Command Palette
Search for a command to run...
自适应数据飞轮:将MAPE控制循环应用于AI代理改进
自适应数据飞轮:将MAPE控制循环应用于AI代理改进
基于 OpenManus + QwQ-32B 实现 AI Agent
摘要
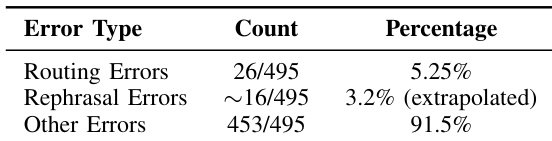
企业级AI代理必须持续适应,以保持准确性、降低延迟并符合用户需求。我们展示了在NVInfo AI中数据飞轮的实际应用,NVInfo AI是英伟达(NVIDIA)的混合专家(MoE)知识助手,服务于超过30,000名员工。通过实施基于MAPE驱动的数据飞轮,我们构建了一个闭环系统,系统地解决检索增强生成(RAG)管道中的故障,并实现持续学习。在部署后的3个月期间,我们监控了反馈并收集了495个负样本。分析揭示了两种主要故障模式:路由错误(5.25%)和查询改写错误(3.2%)。利用英伟达NeMo微服务,我们通过微调实施了有针对性的改进。在路由方面,我们用经过微调的8B模型替换了Llama 3.1 70B模型,实现了96%的准确率,模型规模减少了10倍,延迟降低了70%。在查询改写方面,微调使准确率提高了3.7%,延迟降低了40%。我们的方法证明了,当人类在环(HITL)反馈被结构化地整合到数据飞轮中时,如何将企业级AI代理转变为自我改进的系统。关键经验包括:如何在用户反馈有限的情况下确保代理的鲁棒性、如何应对隐私限制以及在生产环境中执行分阶段部署。这项工作为构建能够在大规模真实世界使用中学习的健壮、自适应的企业级AI代理提供了可重复的蓝图。
一句话总结
通过利用 NVIDIA NeMo 微服务实现基于 MAPE 驱动的数据飞轮,作者对 NVInfo AI 知识助手的路由与查询改写组件进行了微调。该研究将 Llama 3.1 70B 模型替换为 8B 变体,在通过三个月内收集的结构化人类反馈提升查询改写准确率 3.7% 并降低其延迟 40% 的同时,实现了 96% 的路由准确率、模型体积缩减 10 倍以及延迟降低 70% 的效果。
核心贡献
- 本文提出了一种基于 MAPE 驱动的数据飞轮框架,该框架在企业 AI Agent 中实现了用于持续学习的闭环系统。该架构将用户反馈系统性地路由至优化管道,以支持系统的渐进式演进。
- 对 495 个部署后反馈样本的实证分析表明,路由错误(5.25%)和查询改写不准确(3.2%)是主要的故障模式。这些发现为优先进行针对性组件优化建立了数据驱动的基准。
- 一种利用 NVIDIA NeMo 微服务的模块化实现蓝图执行了参数高效微调,以解决已识别的管道故障。针对性优化将 Llama 3.1 70B 模型替换为 8B 变体,在实现 96% 路由准确率的同时,将模型体积缩减 10 倍、延迟降低 70%;查询改写准确率提升了 3.7%,延迟降低了 40%。
引言
针对企业在部署后用户意图与领域数据不断演进的背景下,企业 AI Agent 必须维持准确性与效率的关键需求,作者进行了深入研究。现有生产系统通常依赖静态架构,将反馈与模型优化隔离,导致性能下降与高延迟,且无法实现成本效益显著的持续学习。作者引入了一种基于 MAPE 驱动的数据飞轮框架,在 NVIDIA 的 NVInfo AI 助手内实现了闭环管道,用于系统性地识别故障模式并应用针对性的参数高效微调。通过将人类反馈与自动化监控及执行相结合,该方法使系统能够自我纠正路由与查询改写错误,为构建基于实际使用场景渐进式改进的稳健、自适应 Agent 提供了可扩展的蓝图。
数据集
-
数据集构成与来源: 作者通过整合生产环境中的用户反馈、领域专家修正记录以及企业内部文档来构建训练语料。主要来源包括点踩反馈循环、SharePoint 专家系统日志,以及涵盖福利、IT 政策与组织信息的公司知识库。
-
子集详情:
- 路由错误修复: 最终集合包含 685 个去重样本,源自 729 条原始记录与 32 条经 SME 验证的修正。LLM-as-a-Judge 管道最初标记了 140 个潜在问题,经人工验证后缩减为 32 个高置信度错误。
- 改写错误修复: 该子集由 5,000 个合成样本组成,这些样本源自 250 个经人工审核的反馈实例。作者将 10 个存在问题查询提炼为 4 个具有代表性的少样本示例,以此指导合成扩展过程。
- 回归评估集: 精心整理的约 300 条查询集合,涵盖公司政策、福利、节假日与 IT 支持。每条记录均包含标准答案与预期的引用元数据。
-
数据使用与划分: 路由数据集采用 60/40 的训练/测试划分,改写数据集则遵循 80/10/10 的训练/验证/测试划分。回归集保留用于定期的 LLM-as-a-Judge 评估,重点考察正确性、有用性与严谨性。作者利用这些子集对企业 Agent 内的路由逻辑与查询改写能力进行微调。
-
处理与元数据构建: 数据清洗与标准化由 NeMo Curator 处理,对所有查询-响应对严格执行 PII 移除并符合 GDPR/CCPA 规范。合成生成管道使用 Llama 3.1 405B 作为生成器,注入 SharePoint 文档上下文与结构化提示模板,以生成对齐的问答与改写查询对。最终输出格式包含思维(Thought)、过程(Process)、动作(Action)与动作输入(Action Input)等结构化元数据字段,以指导下游的工具使用微调。
方法
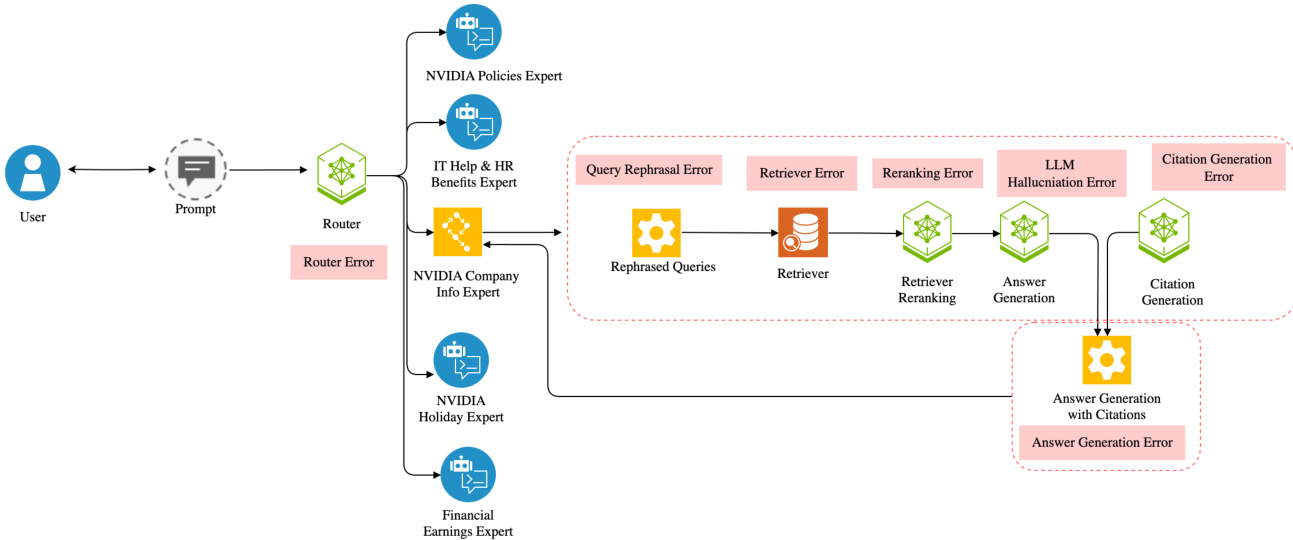
作者采用模块化混合专家(MoE)架构作为 NVInfo AI 系统的基础,该系统作为 NVIDIA 的内部企业聊天机器人。此架构旨在通过路由机制将用户查询分发给专门的专家模型,以处理多样化的企业信息请求。系统的核心是一个路由模块,采用大语言模型(Llama 3.1 70B)对传入的用户查询进行分类,并将其导向七个领域专家之一:财务信息、IT 帮助与 HR 福利、SharePoint、节假日、咖啡厅菜单、人员信息或 NVIDIA 政策。这种模块化设计实现了任务特定的对齐,并通过将复杂查询卸载至最合适的模型来提升效率。路由后的查询处理管道包含多个关键阶段:结合历史对话上下文进行对话改写、生成多种查询变体以提升检索覆盖率、跨文档集合搜索的语义检索器、用于优先排序相关结果的重新排序与去重、答案生成、用于来源验证的引用生成,以及用于增强用户交互的后续建议问题生成。
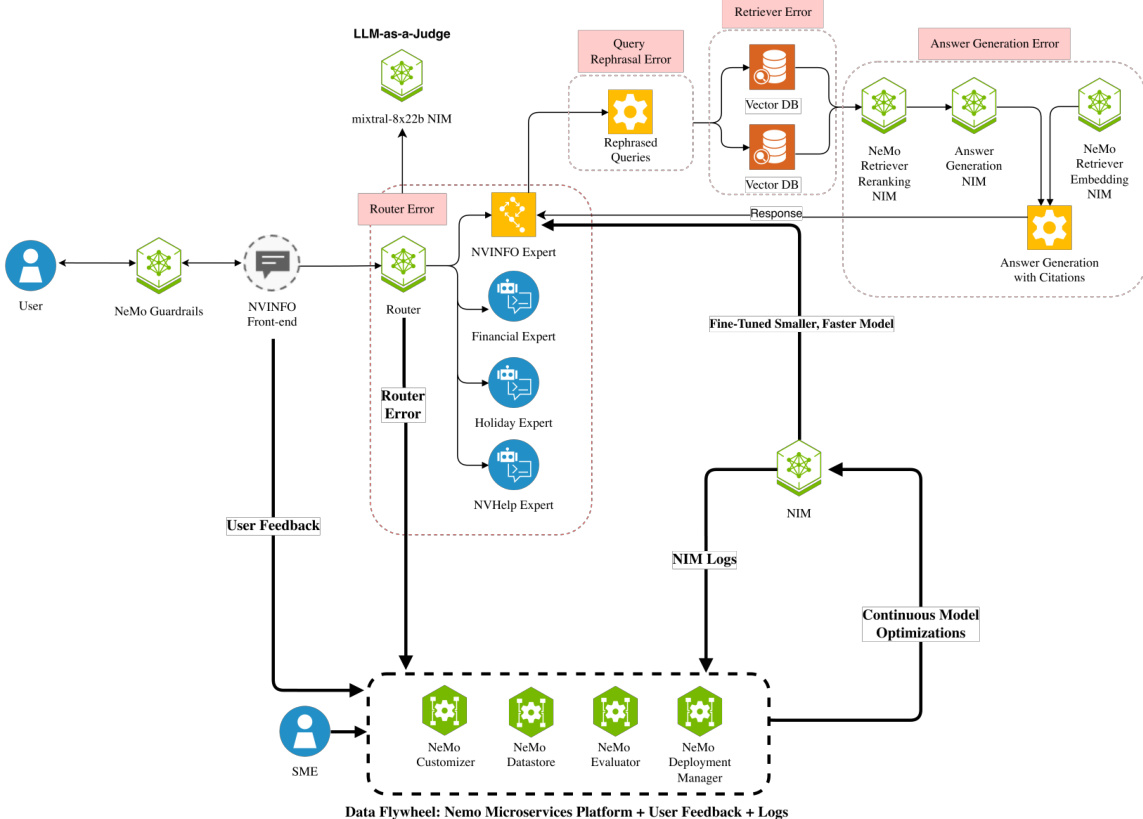
系统的持续改进由自适应数据飞轮控制,该飞轮实施 MAPE-K 控制循环(监控、分析、规划、执行)以构建自我优化的反馈周期。监控阶段收集直接用户反馈(如点赞/点踩评分)与隐式信号(如重新查询与会话放弃),以识别系统故障。随后数据进入分析阶段,结合人工分析与自动分类的系统性错误归因技术被用于精准定位管道内的故障根因,例如路由错误或查询改写失误。规划阶段利用 NVIDIA 的 NeMo 微服务制定针对性的数据整理与微调策略。具体而言,作者采用低秩自适应(LoRA)技术对路由与查询改写组件进行参数高效微调,使用整理后的故障样本实现了显著的模型体积缩减与延迟优化,同时未牺牲准确性。执行阶段涉及将这些微调模型重新部署至系统中,完成飞轮循环并实现持续优化。
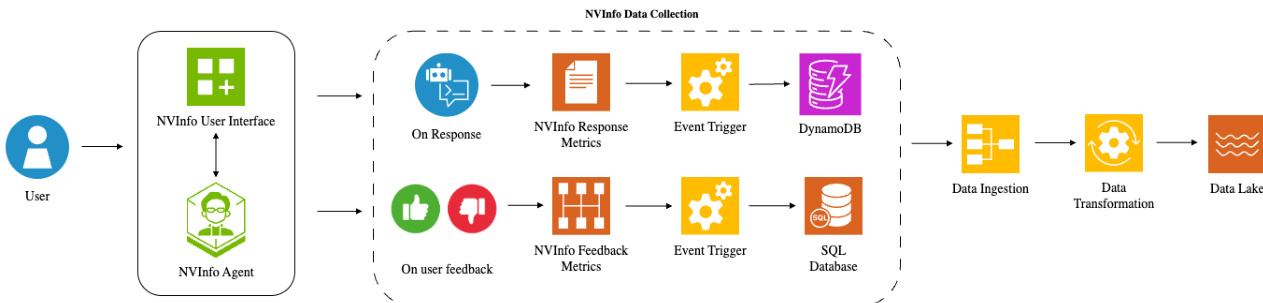
数据收集是该架构的关键组成部分,通过统一管道捕获响应指标与用户反馈。响应指标(包括原始查询、生成的响应、专家选择与系统延迟)存储在 DynamoDB 数据库中以实现可观测性。用户反馈(记录为点赞/点踩及可选的上下文原因)存储在 SQL 数据库中。这两条数据流通过数据转换管道汇入中央数据湖,该管道标准化了数据结构并支持全面分析。收集的数据随后用于训练 LLM-as-a-Judge 模型,该模型用于分类与验证路由错误(如提供的提示示例所示)。系统收集、分析并响应数据的能力构成了其自适应特性的基础,使其能够识别并纠正错误的路由分发、查询改写失误与幻觉等问题,从而提升企业 AI 系统的整体可靠性与性能。
实验
基于生产环境用户反馈在 NVIDIA NVInfo 机器人上进行的评估表明,路由与改写实验验证了微调较小模型可在准确率上匹配较大基线模型,同时大幅提升响应速度。对用户交互的定性分析进一步证明,持续的数据飞轮能有效纠正路由与查询扩展故障,且无需进行大规模重新训练。部署流程凸显了分阶段发布、稳健监控与跨团队协作对于维持大规模系统稳定性的关键作用。最终,研究结果证实,自适应且由反馈驱动的企业 AI Agent 能够持续演进,在显著降低计算开销的同时提供可靠的企业级解决方案。
作者针对查询改写任务对比了微调后的 Llama 3.1 8B 模型与基线 Llama 3.1 70B 模型,展示了准确率提升与延迟降低的效果。结果表明,较小模型在此特定任务中可取得优于较大基线模型的性能。微调后的 Llama 3.1 8B 模型准确率高于 Llama 3.1 70B 基线模型。与 Llama 3.1 70B 基线模型相比,微调后的 Llama 3.1 8B 模型延迟更低。在查询改写任务中,较小模型实现了优于较大基线模型的性能。

作者通过分析用户反馈来识别系统错误并改进模型性能。结果显示,路由与改写错误仅占总故障的一小部分,表明针对这些领域进行定向优化可显著提升系统准确率与效率。路由与改写错误合计仅占系统总故障的较小比例。大多数错误被归类为其他类别,表明非路由与非改写问题主导了系统故障。该分析支持在路由与改写方面进行集中改进,以提升整体系统性能。
{"summary": "作者评估了面向企业 AI 助手的飞轮系统,重点通过用户反馈进行模型优化与错误修正。结果表明,模型效率与准确率显著提升,同时在多个领域保持高性能。", "highlights": ["模型体积缩减 10 倍,同时保持高路由准确率并大幅降低延迟。", "查询改写准确率提升且延迟显著降低,改善了用户体验。", "用户反馈分析显示,路由与改写错误合计仅占故障的一小部分,表明定向优化措施有效。"]}

作者评估了多种微调模型与基线 Llama 3.1 70B 模型的性能对比,重点关注准确率与延迟的优化。结果显示,较小模型在延迟大幅降低的情况下达到了与基线相当或近乎相当的准确率,证明了微调在提升效率方面的有效性。实验揭示了模型规模与性能之间的权衡,微调后的小模型实现了高准确率,且延迟远低于大型基线模型。经过微调的较小模型在大幅降低延迟的同时,达到了与大型基线模型相当的准确率。与未经微调的模型相比,微调使较小模型在准确率与速度上实现了显著的性能提升。结果表明,优化后的小模型在效率方面可超越大模型,且未牺牲准确率。

实验针对查询改写与路由任务,将微调后的小型语言模型与大型基线模型进行对比,同时分析用户反馈以分类系统错误。这些评估验证了定向优化可使小型架构在大幅提升响应速度的同时,达到或超越基线准确率。此外,错误分析证实,路由与改写故障仅占系统总问题的极小部分,表明集中优化能有效提升整体可靠性。综合来看,研究结果确立了通过微调实现高效模型扩展的成功路径,在性能与计算需求之间取得了良好平衡。