Command Palette
Search for a command to run...
使用深度 Q 学习构建跳棋游戏智能体
摘要
一句话总结
作者提出了 AOAD-MAT,这是一种基于 Transformer 的 actor-critic 架构,通过将 next-agent prediction 子任务整合到 Proximal Policy Optimization 损失函数中,显式地纳入了 agent 决策顺序,在 StarCraft Multi-Agent Challenge 和 Multi-Agent MuJoCo 基准测试中展现了卓越的性能。
核心贡献
- 提出 AOAD-MAT,一种基于 Transformer 的多 agent 强化学习架构,在协同训练过程中显式学习并优化 agent 动作序列。
- 将 next-agent prediction 子任务整合至 Proximal Policy Optimization 损失函数,以动态调整动作序列并协同最大化 advantage 函数。
- 通过在 StarCraft Multi-Agent Challenge 和 Multi-Agent MuJoCo 基准测试上进行大量实验验证该框架,证明其性能持续优于现有基线方法。
引言
多 agent 强化学习 (MARL) 已成为协调自动驾驶机器人和智能交通网络等复杂协同系统的关键技术,但仍面临环境非平稳性及联合动作空间快速扩张的挑战。近期基于 Transformer 的框架(如 MAT 和 ACE)通过将 agent 协同视为序列生成任务推动了该领域的发展,但未能考虑一个关键操作因素:agent 执行决策的实际顺序。动作顺序对团队稳定性与整体奖励具有重大影响,尤其是在 agent 具备非对称能力或受动态环境约束的情况下。为弥补这一差距,作者提出了 AOAD-MAT,这是一种新型架构,能够显式学习并优化最优动作执行顺序。该方法通过将专用的 next-agent prediction 子任务整合至 Proximal Policy Optimization 损失函数来实现,使模型能够在协同最大化协同优势的同时动态调整决策序列。在标准基准测试上的综合评估表明,这种感知顺序的方法持续超越现有的 MARL 基线。
方法
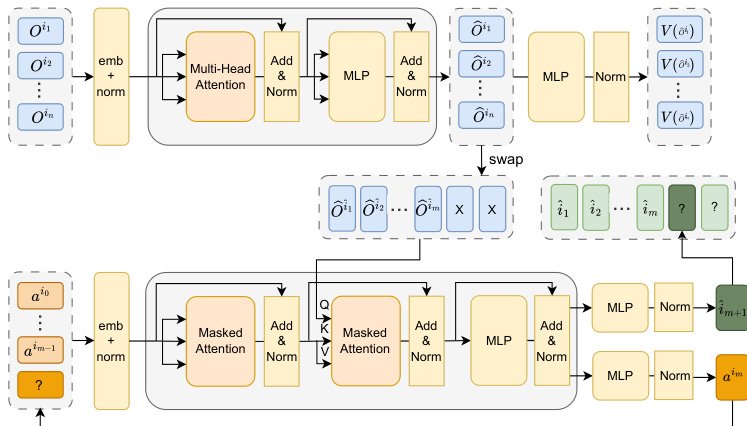
作者利用集中式训练与集中式执行 (CTCE) 框架来解决协同多 agent 强化学习 (MARL) 中的可扩展性与协同挑战。该框架将多 agent 决策重新诠释为序列建模问题,从而支持使用基于 Transformer 的架构。所提出的 AOAD-MAT 模型核心是一种双流架构,在统一的 Transformer 框架内整合了策略函数与价值函数。该架构由编码器与解码器组成,具体结构如图所示。作为 critic 网络的编码器,处理所有 agent 的联合观测值以生成一组潜在表示。这些表示随后被输入至解码器,解码器充当 actor 网络,以自回归方式生成 agent 的动作。
核心创新在于对序列决策过程的显式建模。模型预测 agent 的行动顺序,并将该预测视为离散输出。该动作决策顺序预测被直接整合至学习过程中。负责生成动作的解码器增加了预测下一个 agent 执行动作的子任务。该预测基于系统当前状态及已采取的动作历史进行。预测出的 agent 顺序随后用于重新排列观测值的潜在表示,确保解码器按正确顺序关注相关信息。该重排通过对编码器输出应用置换函数实现,使观测值与预测的动作序列对齐。
模型的学习过程由多 agent 优势分解定理引导,该定理提供了一种将联合优势信号分解为每个 agent 独立贡献的规范方法。该分解使模型能够准确分配信用,并以反映决策过程序列特性的方式更新策略。优势函数采用增量方式计算,其中某个 agent 动作的优势取决于所有前置 agent 的动作。该机制确保策略更新与预测的动作顺序保持一致,从而实现更稳定且高效的学习。框架图展示了模型如何预测下一个 agent 执行动作并生成对应动作,同时潜在表示会动态重排以反映不断演变的动作序列。
实验
评估在离散的 StarCraft II 与连续的 MuJoCo 多 agent 环境中,将所提出的 AOAD-MAT 模型与传统及调整后的基线方法进行对比,以评估学习稳定性与探索效率。结果表明,AOAD-MAT 通过动态优化 agent 动作顺序持续取得优异性能,该方法被证明比固定序列、随机打乱或简单的超参数调整更为有效。自适应排序机制促进了更灵活的优势评估与高效探索,性能提升直接与顺序预测熵的收敛相关联。最终,实验验证了整合协同损失函数与战略性 lead agent 选择可进一步提升协同学习效果,证实了该模型在复杂多 agent 场景中的鲁棒性。
{"summary": "作者将提出的 AOAD-MAT 模型与基线方法在 SMAC 和 MA-MuJoCo 任务上进行对比,重点关注训练步骤顶部百分位数的性能差异。结果表明,AOAD-MAT 在所有任务中持续优于基线方法,尤其在异构场景中表现突出,表明其感知动作顺序的设计能够带来更稳定且有效的策略更新。", "highlights": ["AOAD-MAT 在所有 SMAC 任务中均取得高于基线方法的性能,尤其是在 MMM2 等异构场景中。", "所提模型在连续控制任务中展现出更高的学习稳定性与峰值性能,MA-MuJoCo 中的更高奖励与置信区间证实了这一点。", "AOAD-MAT 的自适应动作排序策略有助于改善策略更新,性能提升在长期训练后变得更为显著。"]}
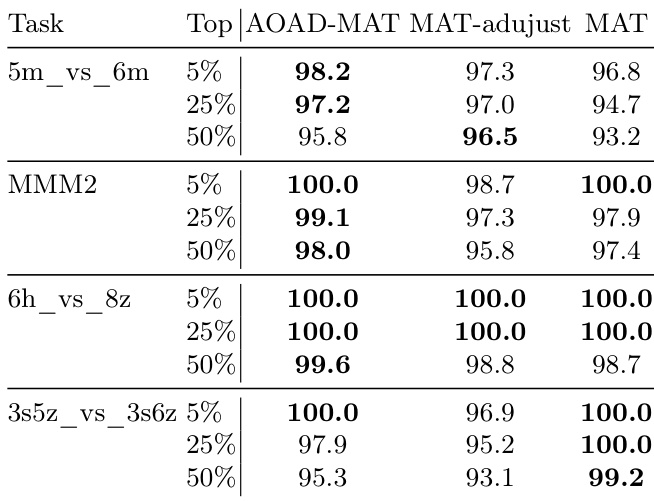
作者将所提出的 AOAD-MAT 模型与基线方法在 SMAC 和 MA-MuJoCo 基准测试上进行评估,重点关注其在具有挑战性的多 agent 场景中的性能。结果显示,AOAD-MAT 实现了较高的胜率与奖励提升,在所有任务中持续表现优异,尤其在异构与复杂环境中,这表明其感知动作顺序的设计增强了策略稳定性与探索能力。AOAD-MAT 在所有 SMAC 和 MA-MuJoCo 任务中均取得最高性能,在胜率和奖励方面均超越基线方法。得益于自适应动作排序策略,该方法展现出更高的学习稳定性与峰值性能,尤其在训练后期阶段表现明显。AOAD-MAT 的感知动作顺序设计带来的优势超越了 PPO clip 调整,尤其在固定或随机排序策略效果有限的复杂异构任务中。

作者将所提出的 AOAD-MAT 模型与基线方法在 SMAC 和 MA-MuJoCo 环境中进行对比,重点关注胜率与平均奖励方面的性能。结果表明,AOAD-MAT 在所有任务中均取得更高的中位胜率与更稳定的学习过程,尤其在复杂异构场景与连续控制环境中表现卓越。自适应动作排序策略有助于改善策略更新与探索效率,从而在长期训练后取得更优性能。与基线方法相比,AOAD-MAT 在所有 SMAC 任务中持续取得更高的中位胜率,尤其在复杂异构场景中。AOAD-MAT 在 MA-MuJoCo 中展现出更稳定的学习与更高的峰值性能,中位奖励显著提升且置信区间更为紧凑。AOAD-MAT 中的自适应动作排序策略带来了更好的探索能力与策略稳定性,尤其在训练后期,表明其有效性不仅限于延长训练时间。
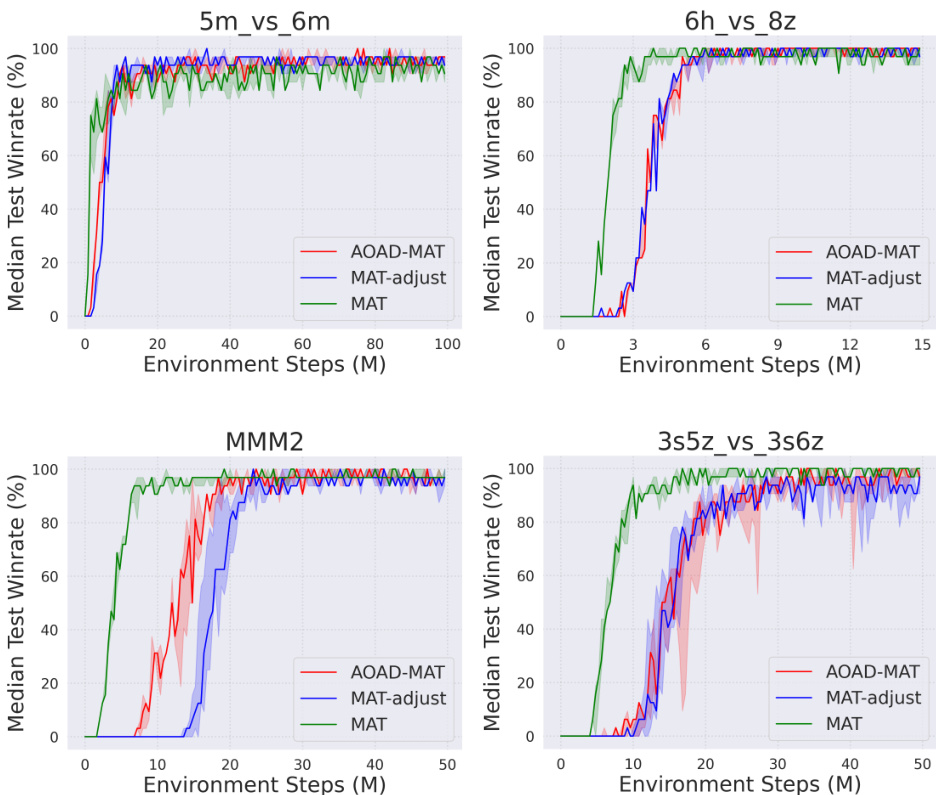
作者将所提出的 AOAD-MAT 模型与基线方法在 SMAC 和 MA-MuJoCo 基准测试上进行评估,以验证其在多 agent 对抗与连续控制环境中的有效性。实验结果表明,该模型持续优于现有方法,尤其在复杂与异构场景中,通过提供更稳定的学习轨迹与更高的峰值性能得以证实。这些定性改进由其自适应动作排序策略驱动,该策略提升了探索效率与策略更新稳定性,尤其在长期训练阶段。总体而言,研究结果证实,在动态多 agent 环境中,感知动作顺序的设计相较于固定或随机排序机制具有显著优势。