Command Palette
Search for a command to run...
一键部署 Dia-1.6B
摘要
一句话总结
EmoSSLSphere 是一个多语言情感文本转语音框架,它使用离散的自监督 token 在连续球坐标系中编码情感。在英语和日语语料库上的评估表明,与基线模型相比,该框架在语音清晰度、频谱保真度、韵律一致性、自然度与情感表达力方面均有显著提升。
核心贡献
- 本文提出了 EmoSSLSphere,一种多语言情感文本转语音框架,通过在连续球坐标系中编码情感来增强跨语言合成的可控性。
- 该架构将这些可解释的球面情感向量与源自自监督学习的离散 token 特征相融合,实现了细粒度的情感控制和鲁棒的跨语言情感迁移。
- 在英语和日语语料库上的评估表明,该框架在语音清晰度、频谱保真度和主观自然度方面显著优于基线模型,同时消融实验验证了离散 token 融合的有效性。
引言
多语言情感文本转语音合成对于构建能够跨语言自然适配的表达性语音接口至关重要。现有方法通常依赖显式的情感标签或单语言球面向量模型,这些方法往往难以捕捉细粒度的韵律细微差别,容易导致跨语言情感漂移,或损害说话人身份特征。本文利用球面情感向量将情感状态映射到可解释的连续空间中,并将其与源自自监督学习的离散 token 相结合。该架构将情感调制与特定语言的声学模式解耦,在保持自然韵律和说话人一致性的同时,实现了精确的情感控制和鲁棒的跨语言迁移。
数据集

-
数据集构成与来源: 本文使用英语和日语的单说话人情感语音语料库对模型进行评估,以隔离韵律和情感建模的影响,并刻意避免说话人适配或跨说话人微调。
-
子集详情:
- 英语:80 条语音片段,源自情感语音数据集(ESD),平均分为愤怒、悲伤、快乐和惊讶四类情感,每类 20 条,均由同一位女性说话人录制。
- 日语:60 条语音片段,源自 JVNV 语料库,平均分为愤怒、悲伤、快乐、惊讶、厌恶和恐惧六类情感,每类 10 条,同样由同一位女性说话人录制。
-
数据使用与处理: 训练流程严格区分评估样本与训练样本,以防止数据泄露。在推理阶段,真实语音片段被用作参考语音,且来源说话人与语言与目标合成内容保持一致。
-
其他处理详情: 提供的文档未明确说明裁剪策略、元数据构建或混合比例,而是强调严格的说话人隔离与清晰的数据集划分。
方法
本文针对 EmoSSL-Sphere 采用模块化架构,这是一种多语言情感文本转语音(TTS)框架,旨在解决跨语言整合语言、情感与声学特征的挑战。该系统围绕四个核心组件构建:情感风格与强度编码器、基于 SSL 的特征编码器、文本编码器以及梅尔频谱图解码器。这些模块独立运行以提取互补的语音特征,其嵌入向量随后被融合以条件化解码器。整体框架支持独立编码器的预训练以及后续解码器的微调阶段,确保了架构的模块化与高效适配。
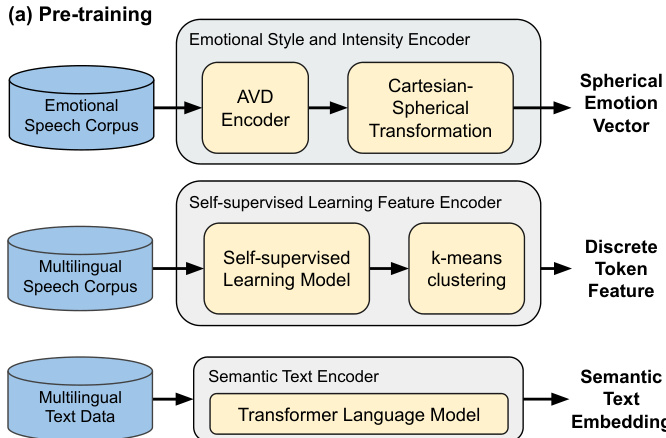
如图所示,预训练阶段包含三个独立的编码器。情感风格与强度编码器处理参考语音,利用预训练模型从梅尔频谱图中提取唤醒度-效价-支配度(AVD)向量。这些向量初始处于笛卡尔坐标系中,随后被转换为球坐标系 (r,θ,ϕ),以实现平滑插值和对情感强度的连续控制。为引入类别情感信息,离散的情感 ID 被嵌入为 one-hot 向量,并与球面 AVD 表示拼接,形成混合情感嵌入,将细粒度细微差别与显式风格先验相结合。基于 SSL 的特征编码器利用 HuBERT(一种在大规模语音数据上训练的自监督模型)来提取韵律线索。选择 12 层基础模型中第 9 层的隐藏状态,以在语音细节与高层语义之间取得平衡。这些连续特征随后通过特定语言的 k-means 聚类进行量化,生成离散的韵律 token,从而捕捉具有普遍性但略带语言特定性的节奏与音高模式。文本编码器包含两个并行分支:音素编码器通过强制对齐工具将输入文本转换为音素序列,以确保发音准确;语义编码器则采用 DeBERTaV3 生成更高层级的语义嵌入。这些语义嵌入通过交叉注意力机制条件化情感与韵律模块,并与其他嵌入拼接后作为解码器的输入。
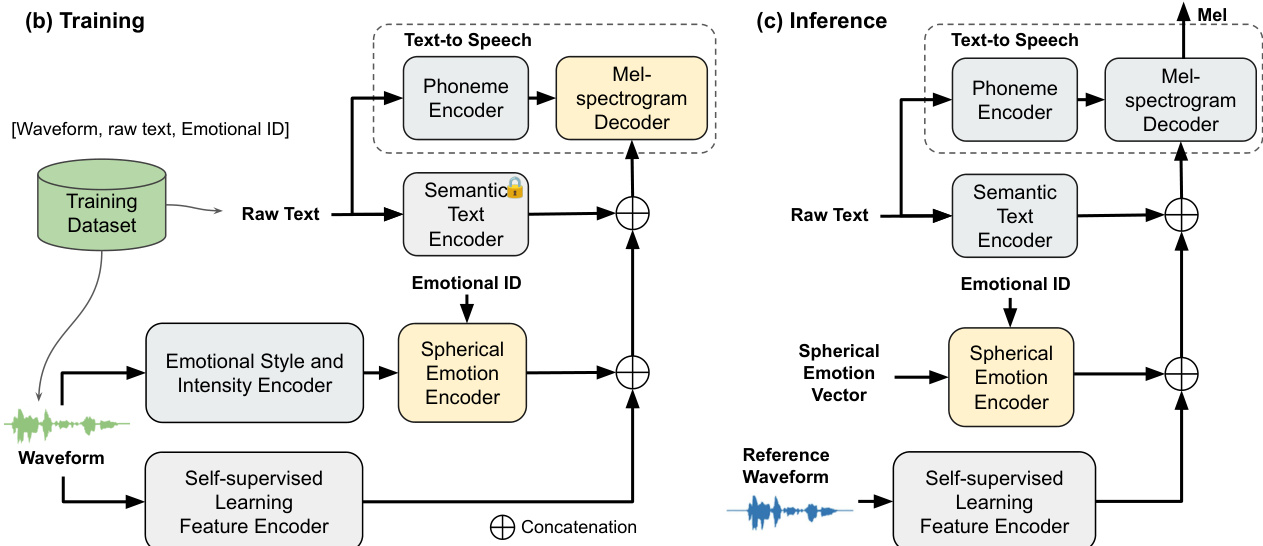
训练流程包含两个阶段。在预训练阶段,每个编码器独立训练:情感风格与强度编码器将 AVD 值转换为球面嵌入,基于 SSL 的特征编码器使用特定语言的 k-means 对 HuBERT 特征进行离散化,语义文本编码器则直接使用预训练的 DeBERTaV3 嵌入而无需进一步调整。在微调阶段,基于 FastSpeech2 的梅尔频谱图解码器使用配对的文本-波形数据进行训练,同时冻结所有编码器参数。输入嵌入(包括音素序列、球面情感向量、离散 SSL tokens、说话人嵌入和语义嵌入)被投影到共享的潜在空间中,拼接后通过线性映射以匹配解码器的输入维度。该融合机制使解码器能够有效整合语言、韵律、情感及说话人相关信息。推理阶段需要两个输入:目标文本与参考语音波形。参考语音提供情感与韵律线索,音素编码器则确保发音清晰可懂。说话人身份通过固定的说话人嵌入得以保留。融合后的嵌入被输入解码器,以生成具有表现力且说话人一致的语音。模型架构通过为每种语言实例化独立的编码器模块来支持多语言适配,从而避免跨语言干扰。
实验
评估将 EmoSSLSphere 与两个基线模型进行对比,并开展消融实验以验证其参考波形条件化、语义文本编码器及 SSL token 离散化模块的独立贡献。实验结果表明,该框架在英语和日语上均显著提升了语义一致性、声学保真度与感知自然度。定性分析进一步证实了其在保持鲁棒跨语言韵律完整性的同时,能够准确捕捉细粒度情感轮廓的能力。最终,这些发现验证了各集成组件协同工作,能够实现更优的情感控制与高质量的多语言语音合成。
本文在清晰度、声学质量、自然度与情感表达力等多个维度上对 EmoSSLSphere 与基线方法进行评估。结果显示,EmoSSLSphere 在大多数指标上均优于基线方法,尤其在情感表达力与声学保真度方面表现突出,且在英语和日语中均取得一致提升。EmoSSLSphere 在情感表达力方面超越基线方法,在英语和日语的情感特定指标上实现了更低的错误率。所提方法展现出更优的声学质量,其频谱与音高精度均高于基线方法。消融实验证实,EmoSSLSphere 的每个组件均对整体性能有显著贡献,尤其在维持自然度与情感可控性方面。

本文使用客观与主观指标,在清晰度、声学质量、自然度与情感表达力等多个维度上对 EmoSSLSphere 与基线模型进行评估。结果显示,EmoSSLSphere 在大多数指标上优于基线,尤其在自然度与情感控制方面,且在英语和日语中均保持一致的提升。消融实验进一步证实了参考波形条件化、语义文本编码及离散 SSL token 离散化等关键组件的重要性。在英语和日语中,EmoSSLSphere 均获得了最高的自然度评分与最低的声学失真度。该模型展现出更优的情感表达力,其较低的 AVD RMSE 值表明对情感韵律的控制更为精准。消融实验证实,移除参考波形条件化或语义文本编码等关键组件会导致性能显著下降。
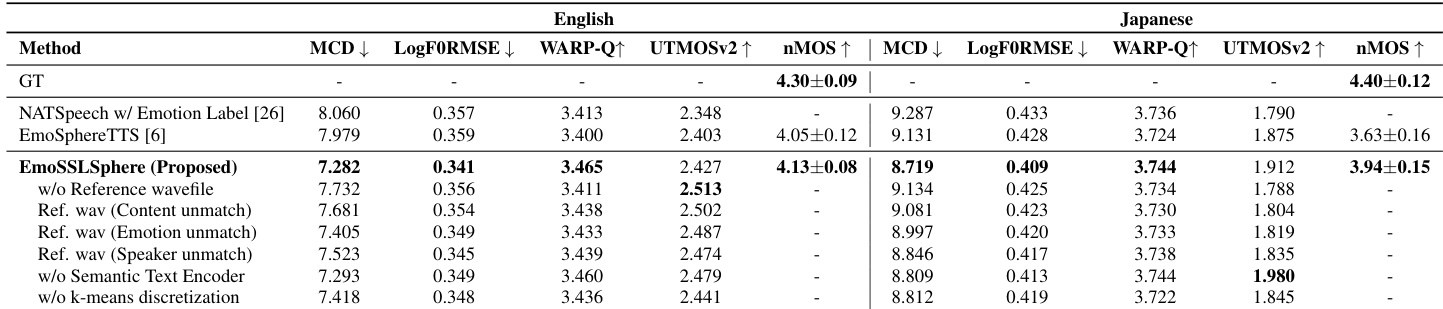
本文在清晰度、声学质量、自然度与情感表达力等多个维度上对 EmoSSLSphere 与基线方法进行评估。结果显示,EmoSSLSphere 相比基线方法取得了更优的性能,尤其在降低错误率与提升语义及韵律保真度方面,且在英语和日语中均获得一致增益。消融实验进一步展示了模型设计中每个组件的重要性。EmoSSLSphere 在清晰度方面超越基线方法,在英语和日语中均实现了更低的错误率与更高的语音质量指标。所提模型通过实现更低的 AVD RMSE 值展现出改进的情感表达力,表明其情感控制精度优于基线方法。消融实验证实,参考波形条件化与语义文本编码等关键组件对于维持韵律与情感保真度方面的高性能至关重要。

本文在英语与日语语音上,将 EmoSSLSphere 与成熟的基线模型进行对比,评估其清晰度、声学质量、自然度与情感表达力。实验表明,所提框架在保持高语音自然度的同时,凭借更优的声学保真度与更精准的情感控制,持续超越基线方法。消融实验进一步验证了架构设计的合理性,证实参考波形条件化与语义文本编码等核心组件对于保留韵律准确性与情感可控性不可或缺。总体而言,这些发现确立了 EmoSSLSphere 作为一种稳健方案,可实现高保真、具情感表现力的多语言语音合成。