Command Palette
Search for a command to run...
使用 vLLM 加载大模型进行少样本学习
摘要
一句话总结
通过对Gemma3系列、Llama4 Scout、Qwen3、Magistral Small和DeepSeek R1模型在2,780篇医学、健康与生命科学论文上的表现进行两项金标准评估,本研究证明,参数量超过40亿的模型能够可靠地对期刊文章的研究质量进行评级;分数平均法可一致性地提升准确率,而少样本提示仅提供微弱收益;推理模型未带来性能优势。该结果验证了计算高效、可离线部署的大型语言模型在科研评估中的实用性。
核心贡献
- 本研究利用包含2,780篇医学、健康与生命科学论文的数据库及两项专家金标准,对中规模、小规模及推理型大型语言模型进行了系统评估,以量化参数量与架构如何影响研究质量评分。
- 分析过程评估了提示技术,证明对多次相同查询的结果进行平均可一致性地提升与专家评分的一致性,而少样本提示仅带来边际收益。
- 性能基准测试确认,参数量超过40亿的模型在无需专用推理步骤的情况下,即可取得与ChatGPT 4o-mini及Gemini 2.0 Flash相当的结果,这支持将更小、支持离线部署的模型应用于安全的科研评估工作流中。
引言
大型语言模型正逐渐成为评估学术研究质量的可扩展替代方案,为开发高效、可离线部署的评估工具提供了路径。尽管早期研究已证明主流云端模型及少数开源权重模型能与专家判断达到中等程度的一致性,但在模型规模、推理能力及提示策略如何影响评分准确性方面仍存在显著空白。既往研究在不同架构与量化方法下得出的结果也不尽一致,导致小规模或专注推理的模型在实际应用中的可行性尚未得到充分验证。为弥补这些不足,研究团队对数千篇生物医学论文的系统专家质量评级进行了基准测试,涵盖多种中规模、小规模及推理型大型语言模型。研究评估了少样本提示与迭代分数平均法,证明参数量超过40亿的模型表现可与领先商业系统相媲美。最终结论表明,对多个模型输出进行平均可可靠地提升与人类专家的一致性,而推理模型未提供可测量的收益,这证实了更小、资源高效的大型语言模型现已成为科研评估中可信且实用的工具。
数据集

- 数据集构成与来源: 研究团队构建了一个聚焦健康与生命科学领域的基准数据集,数据源自英国研究卓越框架(REF2021)主委员会A。该集合涵盖六个评估单元(Units of Assessment),涉及临床医学、公共卫生与初级保健、辅助医疗专业、心理学与神经科学、生物科学以及农业与兽医学。
- 子集详情与筛选: 每个评估单元随机抽取500篇期刊文章,初始池共3,000篇。在剔除跨机构重复提交的文献后,最终数据集包含2,780篇独立文章。研究团队应用了两项筛选规则:排除缺少DOI的文章以确保唯一性追踪,并移除摘要最短的10%论文,此类文章通常代表短篇贡献。
- 数据用途与评估设置: 该集合仅用作静态评估基准,而非模型训练数据,因此不存在训练集划分或混合比例。它作为固定测试集,用于比较不同大型语言模型的研究质量预测能力。数据集被处理为两个并行的评分流,作为模型评估的独立真实标签。第一条流依赖部门平均质量评分,每篇文章被赋予其提交部门的REF2021平均评级。由多个部门提交的文章则获取这些部门平均值的均值。第二条流采用自定义金标准,由第一作者依据与REF2021标准对齐的九点量表独立评定每篇论文,并进行正态参考以匹配官方评估单元的分布。
- 处理与元数据构建: 研究团队通过验证DOI可用性及追踪跨评估单元的重叠情况来构建元数据。对于部门代理评分,将提交分数的聚合结果通过平均质量评级百分比转换为单篇数值。为缓解代理评分中潜在的部门偏差,独立作者评分提供了三角验证的质量指标。所有文本与元数据均保留原始格式,除最初排除短篇摘要外未进行任何裁剪。
方法
研究团队利用结构化框架,通过大型语言模型评估研究质量,重点考察人类专家评估与AI生成分数之间的一致性。整体方法涉及生成跨多个学科的大型文章数据集,每篇文章均标注专家评分,随后应用不同提示策略的大型语言模型对相同文章进行评估。核心评估指标为人类评分与AI评分之间的等级相关系数,因为既往研究已证明,由于大型语言模型倾向于生成聚集在特定值周围的分数,绝对分数准确度的实际意义较低。该框架旨在测试不同提示策略(尤其是少样本提示与平均法)如何影响大型语言模型输出的一致性与可靠性。
提示策略以系统提示开头,该提示从原创性、重要性与严谨性三个维度定义评估任务,这些维度与REF2021主委员会A的科研评估指南相一致。此提示经过调整,直接以学术专家身份与大型语言模型对话,确保模型正确理解任务。对于支持独立系统与用户提示的模型,该提示单独提供;对于其他模型,用户提示则包含完整说明。核心用户提示由指令“Score this article:”、文章标题、换行符、文本“Abstract”以及文章摘要组成。排除全文旨在降低计算开销,且既往研究表明摘要与专家评分的相关性结果相当。
针对少样本提示方法,研究团队设计了一种包含示例输入及对应评分的策略以引导大型语言模型。鉴于专家报告存在差异,定义“正确”输出颇具挑战,因此少样本方法经过精心构建以平衡代表性与实用性。所选策略包含四篇示例文章,涵盖从1到4的所有评分等级,以提供全面的评估标准。该方法优于仅限制高分文章示例或仅使用两个示例的替代方案,因为它确保了在整个评分谱系上的更好区分度,尤其是针对低质量文章。示例从主评估集之外的文章池中选取,以防止数据泄露与模型记忆。具体而言,研究团队采用标记为“Cx2”的修改策略,在每个评估单元(UoA)的每个星级水平中识别两篇候选文章,并在每次提示中随机抽取一篇,以在保持数据完整性的同时维持多样性。
如图所示,少样本提示结构以标注了评分的示例文章开头,随后是标题、摘要以及分隔符("###"),用于区分示例与目标文章。该格式有助于防止混淆,特别是在可能将所有输入文章均视为评估一部分的模型中。提示内容针对每次提交动态重新生成,确保对同一文章的重复评估使用不同的示例组合,从而降低系统性偏差的风险。
方法论的一个关键组成部分是多次大型语言模型响应的平均法。研究团队探讨了以下假设:对多次相同提示的分数进行平均,可通过更准确地捕捉模型内部的概率推理过程来提升可靠性。该技术虽在通用大型语言模型应用中不常见,但既往研究已证明其在科研评估任务中有效。本研究提供了充分证据,表明平均法对不同模型均具有益处,支持多次评估有助于从模型输出分布中提取更一致信息的观点。该平均过程应用于每篇文章的多次提示迭代中,以生成最终聚合分数。
实验
本研究通过跨学科将模型输出与既定的人类基准进行相关性分析,评估了多种大型语言模型对学术研究质量进行排名的能力。受控实验验证了模型规模、提示策略与架构设计的影响,结果表明中规模及小规模开源权重模型可达到与大型系统相当的排名准确率,而专用推理架构并未提供明显优势。定性分析进一步指出,多次提示迭代的平均法可一致性地提升可靠性,而少样本技术带来的边际收益主要源于提示多样性的增加,而非直接的示例学习。最终结论证实,小规模模型为文章相对排名提供了实用且安全的选择,确认该能力作为核心功能可有效支持专家决策,且无需消耗大量计算资源。
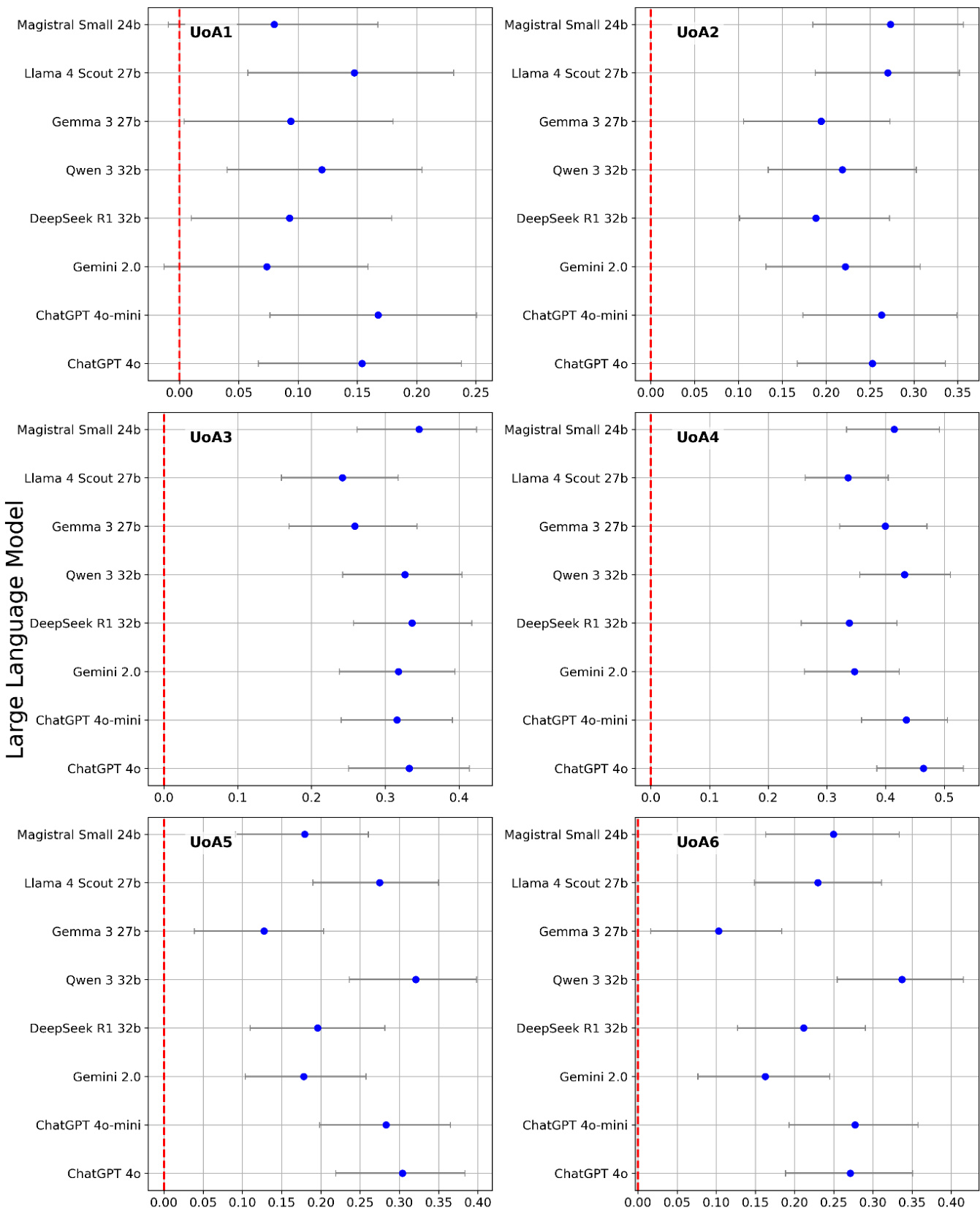
下表展示了不同科研评估单元中的Spearman相关性结果,并比较了组合大型语言模型分数的多种融合方法。结果显示,不同融合策略产生的相关性水平各异,部分方法在各单元中均稳定优于其他方法。整体表现表明,对多个模型的分数进行平均通常可提升与金标准的相关性。与单一模型分数相比,跨多个模型平均大型语言模型分数能更好地改善与金标准的相关性。不同融合方法在不同科研评估单元中的有效性存在差异,部分方法在特定场景下表现更佳。特定单元观测到最高相关性,表明模型性能可能因研究领域而异。
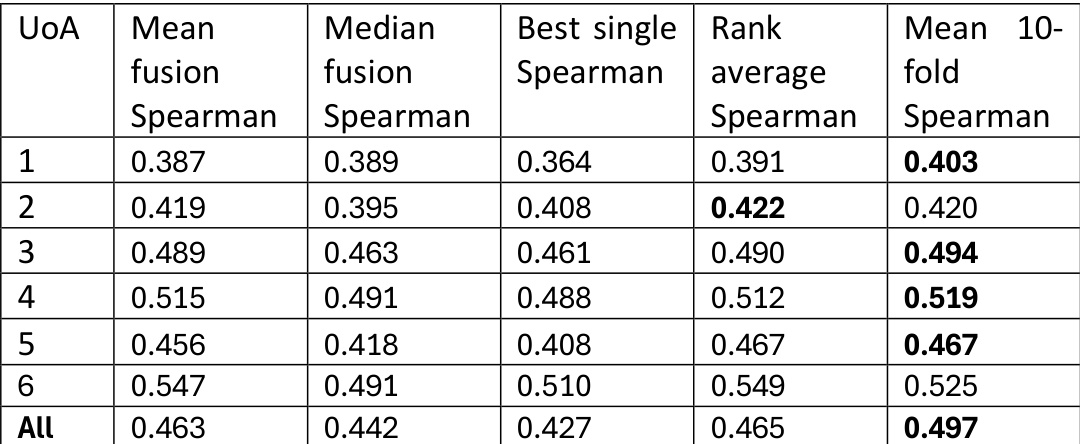
下表展示了六种评估单元及整体平均值中不同融合方法的Spearman相关性结果,表明中位数融合与等级平均法通常优于均值融合与单一模型方法。UoA 4与UoA 3观测到最高相关性,且中位数融合在多数情况下表现最佳。与其他融合方法相比,中位数融合在大多数评估单元中持续获得最高的Spearman相关性。在多数评估单元中,等级平均融合的表现优于均值融合与单一模型方法。UoA 4与UoA 3在所有融合方法中均显示最高相关性值,表明其与金标准具有更强的一致性。
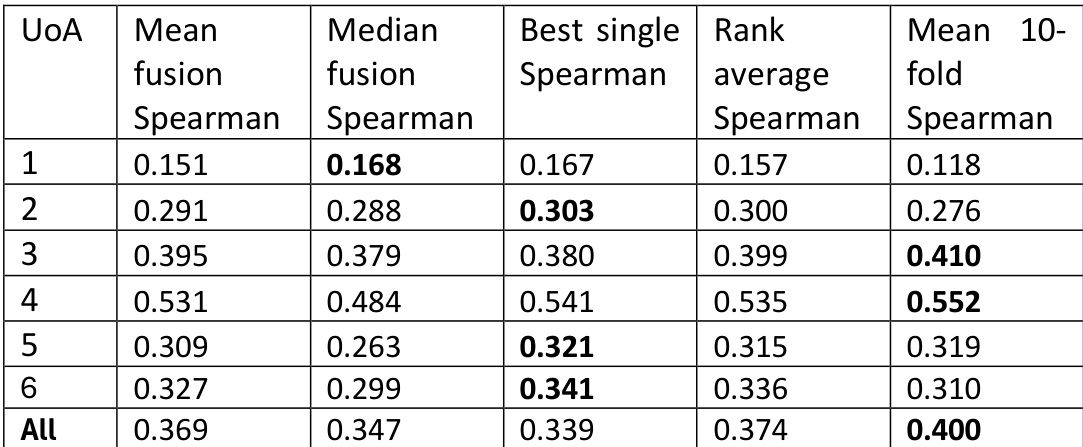
研究团队比较了多种大型语言模型对学术文章评分的性能,采用Spearman相关性衡量其与人类判断的一致性。结果表明,不同模型实现的相关性水平各异,部分模型在不同评估指标下表现稳定,而其他模型在评分模式上存在显著差异。不同大型语言模型与人类评估的相关性程度各不相同,部分模型在不同指标下展现出一致的性能。模型性能差异显著,部分模型实现的相关性高于其他模型,反映出其在评估研究质量能力上的区别。研究强调,模型性能可能因所用具体评估指标的不同而产生差异,表明指标选择会影响模型实际表现的有效性。
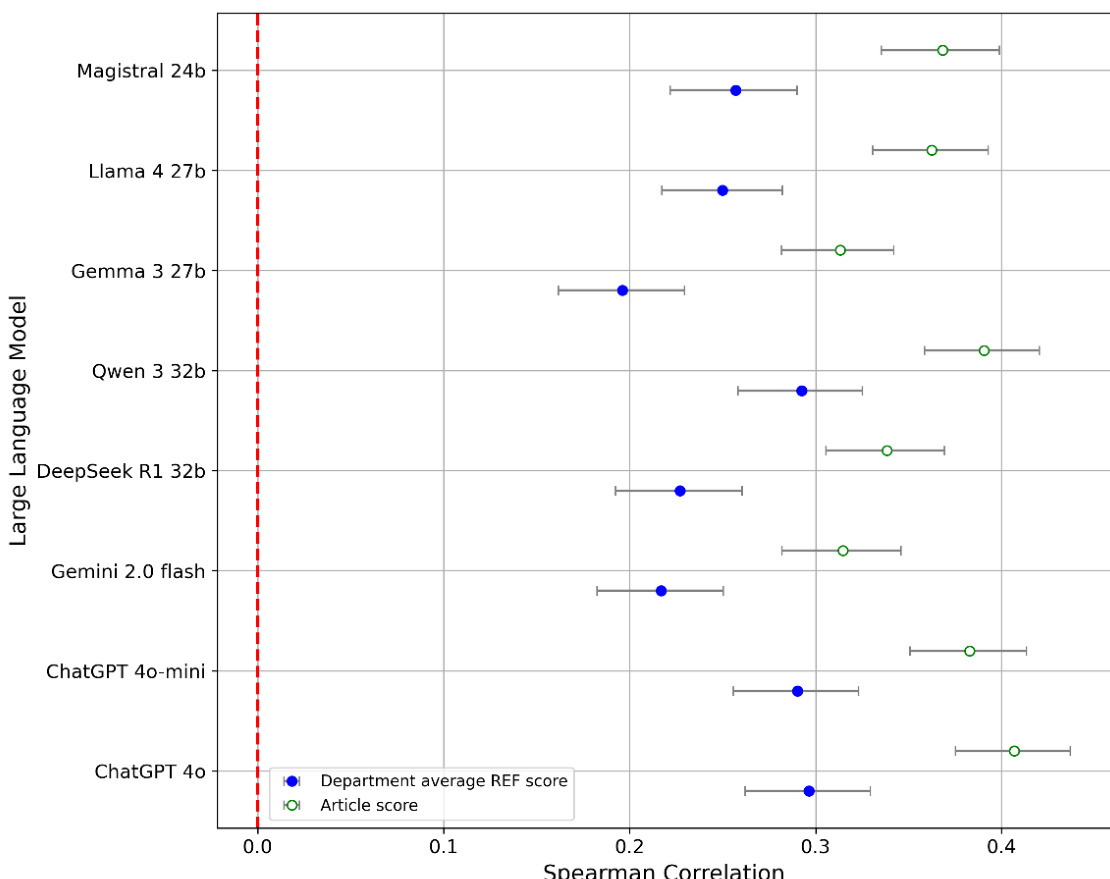
实验评估了多种大型与中型语言模型基于研究质量对学术文章评分的性能,采用Spearman相关性衡量其与人类判断的一致性。结果表明,模型性能在不同评估单元间存在差异,部分模型在大多数单元中表现稳定,而其他模型波动显著,且多次分数平均可提升可靠性。分析还指出,少样本提示可能提升性能,但这未必源于对示例的学习,且推理模型在此任务中并未展现出相较于非推理模型的明确优势。在全部评估单元中,对多个模型分数进行平均均能改善与人类判断的相关性。模型性能在不同评估单元间差异显著,部分模型结果稳定,而其他模型波动极大。尽管推理模型速度更慢且资源消耗更大,但其表现并未超越非推理模型。
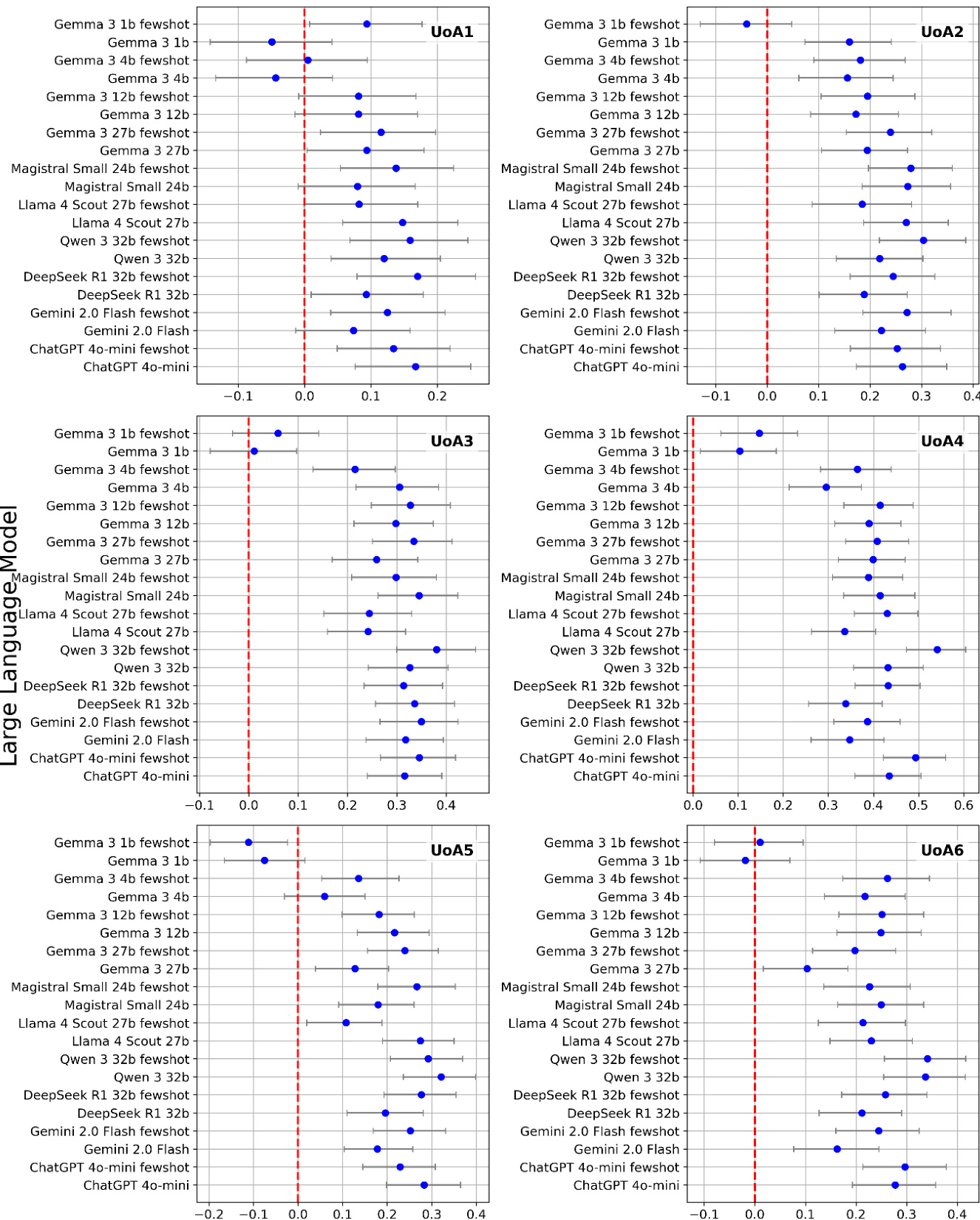
研究团队评估了多种大型与中型语言模型评估学术文章研究质量的能力,重点考察模型规模、提示策略与架构特征对性能的影响。结果表明,小规模模型可实现与大规模模型相似的相关性,且多次分数平均可提升一致性,而少样本提示提供的收益有限,可能源于提示变化而非示例学习。小规模模型的表现与大规模模型相当,云端模型或推理模型在研究质量评分中并无明显优势。与使用单一分数相比,对多个模型分数进行平均可一致性地改善与人类判断的相关性。少样本提示显示出微弱的改进证据,这可能归因于提示多样性的增加而非示例学习。
该系列实验针对多个评估单元,评估了大型与中型语言模型在对照人类判断对学术研究质量评分方面的表现。研究证实,与依赖单一模型输出相比,通过平均法或基于中位数的融合来聚合预测结果,可一致性地提升与人类评估的一致性。此外,实验确认小规模模型能够匹敌大规模模型,而推理架构或少样本提示等高级功能并未提供可靠的性能提升。综合来看,这些发现表明模型集成仍是提升跨不同研究领域评分一致性的最稳健方法。