Command Palette
Search for a command to run...
用于通用游戏玩的代码世界模型
用于通用游戏玩的代码世界模型
摘要
尽管大型语言模型(LLMs)的推理能力正日益应用于传统的棋盘游戏和纸牌游戏,但当前主流的方法——即通过提示(prompting)直接生成走法——存在显著缺陷。该方法依赖于模型隐式且脆弱的模式匹配能力,导致频繁出现非法走法,且战略层面较为浅显。在此,我们提出了一种替代方案:利用大型语言模型(LLMs)将自然语言规则和游戏轨迹转化为以 Python 代码表示的正式、可执行的世界模型(world model)。该生成的模型包含用于状态转移、合法走法枚举和终止检查的函数,作为蒙特卡洛树搜索(MCTS)等高性能规划算法的可验证模拟引擎。此外,我们提示大型语言模型生成启发式价值函数(以提高 MCTS 效率)和推理函数(以估计信息不完全游戏中的隐藏状态)。我们在涵盖合作性、信息不完全和非对称性的 20 款多样化游戏中评估了我们的方法,结果表明,与直接的大型语言模型(LLMs)走法生成以及通用推理基准相比,我们的方法表现显著更优,胜率达到 85%,而基线的胜率分别为 30% 和 45%。我们的代码和数据可在 https://sites.google.com/view/code-world-models 获取。
一句话总结
Code World Models 使用大型语言模型将自然语言游戏规则翻译为可执行的 Python 世界模型,并生成启发式价值函数和针对隐藏状态的推理函数,从而使蒙特卡洛树搜索在 20 种不同游戏中达到 85% 的胜率,大幅超越直接 LLM 走子生成和通用推理基线分别 30% 和 45% 的胜率。
核心贡献
- 引入了一种方法,将自然语言游戏规则和轨迹翻译为可执行的 Python 代码,生成包含状态转移、合法动作枚举和终止检查函数的形式化世界模型,作为规划算法的模拟引擎。
- 通过提示 LLM 生成启发式价值函数以实现更高效的蒙特卡洛树搜索,并生成推理函数以估计非完美信息游戏中的隐藏状态,从而扩展了生成的世界模型。
- 在包括合作、非完美信息和非对称设置的 20 种不同游戏中进行评估,该方法达到了 85% 的胜率,大幅优于直接 LLM 走子生成 (30%) 和通用推理基线 (45%)。
引言
基于大型语言模型的现代游戏博弈 agent 通常将模型视为端到端策略,提示其直接从观察到的轨迹中选择动作。虽然这利用了强大的模式识别能力,但在需要多步前瞻的战略深度上存在困难,并且常常在模型训练分布之外的新游戏上失败。先前关于基于 LLM 的世界模型的工作要么假设完全可观测的确定性环境,要么假设事后可观测性,回避了部分可观测性和随机性这一更困难的挑战。
作者引入了 Code World Models,这是一种将 LLM 用作归纳引擎的方法,从文本描述和有限的游戏数据中合成游戏动态的可执行 Python 模型——包括状态转移、合法动作、奖励和终止条件。对于部分可观测的设置,他们将其扩展为一种正则化自编码器范式,其中 LLM 联合生成一个将观测映射到潜在历史的推理函数和一个重构观测的解码器,游戏规则则作为结构正则化项。他们进一步合成了启发式价值函数以加速搜索,并证明通过 MCTS 或信息集 MCTS 使用这些学习到的模型进行规划,在经典和分布外双人游戏上均优于强大的“思考型” LLM 基线。
数据集
作者构建了一个包含游戏实现、推理问题和单元测试的合成数据集,用于训练能够推理隐藏状态和对手意图的模型。
-
数据集组成与来源
- 该数据集利用了来自多个双人非完美信息游戏的规则描述和代码片段:井字棋、6x6 四子棋变体、Leduc 扑克、Quadranto、Hand of War,以及一个包含物品 X, Y, Z 的讨价还价游戏。
- 它还包括通用的棋盘游戏说明(西洋双陆棋设置)和用于确定性测试的固定随机结果集。
- 类型别名和游戏常量(
Action、State、PlayerObservation、获胜线、物品集)在专门的章节中定义,并在示例中重用。
-
每个子集的关键细节
- 隐藏历史推理函数合成(开牌):提供一个函数签名,从观测-动作历史中重建单个玩家的观测。随附的单元测试打印中间状态和观测,标准输出的最后十行与错误信息一同提供给 LLM。
- 隐藏状态推理函数合成:定义
resample_state,该函数随机采样一个与给定观测-动作历史一致的、可达的状态。单元测试验证最后一个观测是否与重采样状态下的观测匹配。 - 讨价还价游戏常量与对手采样:定义物品集(
X, Y, Z)、回合限制和价值范围。对手私有值随机采样,已知报价从观测历史中的previous_offer字段收集。 - 非终止状态的启发式评估:从状态字典中提取玩家特定值、奖池和报价历史,以计算价值估计。
-
论文如何使用数据
- 作者将推理函数定义用作模型训练的目标输出。每个示例将一个函数签名与一个执行推理的单元测试配对。
- 训练集混合了开牌历史重建和隐藏状态重采样,模型学习从给定的签名和测试代码中生成正确的实现。
- 混合比例未以数字形式指定,但示例涵盖了完全可观测的历史回放和部分可观测的状态重采样。
-
裁剪、元数据和其他处理
- 未描述明确的裁剪策略。单元测试包含打印语句,其输出被捕获并附加到错误反馈中。
- 诸如
INITIAL_STATE、玩家 ID 和观测-动作历史之类的元数据作为模板变量在测试代码中提供。 - 对手价值通过随机采样合成,报价历史通过扫描观测-动作序列中的唯一条目来重建。
方法
作者提出了一种通用游戏博弈 agent,将 LLM 的负担从生成直接策略转移到生成一个好的世界模型上。当面对一个新游戏时,该 agent 首先使用随机策略玩几局以收集轨迹。然后,它使用文本规则和这些轨迹来合成一个 Code World Model。
合成 Code World Model Code World Model 是目标游戏的一个可玩、近似的 Python 实现副本。它包含用于状态转移、合法动作枚举、观测生成和奖励计算的确定性函数。为确保正确性,作者对初始 LLM 生成的模型进行迭代优化。单元测试从离线轨迹中自动生成,以检查模型预测的正确性。作者采用了两种优化策略:一种是将失败单元测试的堆栈跟踪附加到提示中的顺序对话模式,另一种是使用汤普森采样维护和优化多个候选模型的树搜索方法。
为非完美信息游戏合成推理函数 对于非完美信息游戏,该 agent 需要推理函数在规划期间估计隐藏状态。作者提示 LLM 生成代码,从后验信念状态中进行近似采样。他们探索了两种方法:隐藏历史推理,其中 LLM 采样包括随机动作在内的完整动作历史以重建隐藏状态;以及隐藏状态推理,其中 LLM 直接采样隐藏状态。隐藏历史方法保证采样到的状态属于后验的支持集并且是有效的模型状态,而直接状态推理更简单但缺乏这些保证。
合成价值函数 为加速规划,作者还合成了启发式价值函数。与世界模型不同,这些函数无法根据真实情况进行优化。相反,LLM 生成多个价值函数候选项,并通过锦标赛评估选出最佳的一个。
使用 MCTS 和 ISMCTS 进行规划 在游戏过程中,该 agent 使用合成的世界模型作为规划的模拟引擎。对于完美信息游戏,采用标准的蒙特卡洛树搜索。对于非完美信息游戏,该 agent 使用信息集蒙特卡洛树搜索。在此方法中,模拟从推理函数采样得到的可能真实状态分布开始。诸如价值估计和访问次数之类的统计信息在信息状态层面进行维护和聚合,将对于玩家而言看似相同的历史归为一组。
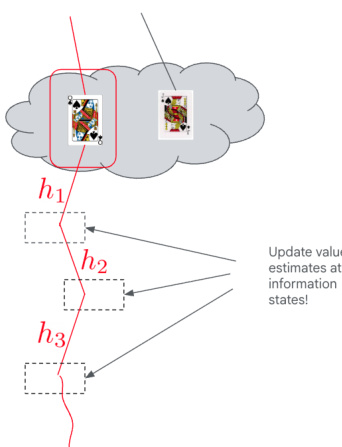
如上图所示,搜索树建立在可能的真实历史上,例如 h1、h2 和 h3。由于玩家无法区分因隐藏信息(由云中的牌表示)导致的某些历史,价值估计和访问次数在信息状态层面(由虚线框表示)进行聚合。
使用 PPO 摊销规划 作为缓慢在线规划的替代方案,作者研究了将规划计算摊销到使用近端策略优化训练的反应式策略中。该 agent 完全在学习到的世界模型环境中进行训练。对于完美信息游戏,actor-critic 网络使用共享的全连接层。对于非完美信息游戏,添加了一个循环神经网络来处理历史信息。JSON 格式的观测通过 LLM 生成的程序化映射被映射到 1D 张量。
实验
实验评估了一个 agent,该 agent 从文本规则和少量离线轨迹中合成计算世界模型 (CWM),然后使用蒙特卡洛树搜索进行规划。合成准确性在完美信息和非完美信息游戏(包括新颖的分布外游戏)上均得到验证,基于树搜索的优化被证明比对话式优化更有效。在游戏中,CWM agent 达到或超过了真实规划 agent 的表现,并持续击败直接 LLM 策略,尽管合成在处理像 Gin rummy 这样程序复杂的游戏时存在困难。隐藏信息从不揭示的闭牌设置会降低合成质量,但不会显著损害最终的游玩表现。
作者评估了其 CWM-ISMCTS agent 在非完美信息游戏中对抗 LLM 策略、真实 ISMCTS agent 和随机 agent 的游玩表现。结果表明,合成的 agent 通常比基于 LLM 的策略和随机 agent 获得更高的收益,同时与真实基线相比具有竞争力。CWM-ISMCTS agent 在所有测试的非完美信息游戏中,对抗随机 agent 时均持续获得正收益。当对抗 LLM 策略时,该 agent 在 Bargaining 和 Gin rummy 中获得了更高的平均收益,但在 Leduc 扑克中表现有所波动。对抗真实 ISMCTS 基线时,该 agent 展示了有竞争力的表现,在 Leduc 扑克和 Gin rummy 等游戏中的收益保持相对接近。
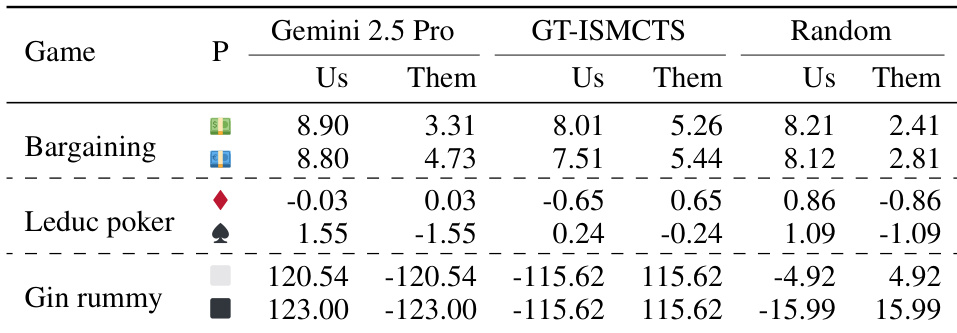
作者在包括 Bargaining、Leduc 扑克和 Gin rummy 的非完美信息游戏上评估其 CWM-ISMCTS agent,对抗 LLM 策略、真实 ISMCTS 基线和随机 agent。结果表明,合成的 agent 在 Bargaining 和 Leduc 扑克中表现与真实基线相当,同时在 Gin rummy 中对抗随机 agent 和真实基线均获得了高收益。LLM 策略在 Gin rummy 中明显吃力,这可能是由于游戏复杂的程序规则和高弃牌率。CWM-ISMCTS agent 在 Bargaining 和 Leduc 扑克中达到了与真实 ISMCTS 基线相当的表现。该 agent 在 Gin rummy 中获得了远高于 LLM 策略的收益,凸显了 LLM 在处理复杂游戏规则时的困难。在 Bargaining 和 Leduc 扑克中,对抗随机 agent 的收益是均衡的,但在 Gin rummy 中明显有利于 CWM-ISMCTS agent。
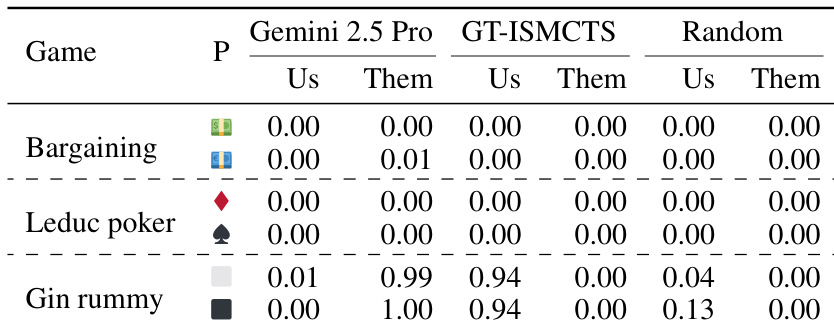
作者评估了其 agent 在非完美信息游戏中对抗 LLM 策略、真实搜索 agent 和随机 agent 的游玩表现。结果显示,该 agent 通常优于 LLM 策略,在 Quadranto 中取得了压倒性的胜率,在 Hand of war 中取得了有竞争力的结果。对抗真实 agent 时,该 agent 在 Quadranto 中频繁平局,而对抗随机 agent 的比赛结果主要是胜利或平局。该 agent 在 Quadranto 中对抗 LLM 策略取得了高胜率,显著超过其失败率。在 Quadranto 中对抗真实 agent 的比赛产生了高平局率,表明竞争力相当。该 agent 在两个测试游戏中均持续对抗随机 agent 取得胜利或平局。

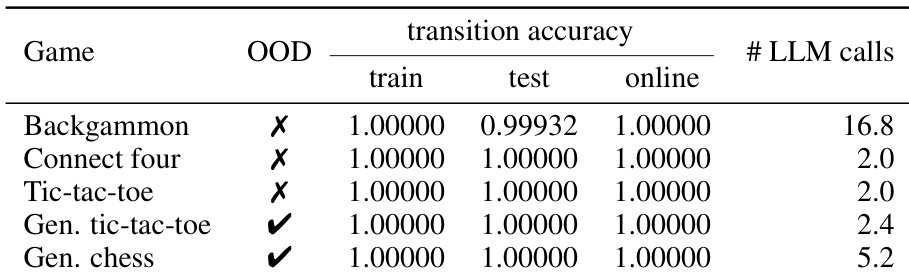
作者使用树搜索优化评估了完美信息游戏的合成因果世界模型的转移准确性。结果表明,对于所有评估的游戏(包括分布外游戏),学习到的模型在训练、测试和在线阶段均达到了近乎完美的准确性。此外,合成过程快速收敛,仅需相对较少的 LLM 调用即可达到高性能。对于所有完美信息游戏,合成的模型在训练、测试和在线评估中均达到了完美或近乎完美的转移准确性。分布外游戏也达到了最高的转移准确性,展示了强大的泛化能力。树搜索优化实现了快速收敛,仅需极少的 LLM 调用即可为标准游戏合成准确的模型。
作者使用开牌学习和隐藏历史推理评估了其 agent 在非完美信息游戏上的合成准确性。结果显示,大多数游戏的转移准确性普遍非常高,尽管 Gin rummy 由于其程序复杂性,在转移和推理准确性方面均表现出明显较低的性能。虽然推理准确性在几个游戏中接近完美,但在 Hand of war 中下降,在 Gin rummy 中显著下降,表明推理隐藏历史比学习转移动态更具挑战性。大多数游戏的转移准确性接近完美,但 Gin rummy 显示出较低的准确性,并需要最大预算的 LLM 调用。Bargaining、Leduc 扑克和 Quadranto 的推理准确性保持较高,但 Hand of war 有所下降,Gin rummy 最差。LLM 调用次数在不同游戏中差异很大,Leduc 扑克快速收敛,而 Gin rummy 耗尽了优化预算。
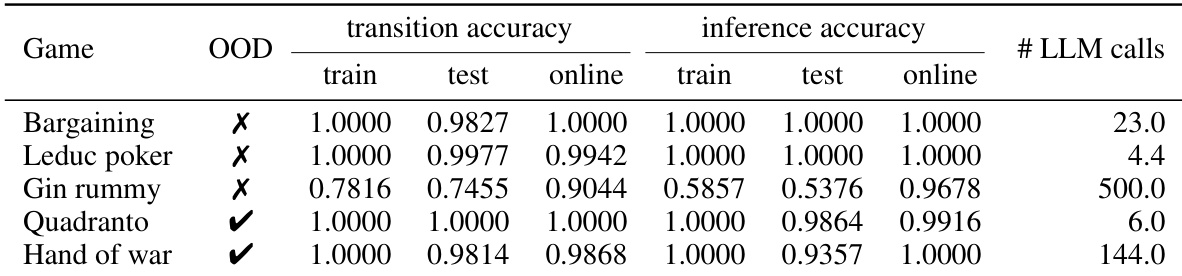
评估涵盖了完美信息和非完美信息游戏,测试了 CWM-ISMCTS agent 对抗 LLM、真实搜索和随机基线的游玩表现,以及其模型合成准确性。在游戏中,该 agent 持续优于 LLM 策略和随机 agent,同时与真实 ISMCTS 基线达到竞争性均势,尽管 LLM 在像 Gin rummy 这样程序复杂的游戏中明显吃力。合成过程为完美信息游戏带来了近乎完美的转移准确性,并为大多数非完美信息游戏带来了高准确性,且收敛迅速,仅需少量 LLM 调用,尽管推理隐藏历史和建模像 Gin rummy 这样的复杂游戏仍然更具挑战性。总体而言,该 agent 展示了强大的泛化能力和有竞争力的表现,其合成准确性和游玩成功仅在高程序复杂性下有所下降。