Command Palette
Search for a command to run...
高效地以每次一个 D4RT 的方式重建动态场景
高效地以每次一个 D4RT 的方式重建动态场景
摘要
从视频中理解并重构动态场景的复杂几何结构与运动,依然是计算机视觉领域的一项严峻挑战。本文介绍了 D4RT,这是一种简单而强大的前馈模型,旨在高效解决这一任务。D4RT 采用统一的 Transformer 架构,能够从单段视频中联合推断深度、时空对应关系以及完整的相机参数。其核心创新在于一种新颖的查询机制(querying mechanism),该机制避免了密集逐帧解码带来的巨大计算开销,也简化了管理多个任务特定解码器(task-specific decoders)的复杂性。通过其解码接口,模型能够独立且灵活地探查空间中任意点在任意时刻的三维位置。最终,这是一种轻量级且具有高度可扩展性的方法,能够实现极为高效的训练与推理。我们证明,该方法在广泛的 4D 重建任务中均优于先前方法,树立了新的最先进水平(state of the art)。有关动态结果的演示,请访问项目网页。
一句话总结
D4RT 是一种前馈统一 transformer 模型,通过一种新颖的查询机制,联合推断深度、时空对应关系和完整相机参数,从而从单视频高效重建动态场景。该机制避免了密集的逐帧解码,支持对时空任意点进行独立灵活的探测,同时在广泛的 4D 重建任务中树立了新的最先进水平。
核心贡献
- 本文介绍了 D4RT,这是一种利用统一 transformer 架构从前馈模型中从单视频联合推断深度、时空对应关系和相机参数的模型。该设计将此前需要独立头部或多阶段流水线的任务统一在单一架构内。
- 一种新颖的查询机制使模型能够独立探测时空任意点的 3D 位置,而无需依赖密集的逐帧解码。这种灵活的参数化避免了计算瓶颈,并允许推理规模随重建点数量线性扩展。
- 实验表明,该方法通过在包括深度和点跟踪在内的广泛 4D 重建任务中超越先前方法,树立了新的最先进水平。视觉比较表明,该模型成功重建了完整的 4D 表示,包括其他方法出现失败案例或间隙的所有像素。
引言
从视频中理解和重建动态场景的几何与运动是计算机视觉中的关键挑战。现有方法通常依赖碎片化的流水线或独立的解码器,这些方法需要昂贵的优化,且无法有效处理动态区域。作者介绍了 D4RT,这是一种利用 transformer 架构联合推断深度、时空对应关系和相机参数的统一前馈模型。其核心创新是一种查询机制,通过允许对时空任意点进行独立探测,避免了密集的逐帧解码。该设计实现了高效的训练和推理,同时为 4D 重建任务树立了新的最先进水平。
方法
D4RT 框架建立在受 Scene Representation Transformers 启发的简化编码器 - 解码器架构之上。如下方图所示,系统通过强大的编码器处理输入视频序列,生成紧凑的全局场景表示。该表示捕获所有帧之间的密集对应关系并编码场景的时间流。轻量级解码器随后查询该表示以预测特定时空坐标的 3D 点位置。
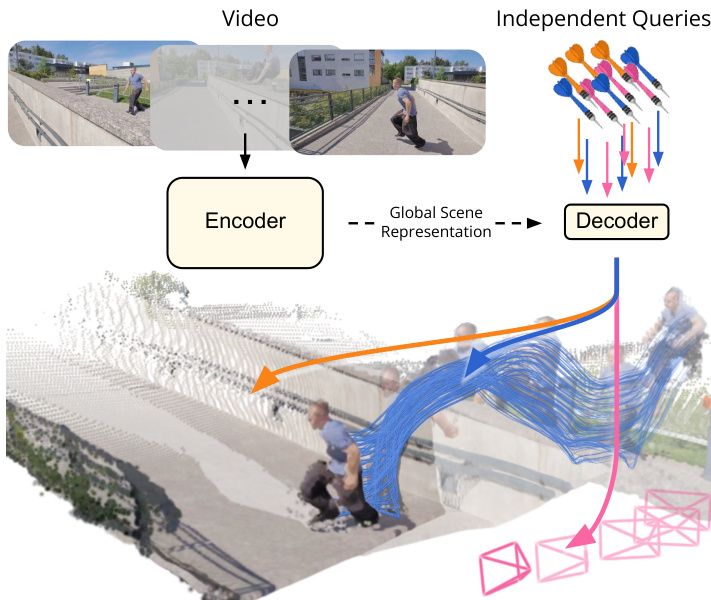
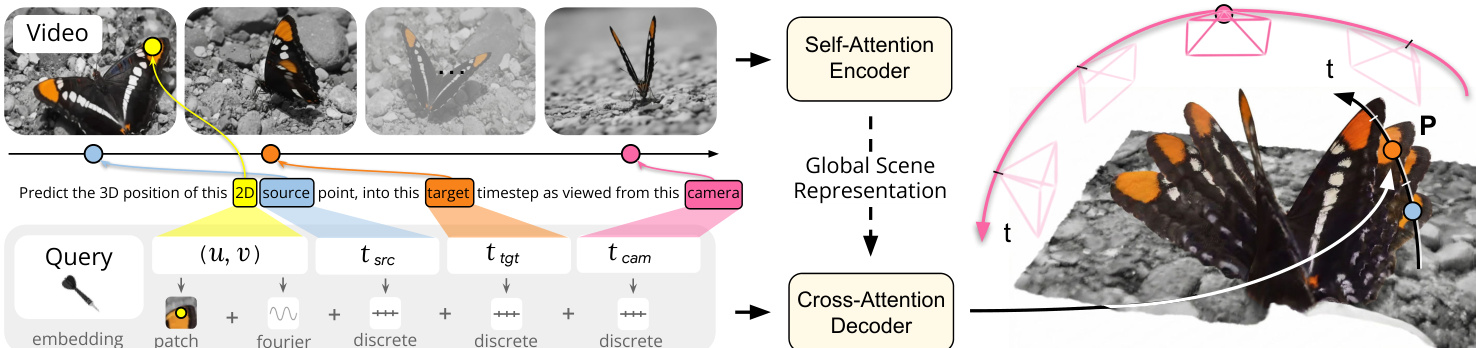
该方法的核心依赖于一个灵活的查询接口,允许解耦空间和时间。作者定义了一个查询 q=(u,v,tsrc,ttgt,tcam),其中 (u,v) 表示源帧 tsrc 中点的归一化 2D 坐标。参数 ttgt 和 tcam 分别表示预测的目标时间步和参考相机坐标系。该公式使模型能够预测相对于任意相机视图的任意目标时间点的 3D 点位置。参考下图以了解这些查询组件如何映射到视频帧和最终的 3D 重建。
关于具体模型架构,编码器基于 Vision Transformer,具有交错的本地图帧级和全局自注意力层。为了支持任意宽高比,输入视频被调整为固定的正方形分辨率,原始宽高比作为单独的 token 嵌入。解码器作为一个小型交叉注意力 transformer 运行,其中每个查询独立处理。查询 token 通过结合 2D 坐标的傅里叶特征嵌入、学习到的离散时间步嵌入和本地像素块嵌入来构建。架构细节,包括 N 个编码器块和 M 个解码器块,如下方图所示。
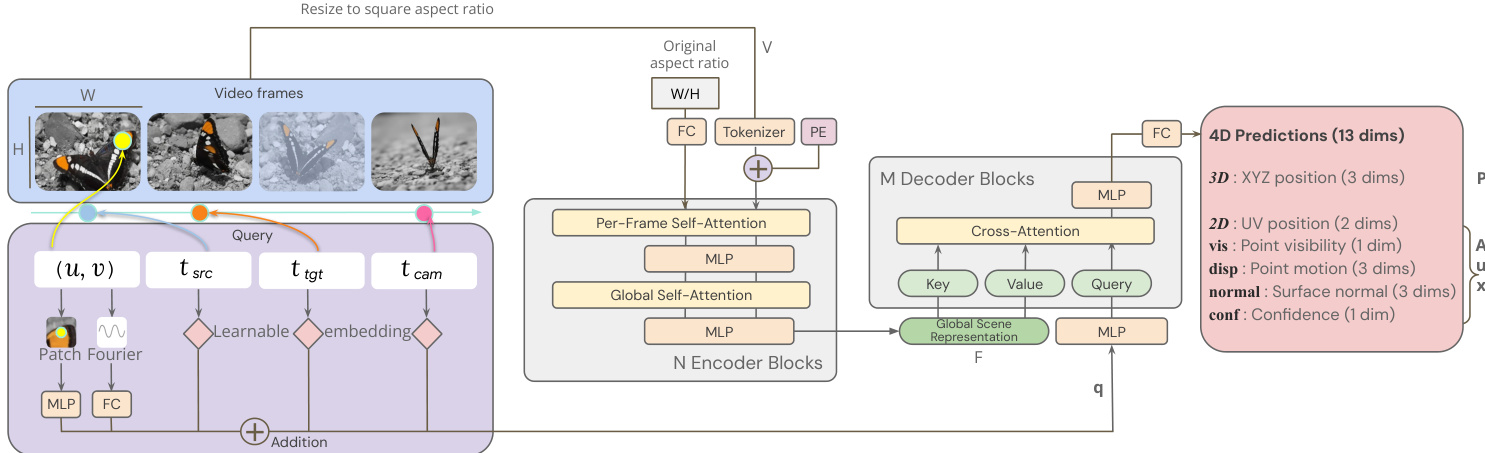
解码器的输出是一个包含 13 维的 4D 预测向量。这包括 3D XYZ 位置、2D UV 位置、点可见性、点运动向量、表面法线和置信度分数。模型通过最小化复合损失函数 L 进行端到端训练,该函数是在采样查询批次上计算的特定任务损失的加权和。主要监督来自归一化 3D 点位置的 L1 损失,以及用于 2D 坐标、表面法线、可见性和运动的辅助损失。为了高效计算所有像素的密集对应关系,作者采用了一种利用时空冗余的占用网格算法。这种方法避免了朴素 O(T2HW) 查询的计算成本,仅从未访问像素启动新轨迹。
实验
评估在 4D 重建、跟踪和纯重建任务中将 D4RT 与最近的先进方法进行了基准测试,使用了多样化的真实世界和合成数据集。定性和定量比较表明,D4RT 通过在统一参考帧内跟踪所有动态像素实现了稳健的 4D 表示,同时在深度估计和相机姿态任务中提供了更高的精度,吞吐量显著高于先前方法。此外,消融研究证实,局部 RGB 块和预训练编码器等架构组件对于保留详细特征和扩展性能至关重要。
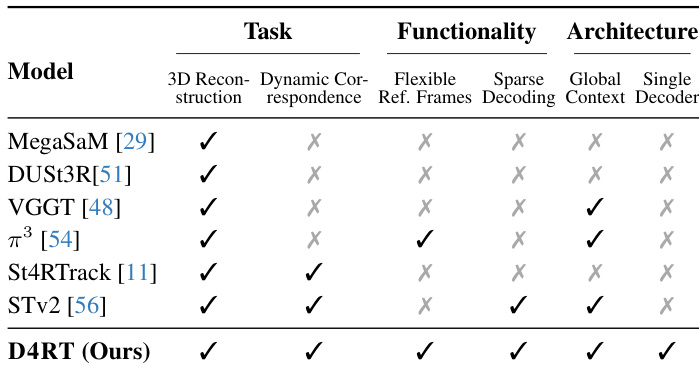
作者将 D4RT 与各种任务和架构特征方面的最近最先进方法进行了比较。虽然其他模型在 3D 重建或动态对应等特定领域表现出色,但 D4RT 是唯一结合了所有列出功能的方法。这包括在单一解码器架构内支持灵活参考帧、稀疏解码和全局上下文。D4RT 是唯一具有单一解码器架构同时保持全局上下文感知能力的模型。所提出的方法独特地结合了灵活参考帧与稀疏解码能力。D4RT 是唯一列出的满足跨任务、功能和架构列所有功能标准的方法。
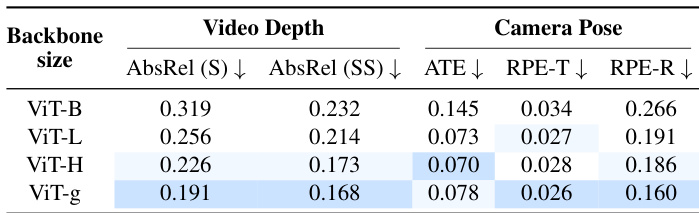
作者调查了扩大 ViT 编码器骨干网络大小对视频深度和相机姿态估计性能的影响。结果展示了一致的趋势,即更大的骨干网络产生更高的精度,最大模型变体在所有指标上实现了最低的错误率。增加骨干网络大小一致降低了视频深度估计的错误率。相机姿态精度随着骨干网络的增大而提高,显示出减少的平移和旋转误差。最大的骨干网络变体在所有报告的指标上实现了最佳性能。
作者将他们的模型与点云重建和视频深度估计任务上的最近最先进方法进行了基准测试。结果表明,该方法在多个数据集(包括 Sintel、ScanNet 和 KITTI)上始终实现最低的错误率。这表明在重建动态场景中的 3D 几何和估计深度方面具有更优越的性能。所提出的方法在 Sintel 和 ScanNet 基准测试上实现了优于竞争模型的点云重建最佳精度。在视频深度估计任务中,该模型在具有挑战性的 Sintel 数据集上的仅缩放和缩放及平移对齐设置下均优于所有基线。性能在 ScanNet 和 KITTI 等多样化数据集上保持稳健,该方法始终记录比先前最先进方法更低的错误指标。

作者调查了查询密度和块保真度如何影响高分辨率解码能力。他们比较了在解码期间变化的输出分辨率和本地 RGB 块分辨率的配置。结果表明,与基线或朴素的高分辨率查询相比,提取高分辨率本地块会产生最清晰的边界和最佳的整体精度。使用高分辨率本地 RGB 块在缩放和缩放及平移对齐下实现了最低的边界错误率。结合局部外观信息显著提高了相对于无块基线配置的性能。在原始分辨率上进行朴素密集查询在边界精度上表现不如使用相同分辨率的高保真块。

该实验在静态室内场景和动态室外场景上将相机姿态估计性能与最近最先进方法进行了基准测试。结果表明,所提出的模型始终实现更高的精度,特别是在最小化平移误差和最大化不同环境间的姿态一致性方面。所提出的方法在 Sintel 和 ScanNet 数据集上实现了最低的绝对平移误差。ScanNet 数据集上的相对平移精度优于所有竞争基线。该模型在 Re10K 基准测试中获得了最高的姿态精度分数。
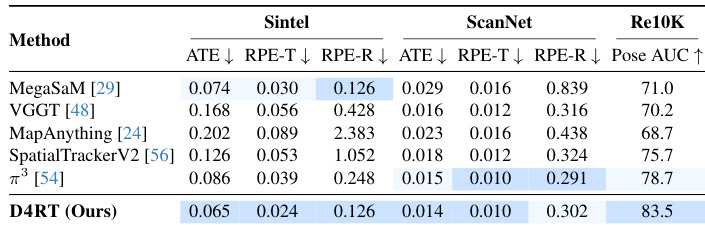
作者将所提出的方法与包括点云重建、视频深度估计和相机姿态估计在内的任务中的最近最先进方法进行了基准测试。对模型扩展和解码配置的研究表明,更大的骨干网络和高分辨率本地块始终带来更高的精度和更清晰的边界。值得注意的是,该方法独特地结合了灵活参考帧与稀疏解码,从而在多样化的静态和动态环境中实现优越性能。