Command Palette
Search for a command to run...
一键部署 MuseV
摘要
一句话总结
作者提出了 S2VG,这是一种免训练的框架,利用现成的单目视频生成器,通过去噪帧矩阵修复技术,并结合未遮挡边界重注入机制,生成 3D 立体视频和空间视频。在 Sora、Lumiere、WALT 和 Zeroscope 的视频评估中,该方法相比以往方法取得了显著的性能提升。
核心贡献
- 提出了一种免相机位姿估计且免训练的框架,通过复用现成的单目视频生成模型来合成沉浸式 3D 与立体视频。该方法摒弃了显式的相机位姿估计与微调步骤,直接将标准单目输出转换为可适配立体对视或 4D 高斯分布的多视角空间内容。
- 提出了一种创新的帧矩阵修复框架,利用估计的深度信息将生成的单目帧扭曲至预设视点,从而在空间与时间维度上合成缺失内容。该流程整合了未遮挡边界重注入方案与先外扩后修复的设计,以解决遮挡伪影并保留完整的物体结构。
- 通过在 Sora、Lumiere、WALT 和 Zeroscope 的输出结果上进行实验验证了该方法的有效性,证明了其在空间与时间一致性及视觉质量方面,相比现有的立体与空间视频合成技术均实现了稳定提升。
引言
VR 与 AR 应用的快速发展催生了对高保真立体视频和空间视频的强烈需求,这类视频需在多视角下保持严格的几何与时间一致性。尽管单目视频生成已取得显著进展,但现有的 3D 合成技术主要依赖基于重建的新视角合成,该方法存在相机位姿估计不稳定,且无法真实合成遮挡或未遮挡区域的问题。为克服这些局限,作者提出了一种免位姿估计且免训练的框架,通过复用现成的单目视频扩散模型来实现沉浸式 3D 内容的创建。该方法将初始帧扭曲至虚拟视点,并引入帧矩阵表示法,在去噪过程中联合优化空间与时间一致性。此外,研究团队实施了未遮挡边界重注入方案以消除潜在空间伪影,并将生成序列优化为动态 4D 高斯分布,从而在无需显式相机位姿追踪的情况下实现无缝的新视角合成。
方法
所提出的立体与空间视频生成方法采用免训练流程,利用现成的深度估计器与预训练的单目视频扩散模型。该框架首先基于文本提示或单张图像,使用视频扩散模型生成左视单目视频。为在保持 3D 一致性的同时生成对应的右视图,系统首先从左视视频中估计深度信息。随后利用该深度信息执行立体扭曲操作,生成初始右视序列及其关联的未遮挡掩码。未遮挡区域随后通过基于扩散的修复过程进行补全,合成合理的内容以输出最终的右视视频。
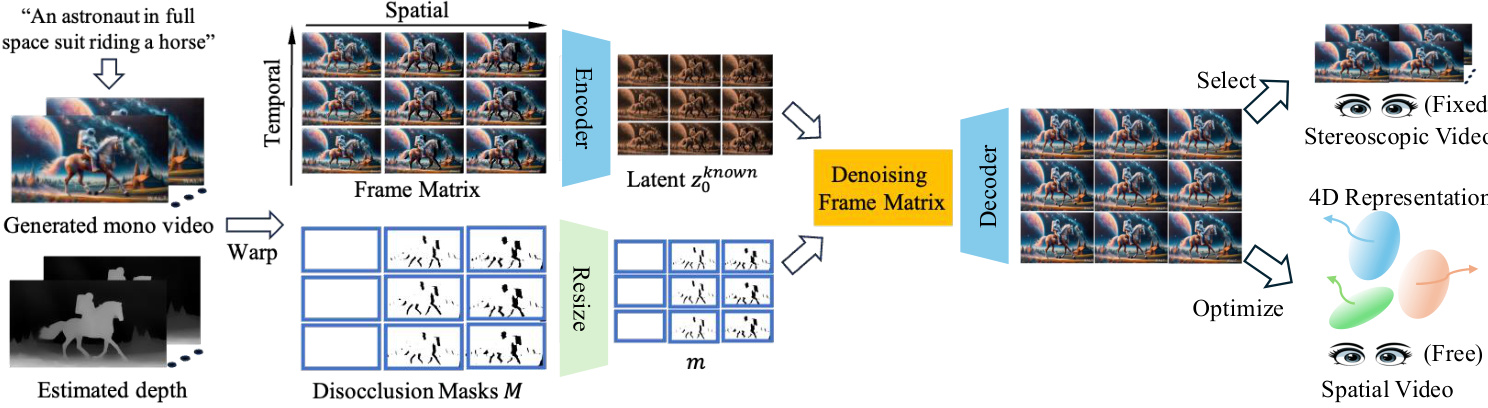
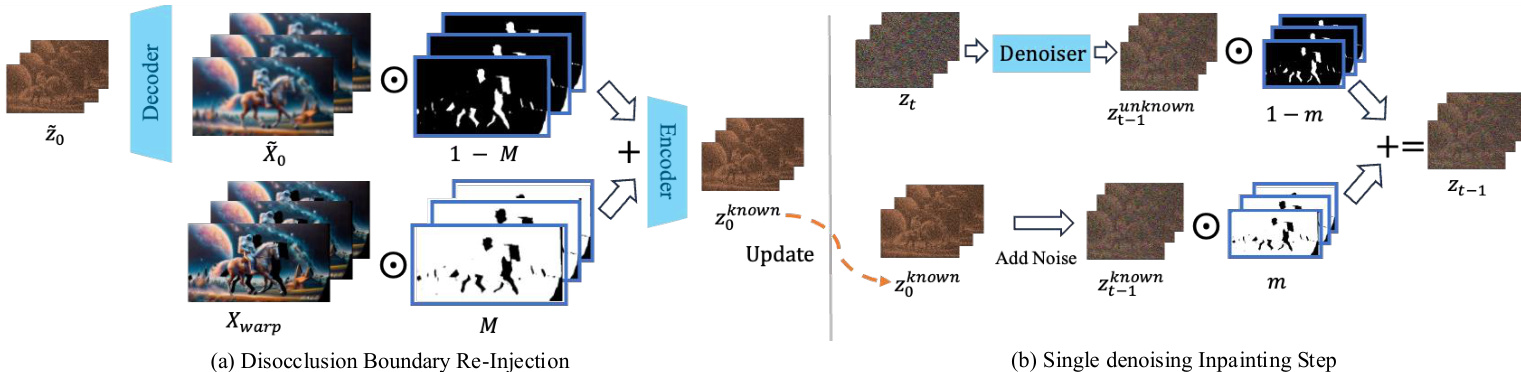
该框架的核心是一种创新的帧矩阵表示法,旨在同时提升空间与语义一致性及时间一致性。该表示法将扭曲后的视频帧组织为二维数组,其中每一行对应同一时间戳下捕获的多个相机视角,每一列则表示固定相机视角下的帧时间序列。此结构支持对空间与时间序列进行联合去噪。去噪过程以交替方式进行,扩展了重采样机制,对列序列(时间维度)和行序列(空间维度)多次执行去噪。在每一步去噪中,已知区域的潜在特征得以保留,未知区域则使用视频扩散模型进行去噪。该迭代过程确保了生成内容在空间与时间上保持一致。

为解决扭曲过程引入的伪影(如孤立像素与裂缝),该方法采用多平面投影技术。该策略将相机视场空间划分为按深度分层的离散平面,从而自然分离前景与背景元素。通过掩码图像与 3×3 卷积核进行卷积来检测并移除孤立像素,同时利用局部像素插值识别并填充裂缝。处理后的平面随后通过从后往前的混合方式合成最终的扭曲图像。若单目视频包含部分可见物体,则在扭曲前应用视频外扩步骤以延伸可见内容。
提升修复结果质量的关键组件是未遮挡边界重注入机制。该策略解决了因 VAE 编码器对潜在特征进行下采样而导致未遮挡区域边界特征损坏的问题。该方法预测去噪后的潜在特征,将其解码为视频,随后用扭曲后的像素替换未遮挡区域。生成的合成视频被重新编码以获得更新的潜在表示,并用于后续的去噪迭代。此细化步骤显著减少了伪影,并提升了生成内容的保真度。
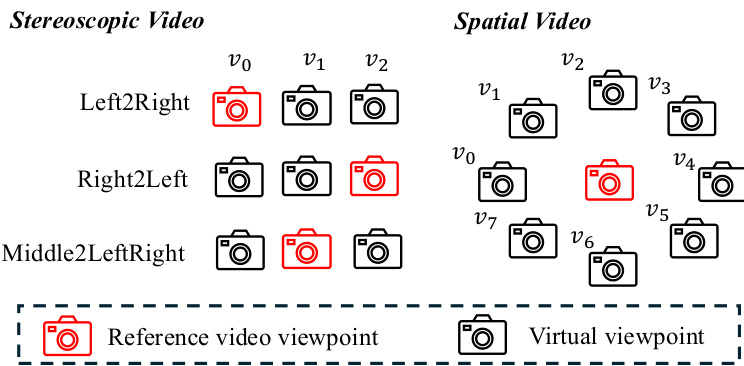
最后,该框架从修复后的帧矩阵中提取立体与空间视频。对于立体视频,选取帧矩阵的最左列与最右列分别代表左眼与右眼视角。对于支持连续视角变化的空间视频,生成的多视角观测数据被优化为 4D 表示,具体采用可变形高斯溅射(Deformable Gaussian Splatting)。该优化过程在规范空间中学习一组 3D 高斯分布,其位置与外观通过时间依赖的偏移量建模为动态实体,从而实现连续且一致的视频合成。
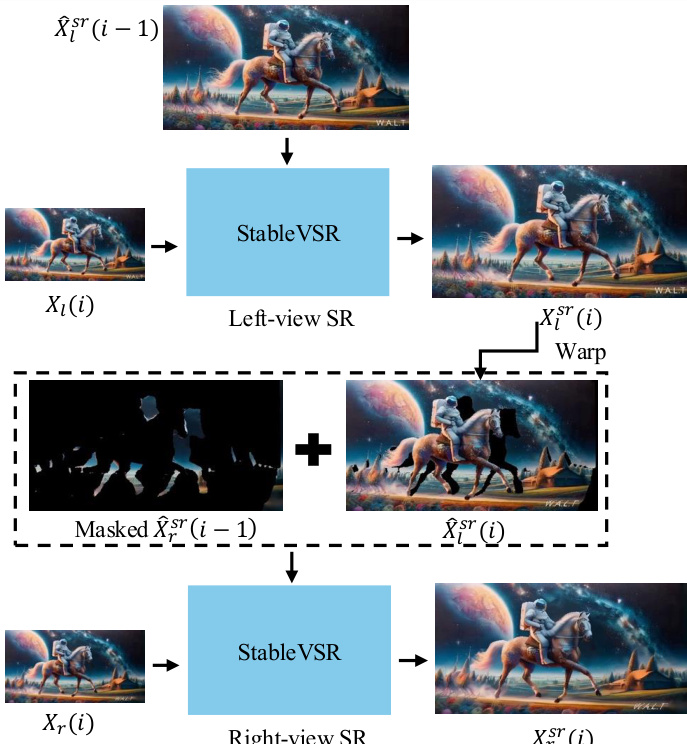
系统还实现了一种可选的立体视频超分辨率方案。该流程采用预训练的单目视频超分辨率模型。左视视频通过前一超分帧的时间条件进行上采样,以确保帧间一致性。相比之下,右视上采样同时结合了时间条件与来自超分左视帧的跨视角条件,以维持立体一致性。该方法确保了最终立体视频在时间上稳定且空间上一致。
实验
评估设置针对立体与空间视频生成任务,将所提方法与多种视频修复、新视角合成及立体专用基线方法进行了对比测试。定性评估表明,该方法在未遮挡区域持续生成清晰且时间一致的内容,有效克服了限制现有技术的模糊伪影、位姿不稳定与视角不一致问题;消融实验则证实,帧矩阵与深度平滑等关键组件对维持语义对齐至关重要。最终,该方法被证明在无需依赖显式相机位姿或刚性立体约束的情况下,生成逼真立体与 4D 视频方面具有显著有效性。
作者开展实验以评估其立体与空间视频生成方法,并将其与包括视频修复与新视角合成在内的多种基线进行对比。结果表明,该方法在语义一致性、视频质量与人类感知方面均优于现有方法,尤其在维持时间一致性及在未遮挡区域生成清晰合理的内容方面表现突出。消融实验验证了帧矩阵与未遮挡边界重注入等关键组件的有效性。与基线方法相比,所提方法在语义一致性与视频质量上取得更优性能,CLIP 特征相似度与美学指标得分均更高。消融实验进一步确认,帧矩阵与未遮挡边界重注入对维持语义连贯性及在未遮挡区域生成高质量结果至关重要。在人类感知评估中,该方法优于现有方案,展现出更佳的立体效果、时间一致性与整体体验,尤其在对比单图视角合成与视频修复基线时优势明显。

作者针对空间视频生成任务,将所提方法与基线方案进行了对比评估,重点考察视频质量指标。结果显示,该方法在所有测量指标上均表现优异,相较于基线方案具有更高的美学质量、更好的视频一致性及改进的生成保真度。评估基于从优化后的 4D 场景中渲染视频,并采用既定定量指标进行衡量。所提方法在空间视频生成的所有评估指标上均优于基线。该方法实现了更高的美学质量与视频一致性。结果证明,FVD 指标所测得的视频保真度得到提升。
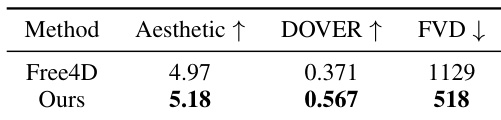
作者结合人类感知研究与客观指标,对立体视频生成任务中的多种基线方法进行了全面评估。结果表明,该方法在立体效果、时间一致性与整体体验等关键方面均优于现有方法,同时实现了更优的语义对齐与视频质量。该方法在不同配置下展现出良好的鲁棒性,并有效维持了空间与时间域的一致性。所提方法在所有人类感知指标(包括立体效果、时间一致性、图像质量与整体体验)上均获得最高分。在 CLIP 特征相似度以及美学评分、DOVER 与 FVD 等既定指标衡量下,该方法在语义一致性与视频质量上超越基线。消融实验证实,帧矩阵、未遮挡边界重注入与扭曲处理等关键组件对维持一致性并减少伪影具有重要意义。

作者通过对比分析与人类感知研究,将所提立体与空间视频生成方法与多种基线方案进行了评估。这些实验验证了模型在有效重建未遮挡区域的同时,维持强语义对齐、时间一致性与逼真立体效果的能力。消融实验进一步证实,特定的架构组件,尤其是帧矩阵与未遮挡边界重注入,对保留视觉一致性并减少伪影至关重要。总体而言,该方法始终优于现有技术,凭借更优的美学质量与更具沉浸感的观看体验脱颖而出。