Command Palette
Search for a command to run...
使用 Open WebUI 一键部署 Mistral Large 2407 123B
摘要
一句话总结
作者通过实证研究评估了指令微调的 Mistral-Small 3 24B 和推理增强的 Qwen 2.5 32B 在生物医学文本简化任务中的表现,利用包含 21 项指标的关联分析框架,揭示了两者在可读性与准确性策略上的差异:Mistral 采用温和的词汇简化策略,在保持与人类相当的话语保真度(BERTScore: 0.91)的同时持续提升可读性;而 Qwen 虽提升了可读性,但 BERTScore 降至 0.89,且可读性与准确性之间存在明显脱节。
核心贡献
- 针对指令微调的 Mistral-Small 3 24B 与推理增强的 Qwen 2.5 32B 模型,仅通过提示词进行简化策略的实证评估,为生物医学文本简化建立了更新的实用基线。评估指出,在保持复杂摘要语义等价性的过程中,词汇简化而非句法重构是主要难点。
- 指令微调的 Mistral-Small 3 24B 模型在提升可读性方面表现更优,同时保持了话语保真度(BERTScore 为 0.91),该结果在统计学上与人类水平相当。该模型在不同温度配置下均表现出良好的鲁棒性,这与推理增强的 Qwen 2.5 32B 模型难以平衡可读性提升与事实准确性形成对比。
- 对 21 项可读性与准确性指标进行全面的关联分析,阐明了它们的功能关系,并揭示了自动化简化评估中的高度冗余性。该评估量化了可读性提升与内容保留之间的固有张力,为生物医学语言处理系统的具体适配需求提供了依据。
引言
作者针对使复杂生物医学内容向公众普及的迫切需求展开研究,因为患者资料和数字健康信息可读性差会助长错误信息并削弱知情决策能力。尽管大语言模型为自动化文本简化提供了可扩展的解决方案,但先前研究一致指出可读性提升与事实准确性之间存在关键权衡,领域适配方法往往产生矛盾结果且通常无法超越通用模型。为在不依赖难以获取的微调数据的情况下评估这一平衡,作者使用生物医学摘要对两款中型通用大语言模型与人类专家进行了基准测试。研究将词汇简化识别为主要技术难点,证明了指令微调模型在最大化可读性的同时可实现人类级别的话语保真度,并对自动化简化流程中可读性与准确性指标的关联进行了严谨分析。
数据集

- 数据集构成与来源: 作者采用由公共基准与自定义领域集合组成的双部分数据集。主要基准包含 750 条生物医学摘要及其与 Attal 等人(2023)提供的专家人类简化版本。自定义子集包含随机抽样的摘要,聚焦于中医药与肿瘤学领域。
- 关键子集详情: 基准摘要经过精心筛选,涵盖 75 个医学主题,作为对照队列;配对的人类文本则作为参考目标。自定义子集未经筛选,专门针对具有高术语密度且对公共卫生应用具有重要临床相关性的领域。
- 数据使用与处理: 配对摘要与人类简化文本用于驱动模型可读性与准确性的评估。作者将对照集作为基线,将人类文本作为事实标准,以比较不同语言模型在通用与专业领域简化任务中的表现差异。
- 元数据与结构化处理: 简化输出通过 Pydantic 模式进行标准化,记录原始短语、转换后短语、分类的变更类型(包括术语替换、解释、抽象、省略或无变化)以及不超过 30 字的简明理由。该结构化元数据支持对模型简化策略的系统性追踪与分析。
方法
作者利用两种不同的大语言模型架构进行文本简化:Mistral-Small 3 24B 与 Qwen 2.5 32B。Mistral-Small 3 24B 模型经过指令微调,优先保证任务保真度,确保精确执行简化任务。相比之下,Qwen 2.5 32B 模型设计包含推理增强机制,以处理复杂问题解决场景,适合处理需要细致处理的简化任务。为评估鲁棒性,每个模型均配置两种温度设置:严格配置(T=0.2)产生更确定性的输出,灵活配置(T=0.4)引入更高的随机性。这些配置生成了四种基于大语言模型的简化流程,辅以人类专家简化流程,共同构成研究中的五种纯文本适配系统。
实验
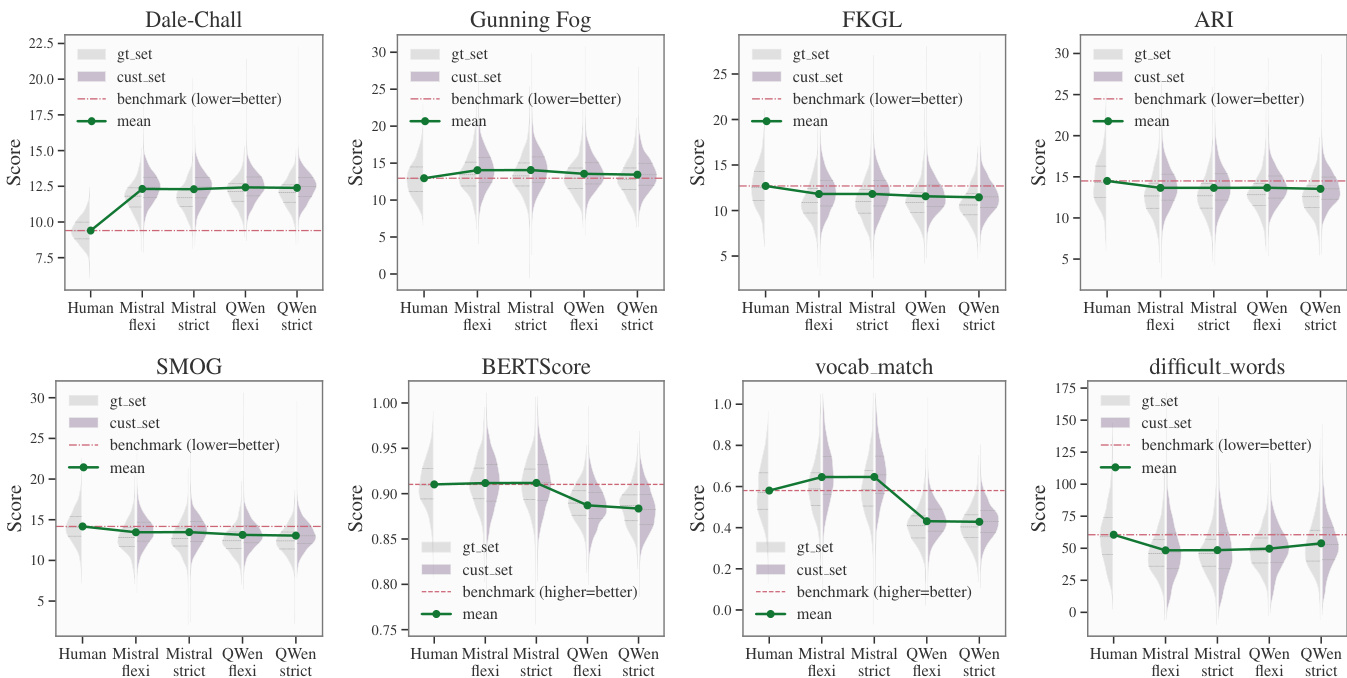
本研究通过基准测试系统表现、可读性、语义保真度与安全性,评估了指令微调的 Mistral-Small 3 24B 与推理增强的 Qwen 2.5 32B 在零样本生物医学文本简化方面的能力,并与人类专家进行对比。实验验证了各模型如何在词汇简化与意义保留之间进行权衡,结果表明两者均成功掌握了句法重构,但在词汇处理上存在根本差异。Mistral 采用保守策略,有选择地保留专业术语,从而在有效平衡可读性与准确性的同时维持人类级别的语义保真度。相反,Qwen 通过激进替换与概念扩展采取更探索性的方法,虽提升了可读性,但引入了可测量的语义退化风险,最终凸显了词汇控制是自动化简化的核心难点。
作者针对生物医学文本简化任务比较了两种大语言模型,重点关注可读性与准确性。Mistral 在系统表现上持续优于 QWen,并达到人类级别的话语保真度,而 QWen 在某些指标上显示更高的可读性,但语义保留能力较弱。分析揭示了截然不同的操作策略:Mistral 采用保守方法,平衡简化与意义保留;QWen 则使用更探索性的方法,以牺牲语义完整性为代价优先提升可读性。Mistral 实现了优于 QWen 的系统表现与人类级话语保真度。QWen 在多项指标上获得更高可读性,但语义保留较弱,且可读性与准确性之间存在脱节。Mistral 采用保守策略,在简化文本的同时保留专业词汇,而 QWen 使用概念扩展,存在语义退化风险。
作者针对生物医学文本简化任务比较了两种大语言模型,评估其在可读性、准确性与内容安全性方面的表现。结果显示,指令微调模型在可读性与语义保真度之间实现了更强的对齐,而推理增强模型生成了更易读的文本,但对意义保留的风险更大。与人类基准相比,两款模型在大多数指标上均展现出更优的可读性,但在处理词汇复杂性与句法结构方面存在差异。指令微调模型在可读性与语义准确性之间实现了更好的对齐,表现与人类基准相当。推理增强模型生成了更易读的输出,但显示出可读性提升与语义保留之间的脱节。两款模型在大多数指标上改善了可读性,在难词处理与词汇保留方面观察到显著差异。
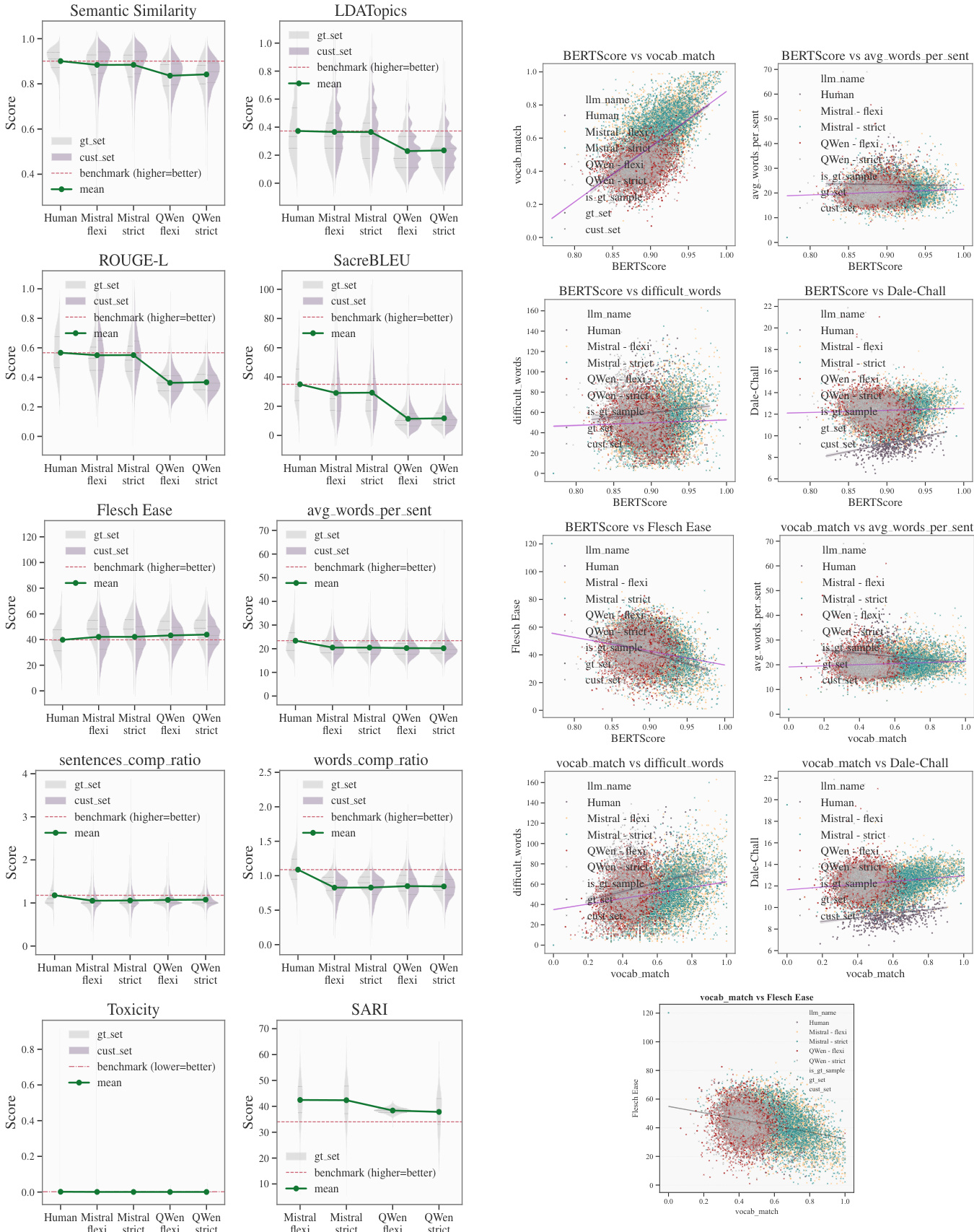
作者针对生物医学文本简化任务比较了 Mistral 与 Qwen 两种大语言模型,重点关注可读性与准确性。Mistral 在各项指标上展现出更一致的表现,在语义保真度上达到与人类基准相当的水平,并在可读性与准确性之间保持了更好的平衡。Qwen 在多项指标上获得更高的可读性分数,但可读性与准确性之间的相关性较弱,暗示了语义保留方面的权衡。与人类专家相比,两款模型均减少了难词使用,但 Mistral 保留了更多专业词汇,表明其采用了更保守的策略。与 Qwen 相比,Mistral 实现了人类级别的语义保真度,并在可读性与准确性之间保持了更好的平衡。Qwen 在多项指标上获得更高的可读性分数,但可读性与准确性之间的相关性较弱,暗示了潜在的语义退化。与人类专家相比,两款模型均减少了难词使用,但 Mistral 保留了更多专业词汇,表明其采用了更保守的简化策略。
作者针对生物医学文本简化任务比较了 Mistral 与 Qwen 两种大语言模型,评估其在可读性、准确性与内容安全性方面的表现。Mistral 展现出更一致且接近人类水平的简化效果,在系统表现上得分更高,且可读性与语义保真度之间的对齐程度更好;而 Qwen 生成了更易读的文本,但语义退化风险更大。两款模型在大多数可读性指标上均表现出稳健的性能,但在处理词汇复杂性与词汇保留方面存在差异。与 Qwen 相比,Mistral 实现了更高的系统表现,且可读性与准确性之间的对齐程度更好。Qwen 生成了更易读的文本,但在词汇保留与 BERTScore 方面显示出更大的语义退化风险。两款模型在可读性指标上均表现出稳健的性能,Mistral 在不同温度设置下展现出更一致的结果。
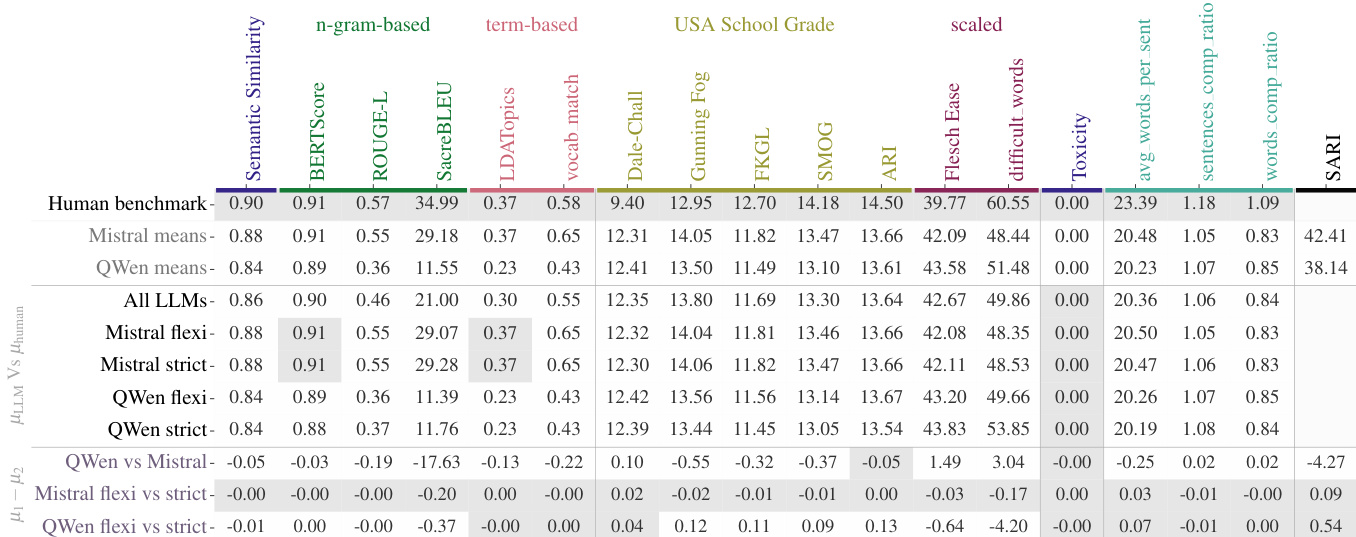
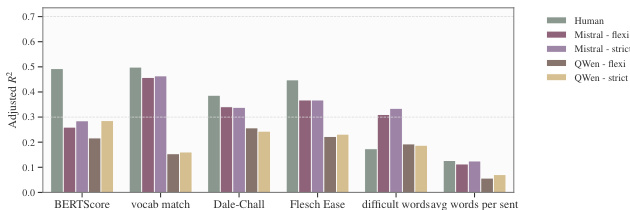
作者针对生物医学文本简化任务比较了两种大语言模型,分析其在可读性与准确性指标上的表现。Mistral 采用保守策略,平衡词汇简化与语义保真度,达到了与人类专家相当的性能水平。相比之下,QWen 采取了更探索性的策略,虽提升了可读性,但可读性与准确性指标之间的对齐程度较弱。Mistral 在 BERTScore 与词汇匹配上达到人类水平表现,表明其具有强大的语义保留能力。QWen 在大多数指标上展现出更优的可读性,但可读性与准确性之间的相关性较弱,暗示优化策略存在脱节。Mistral 的策略在不同温度设置下更为一致,而 QWen 对配置变化较为敏感,影响了其性能稳定性。
实验通过评估可读性、语义准确性与整体系统表现,对 Mistral 与 Qwen 两款大语言模型在生物医学文本简化方面的能力进行了检验。定性分析表明,Mistral 采用保守策略,有效平衡了词汇简化与意义保留,实现了人类级别的话语保真度,并在不同设置下保持结果一致。相反,Qwen 采取更探索性的方法,提升了表面可读性,但牺牲了语义完整性与性能稳定性。最终研究结果证实,在流畅性与语义保留之间保持谨慎平衡,对于可靠的生物医学文本简化至关重要。