低。通用模型在平均准确率上领先,并在异常检测和封闭式病理问题中表现出色,这表明广泛的预训练提供了坚实的基础。面向医学的模型在开放式病理问题上表现出卓越的性能,但并未在所有任务上持续超越通用模型。
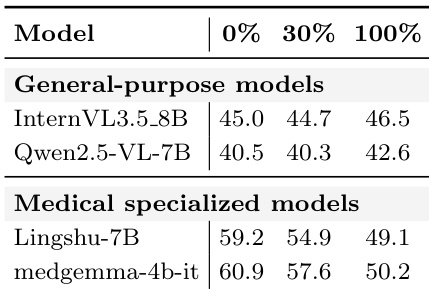
该表比较了通用模型和医学专用模型在 0%、30% 和 100% 条件下的表现。医学专用模型在 0% 时最初显示出比通用模型显著更高的值,但这些值随着百分比的增加而下降。两种模型类型之间的性能差距在 100% 时缩小,表明在该条件下能力趋于一致。像 medgemma-4b-it 和 Lingshu-7B 这样的医学专用模型在 0% 时以高于通用模型的值起步。随着百分比增加到 100%,医学专用模型的值呈现持续下降趋势。通用模型在所有条件下保持相对稳定的值,导致与医学模型在 100% 时的差距缩小。
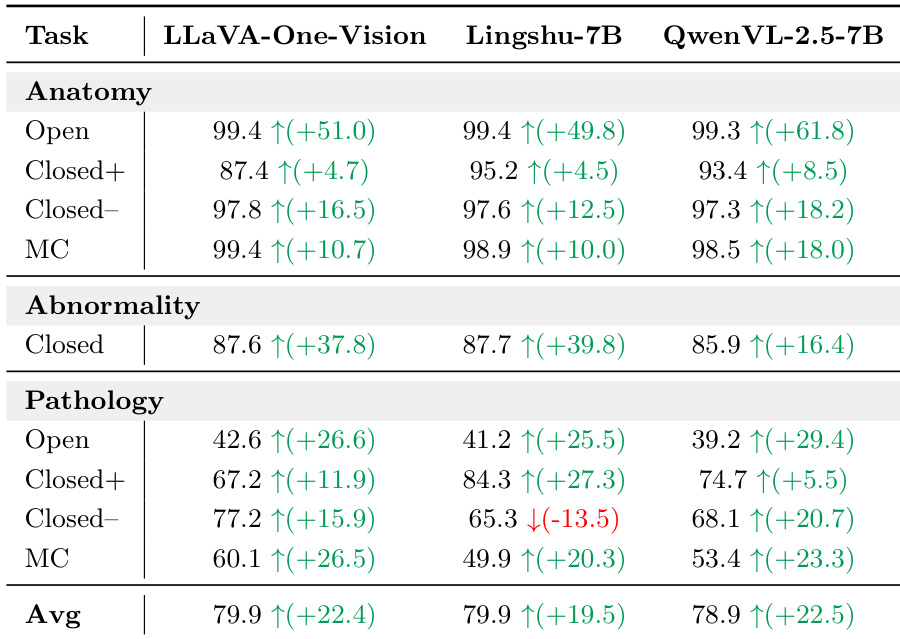
作者在放射学语料库上微调了多个视觉语言模型,并观察到所有架构的性能均获得持续提升。解剖结构识别在训练后达到接近饱和的水平,而异常检测显示出显著的相对改进。然而,病理识别仍然是主要瓶颈,即使在微调后也仅能达到较低的准确率。微调在大多数评估模型和任务类别中带来了显著的准确率提升。解剖结构识别任务在训练后几乎被解决,模型在所有问题格式中都达到了非常高的准确率。病理识别仍然具有挑战性,尽管微调带来了增益,但其性能在三项任务中仍然是最低的。
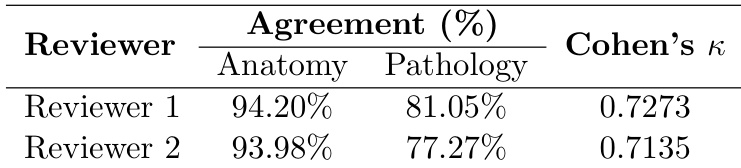
作者通过将 LLM-as-a-judge 评估框架与人工标注进行比较,验证了其在开放式回答中的可靠性。结果表明,自动化系统与人工审核员之间存在高度一致性,支持将其用于基准测试。值得注意的是,解剖结构识别任务的一致性比病理识别更强,反映了任务难度的差异。人工审核员在解剖结构和病理类别上与 LLM judge 表现出高度一致性。与更具挑战性的病理识别相比,自动化评估在解剖结构识别上显示出更高的一致性。Cohen's kappa 分数表明了高度的可靠性,验证了 LLM-as-a-judge 方法在开放式评估中的有效性。
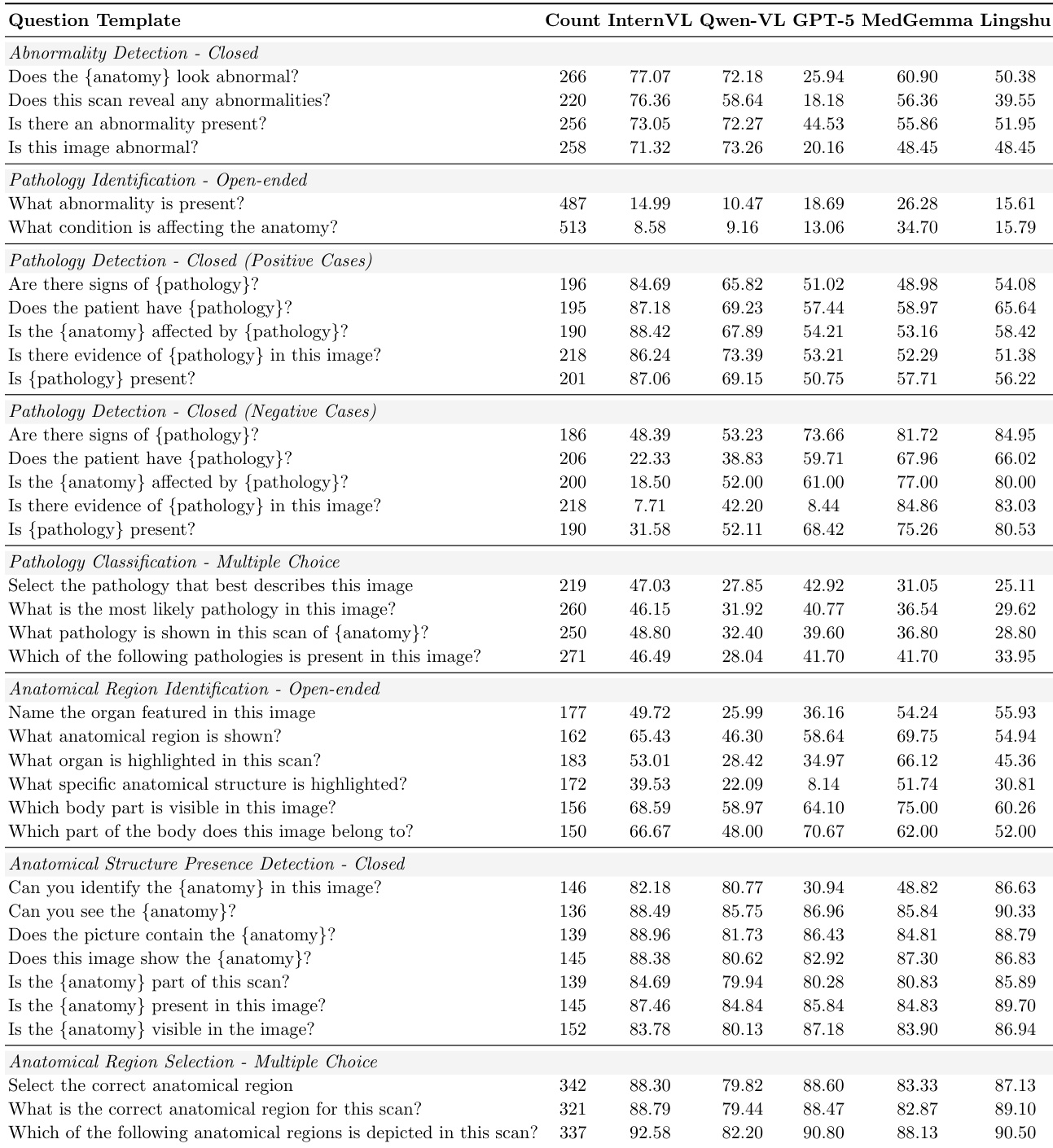
作者详细列出了不同问题模板和放射学任务下的零样本准确率。数据证实,对于大多数模型,解剖结构识别和结构存在检测的准确率非常高,尤其是在多项选择格式中。相比之下,开放式病理识别被证明极其困难,所有模型得分都很低,尽管像 MedGemma 这样的医学专用模型显示出微弱优势。像 InternVL 这样的通用模型在阳性病例的封闭式病理任务中通常优于其他模型,而 GPT-5 在异常检测问题上表现出显著的低性能。解剖区域选择和结构存在检测在不同模型间始终产生高准确率,表明这些任务几乎已被解决。开放式病理识别仍然是最具挑战性的任务,所有评估模型的准确率得分仍然非常低。像 InternVL 这样的通用模型在阳性病理检测案例中取得了高准确率,而面向医学的模型在阴性案例上表现显著更好。
作者在涵盖解剖结构、异常检测和病理任务的放射学视觉问答基准测试上,以多项选择、封闭式和开放式格式评估了通用和医学专用视觉语言模型。解剖结构识别在所有模型中几乎已被解决,而细粒度的病理识别,尤其是在开放式场景下,即使在微调后仍然是主要瓶颈。通用模型通常获得更高的总体准确率,但面向医学的模型在开放式病理问题和低数据情况下表现出特定优势,尽管其优势随着训练数据的增加而缩小。LLM-as-a-judge 评估协议经过人工标注验证,显示出高度一致性,特别是在解剖结构任务上,证实了自动化开放式评估的可靠性。