Command Palette
Search for a command to run...
Google SynthID文本水印的鲁棒性评估与增强
Google SynthID文本水印的鲁棒性评估与增强
Xia Han Qi Li Jianbing Ni Mohammad Zulkernine
一键部署 AI 文本生成水印工具 SynthID-Text
摘要
Google DeepMind推出的SynthID-Text等LLM水印方法的最新进展,为追踪AI生成文本的来源提供了极具前景的解决方案。然而,我们的鲁棒性评估表明,SynthID-Text易受保义攻击(如改写、复制粘贴修改和回译)的影响,这些攻击会显著降低水印的可检测性。为解决这些局限性,我们提出了SynGuard,这是一个混合框架,结合了语义不变鲁棒性(Semantic Invariant Robust, SIR)的语义对齐优势与SynthID-Text的概率水印机制。我们的方法在词汇和语义层面联合嵌入水印,从而在保持原始含义的同时实现鲁棒的来源追踪。在多种攻击场景下的实验结果表明,与SynthID-Text相比,SynGuard在水印恢复的F1分数上平均提升了11.1%。这些发现证明了感知语义的水印技术在抵御现实世界篡改方面的有效性。
一句话总结
作者提出了 SynGuard,这是一种混合框架,通过将语义不变鲁棒性(Semantic Invariant Robust, SIR)的语义对齐与概率水印技术相结合,在词汇和语义层面嵌入标记,从而在面临保义攻击时,使水印恢复的 F1 分数较 SynthID-Text 平均提升 11.1%。
核心贡献
- 本文提出 SynGuard,一种混合水印框架,旨在增强大语言模型(LLM)文本溯源追踪在面对保义对抗编辑时的鲁棒性。
- 该方法在 token 生成过程中,通过结合概率性 logit 修改与语义对齐,在词汇和语义层面联合嵌入检测信号,以保留水印的可检测性。
- 跨多种攻击场景的实验评估表明,SynGuard 使水印恢复的 F1 分数较 SynthID-Text 平均提升 11.1%,并揭示了回译脆弱性与机器翻译质量之间此前未被考察的相关性。
引言
文本水印为验证 AI 生成内容的来源提供了一种轻量级机制,这在黑盒模型普遍存在的开放环境中对于责任追溯至关重要。基于生成的方法(如 Google 的 SynthID-Text)通过在 token 采样过程中嵌入不可察觉的统计信号推动了该领域的发展,但它们在面对保义转换时依然脆弱。现有研究难以在鲁棒性与效率之间取得平衡,因为仅依赖词汇的方法在改写或回译时性能会显著下降,而纯语义技术往往带来较高的计算开销或降低输出多样性。为解决这些局限性,作者提出了 SynGuard,这是一种混合框架,将语义不变鲁棒性(SIR)的语义对齐能力与 SynthID 的概率性 token 掩码技术相结合。通过在词汇和语义层面同时嵌入溯源信号,该方法能够稳健地检测表面修改攻击,同时保留抵抗无密钥移除所需的随机性,在多种攻击场景下使 F1 分数平均提升 11.1%。
方法
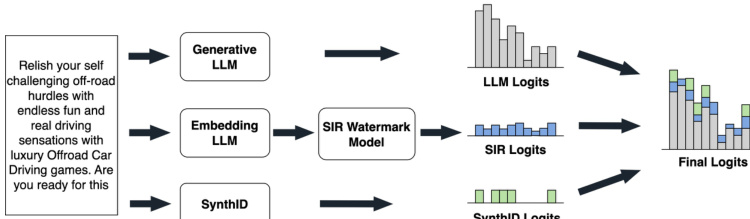
作者采用了一种混合水印框架 SynGuard,该框架融合了语义感知与伪随机水印技术的优势,以增强对保义转换的鲁棒性。核心设计将 SynthID-Text 的采样机制与语义不变鲁棒性(SIR)算法相结合。在水印嵌入过程中,每个 token 生成步骤会生成三组不同的 logits:来自基础语言模型(LLM)的基础 logits、基于前文条件由语义水印模型推导出的 SIR logits(用于编码语义一致性),以及基于 token 哈希值、密钥和随机种子通过伪随机机制计算的 SynthID logits。这三个分量通过语义权重 δ 进行线性组合,生成最终的 logits 向量,随后输入 softmax 函数以输出词汇表上的概率分布。这种组合方法确保水印信号同时嵌入语义结构与 token 级随机性中。
SynGuard 的水印提取通过计算综合得分 s 来实现,该得分同时评估文本与其上下文的语义相似度以及统计水印信号。该得分为两个分量的加权和:归一化语义相似度得分 ssemantic,用于衡量每个 token 根据 SIR 模型与前文上下文的对齐程度;以及 g-value 得分 sg-value,用于量化 SynthID-Text 水印函数在所有 token 上的平均输出。综合得分 s 的计算公式为 s=δ⋅2ssemantic+1+(1−δ)⋅sg-value,其中 δ 为控制语义对齐与伪随机水印信号相对重要性的超参数。该设计确保即使文本经历保义转换,检测得分依然保持鲁棒,因为语义分量维持较高水平,而 g-value 分量对移除尝试具有抵抗力。框架的鲁棒性进一步得到理论分析的支持,该分析表明,真实水印文本的检测得分始终高于某一阈值,而非水印文本错误超过该阈值的概率随文本长度呈指数级衰减。
实验
实验使用标准化的语言模型与数据集,评估 SynthID-Text 水印算法与所提 SynGuard 方法在四种不同文本操纵攻击下的鲁棒性。各场景分别验证检测器对特定篡改策略的弹性,涵盖细微词汇替换与内容稀释,到复杂的结构改写与跨语言重翻译。定性而言,基线方法对简单词汇变化仍有效,但在面对改变文本结构或上下文的保义转换时,性能会出现显著下降。相反,SynGuard 通过有效融合语义对齐与概率采样,在所有攻击路径上持续优于基线方法,最终构建了一个更具弹性的水印框架,在保持检测准确率的同时兼顾文本流畅度。
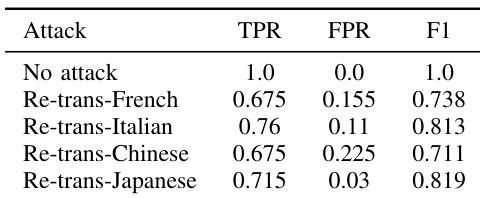
作者评估了 SynthID-Text 与 SynGuard 在多种文本编辑攻击(包括使用不同中转语言的重翻译)下的鲁棒性。结果表明,SynthID-Text 在重翻译攻击下检测性能显著下降,尤其是在以中文作为中转语言时;而 SynGuard 在所有攻击中均保持较高的检测准确率。中转语言的选择会影响重翻译攻击的有效性,其中日语产生的检测性能最高,中文最低。SynthID-Text 在重翻译攻击下的检测准确率大幅下滑,特别是以中文为中转语言时。SynGuard 在所有重翻译攻击场景中的检测准确率均优于 SynthID-Text,展现出更强的鲁棒性。中转语言的选择会影响重翻译攻击的效果,日语带来的检测准确率高于中文及其他语言。
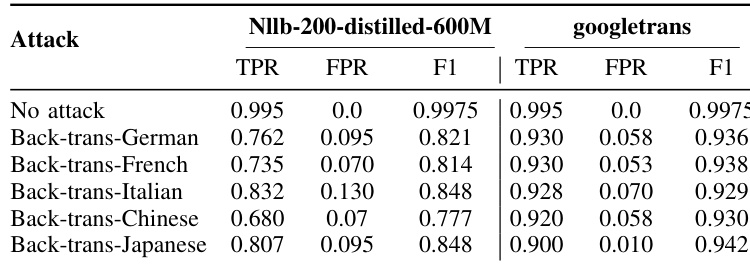
作者使用两种翻译工具(NLLB-200-distilled-600M 与 Google Translate)评估了 SynGuard 对回译攻击的鲁棒性。结果表明,SynGuard 在不同中转语言下均保持高检测准确率,在使用 Google Translate 且以日语为中转语言时达到最高 F1 分数。性能因翻译工具和中转语言的不同而有所差异,NLLB-200-distilled-600M 通常比 Google Translate 产生更低的 F1 分数。SynGuard 在所有回译攻击中均取得高 F1 分数,最佳表现出现在使用 Google Translate 与日语作为中转语言时。翻译工具的选择显著影响检测准确率,在所有测试场景中 Google Translate 均稳定优于 NLLB-200-distilled-600M。即使面对中文等具有挑战性的中转语言,SynGuard 仍保持强劲的检测性能,表明其对严重保义转换具备抵抗力。
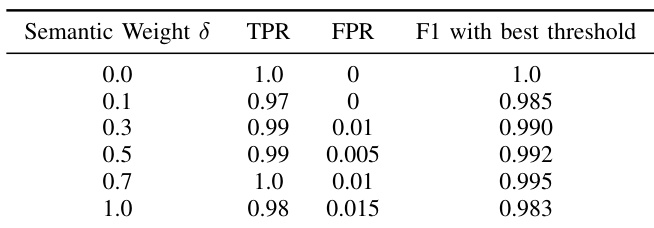
作者使用真阳性率、假阳性率与 F1 分数等指标,探究了语义权重参数对水印算法性能的影响。结果表明,提高语义权重可提升检测性能,在权重为 0.7 时达到最高 F1 分数,尽管假阳性率略有上升。由于 0.7 在检测准确率与假阳性率之间取得了良好平衡,后续评估均选定该最优设置。提高语义权重能够改善检测性能,最高 F1 分数出现在权重为 0.7 时。假阳性率随语义权重增加而轻微上升,但在所有设置下均保持在较低水平。0.7 的最优语义权重因其在准确率与假阳性之间的优异平衡而被选用于后续评估。
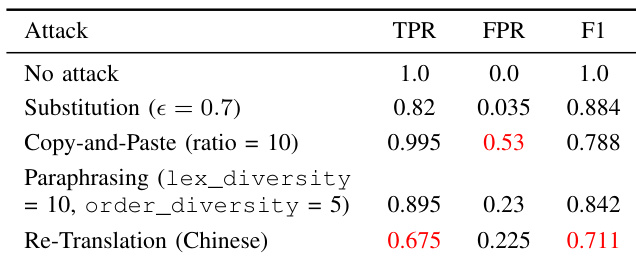
该表格展示了 SynthID-Text 在多种攻击场景下的检测性能指标,显示 F1 分数与 TPR 在不同攻击类型下显著下降。性能衰退在重翻译攻击中最为严重,F1 分数大幅跌落,TPR 降至低位。高比例复制粘贴攻击导致假阳性率显著升高,而同义词替换与改写攻击也会降低检测准确率,但程度较轻。重翻译攻击使 F1 分数大幅下滑,表明其对保义转换存在严重脆弱性。高比例复制粘贴攻击引发高假阳性率,损害了检测可靠性。改写攻击导致性能下降,TPR 与 F1 分数均出现明显缩减。
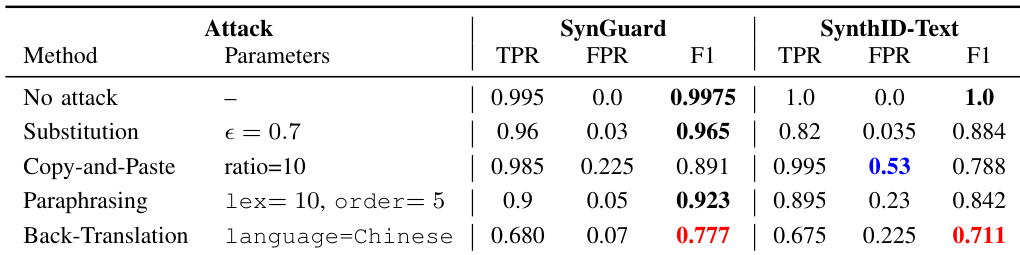
该表格对比了 SynGuard 与 SynthID-Text 在无攻击、同义词替换、复制粘贴、改写及回译等多种攻击场景下的性能表现。SynGuard 在所有攻击类型中的 F1 分数均高于 SynthID-Text,尤其在回译场景下保持了显著更优的检测准确率。SynthID-Text 在无攻击时表现强劲,但在复杂保义攻击下性能显著衰退,特别是在复制粘贴比例较高或回译使用中文时。SynGuard 在所有攻击类型中的检测准确率均优于 SynthID-Text,特别是在回译与改写场景下。SynthID-Text 在复制粘贴攻击下性能大幅下滑,伴随高假阳性率与低 F1 分数。SynGuard 在回译条件下维持稳健检测,其 F1 分数高于出现显著性能下降的 SynthID-Text。
实验评估了 SynthID-Text 与 SynGuard 对多种文本编辑与回译攻击的鲁棒性,同时考察了语义权重参数对检测性能的影响。定性分析表明,SynGuard 在所有对抗场景下均能持续保持高检测准确率,而 SynthID-Text 则出现显著性能衰退,尤其是在重翻译与高比例复制粘贴操作下。这些攻击的有效性显著受中转语言与翻译模型选择的影响,其中日语与 Google Translate 能取得最有利的检测效果。最终,SynGuard 展现出对保义转换的卓越抵抗力,确立了其在复杂编辑条件下作为更可靠水印方案的地位。