Command Palette
Search for a command to run...
SGDFuse:用于高保真红外与可见光图像融合的SAM引导扩散模型
SGDFuse:用于高保真红外与可见光图像融合的SAM引导扩散模型
Xiaoyang Zhang Jinjiang Li Guodong Fan Yakun Ju Linwei Fan Jun Liu Alex C. Kot
一键部署 IC-Light
摘要
红外与可见光图像融合(IVIF)对于整合热显著性与纹理细节以支持下游感知至关重要。然而,大多数现有方法存在“语义盲点”问题,导致错误抑制热目标并引入视觉伪影。为解决这一问题,我们提出了SAM引导的扩散融合网络(SGDFuse),这是一种新颖的语义引导生成(SGG)框架,将IVIF重构为一种受语义驱动的生成任务,而非简单的像素映射。我们的方法独特地将来自分割一切模型(Segment Anything Model, SAM)的高级语义先验与条件扩散模型的高保真生成能力相结合。我们采用了一种精心设计的两阶段策略,以解耦多模态对齐与迭代细化过程:第一阶段通过初步融合建立稳健的结构基础;第二阶段利用双模态语义掩码作为空间锚点,引导扩散过程实现语义一致且高保真的重建。全面的实验表明,SGDFuse不仅提供了最先进的图像质量,还提升了下游任务的性能,证实了其作为语义感知图像融合新方法的有效性。
一句话总结
SGDFuse 通过将 Segment Anything Model 先验与条件扩散网络相结合,解决了传统红外与可见光图像融合中的语义盲区问题。该方法采用两阶段策略,首先建立结构对齐,随后利用双模态语义掩码作为空间锚点指导迭代优化,最终生成高保真且语义连贯的图像,从而提升下游任务的性能。
核心贡献
- 提出 SGDFuse,一种语义引导生成框架,将红外与可见光图像融合重构为语义驱动的生成任务,以缓解传统像素映射方法中普遍存在的语义盲区与视觉伪影问题。
- 提出一种解耦的两阶段架构,并集成闭环引导系统,利用 Segment Anything Model 掩码作为显式空间锚点,引导条件扩散模型实现高保真且语义连贯的重建。
- 通过大量实验证明,该框架达到了最先进的图像质量水平,并在包括目标检测与语义分割在内的下游感知基准测试中显著提升了性能。
引言
红外与可见光图像融合对于结合热显著性与丰富的视觉纹理至关重要,能够在自动驾驶和医学诊断等关键应用中实现稳健的环境感知。然而,现有方法通常将融合视为低层像素映射过程,导致语义盲区、目标边界模糊以及关键热特征的误抑制。为应对这些挑战,研究团队利用 Segment Anything Model 提取显式语义掩码,并将其集成至条件扩散框架中。所提出的 SGDFuse 网络将图像融合重构为语义引导的生成任务,采用两阶段架构,首先建立结构先验,随后利用双模态掩码指导迭代优化。该闭环引导系统在确保高保真重建的同时保留任务关键信息,显著提升了下游视觉任务的性能。
数据集
研究团队使用四个红外与可见光图像数据集对提出的模型进行评估,每个数据集均针对不同的场景条件与分辨率进行选择。该数据集集合包含以下子集:
- MSRS:640×480 分辨率下的 361 对测试图像
- M³FD:1024×768 分辨率下的 4,164 对图像
- LLVIP:1280×1024 分辨率下的 16,836 对图像
- RoadScene:221 对已配准的红外-可见光图像
在实验设置中,研究团队主要依赖这些数据集进行模型评估。文中明确了 MSRS、M³FD 和 LLVIP 的测试集划分,而 RoadScene 则作为完整的已配准图像集使用。本节未提及任何训练集划分、混合比例或数据增强流程。数据处理方面,直接使用原始的已配准图像对,未应用额外的裁剪、元数据构建或过滤规则。所有数据集均可在请求时向作者获取。
方法
提出的 SGDFuse 框架采用两阶段架构,旨在通过将结构对齐与生成优化解耦来实现高保真多模态图像融合。整体流程始于从红外(IR)与可见光(VIS)输入中提取互补特征。在第一阶段,IR 图像通过多尺度特征增强模块(MSFEM)进行处理,该模块采用并行卷积结构,配备不同感受野的卷积核(1×1, 3×3, 5×5, 7×7)以捕获多尺度结构细节。较大卷积核提取的特征经过一系列深度卷积与逐点卷积增强后,与 1×1 分支的浅层特征进行融合。该融合表示随后通过通道注意力机制与残差连接进行优化,生成增强后的 IR 特征图。与此同时,VIS 图像由 Transformer 块(TB)编码,利用多头自注意力机制提取全局上下文与细粒度纹理信息。随后,双模态特征通过交叉注意力路径进行对齐与选择性融合,生成初始融合图像,该图像整合了来自 IR 的显著热目标与来自 VIS 的高分辨率纹理细节。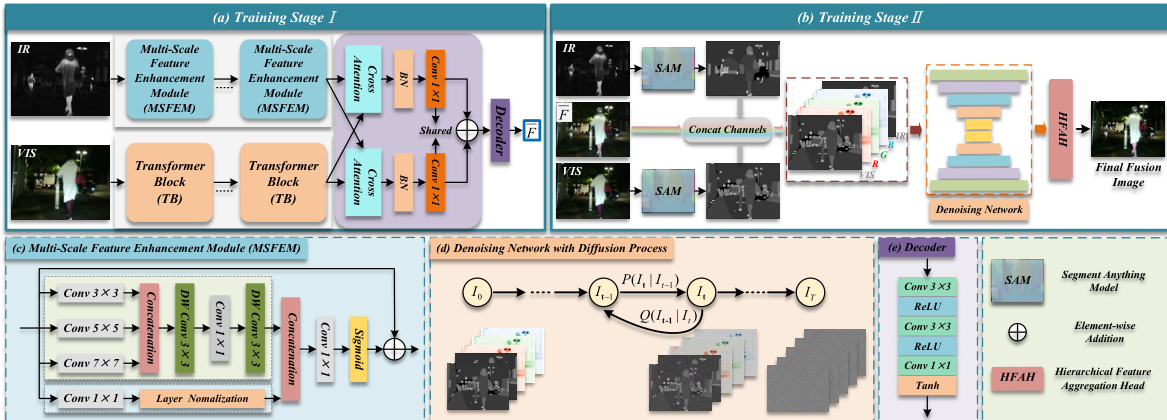
在第二阶段,初始融合图像通过条件扩散模型进行优化,以增强结构保真度与语义一致性。该框架利用 Segment Anything Model (SAM) 为 IR 与 VIS 图像生成高质量语义掩码。这些掩码随后与初始融合图像拼接,形成五通道输入,为扩散过程创建任务感知引导信号。扩散模型首先在一组时间步内使用高斯噪声扰动该五通道输入,逐步将图像转化为标准高斯分布。随后,反向过程在语义掩码的引导下学习对该扰动图像进行去噪,从而重建高保真融合图像。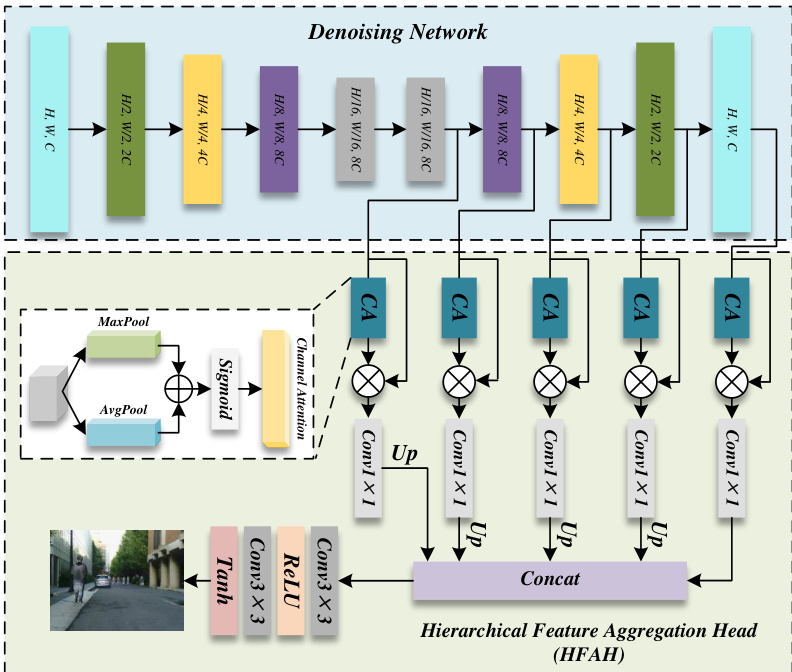
扩散过程的核心是基于 U-Net 架构的去噪网络。该网络包含收缩路径与扩展路径,前者对输入进行下采样以提取深层特征,后者恢复空间分辨率。网络接收由三通道融合图像与两个语义掩码组成的五通道输入,并估计每个时间步添加的噪声。反向扩散过程对输入进行迭代去噪,网络预测条件高斯分布的均值,最终生成最终融合图像。为进一步提升重建图像质量,解码路径中集成了分层特征聚合头(HFAH)。HFAH 聚合多层解码特征,并引入空间注意力机制以联合优化结构细节与语义一致性。聚合后的特征被拼接并通过由多个 3×3 卷积层组成的融合头,生成最终的三通道融合图像。输出端应用 Tanh 激活函数以增强纹理连续性与细部表达。整个框架采用任务特定损失函数的组合进行训练。在第一阶段,损失函数由强度损失与梯度损失组合而成,以确保初步融合图像与可见光图像结构对齐,并保留红外图像的热信息。在第二阶段,损失函数包含掩码引导的强度损失与掩码引导的梯度损失,分别应用于语义掩码定义的显著区域内,以增强亮度一致性与边缘清晰度。该两阶段方法有效缓解了跨模态特征提取与高保真重建之间的冲突,最终生成具有优异结构与语义质量的融合图像。
实验
通过在多个可见光-红外、医学及下游视觉数据集上与众多基线方法进行评估,实验设置验证了该框架的整体融合质量、计算效率与架构鲁棒性。定性评估与消融研究证实,两阶段设计有效分离了结构对齐与生成优化,且语义引导与扩散建模在复杂环境中持续保持热目标、细粒度纹理与感知一致性。鲁棒性与泛化能力测试进一步验证了该方法对分割误差的抵抗力及其对替代语义先验的适应性,即使在输入不完美的情况下也能展现可靠性能。综上所述,这些实验共同表明,该框架在高保真融合、实际推理速度以及下游视觉任务的跨领域适用性之间取得了卓越的平衡。
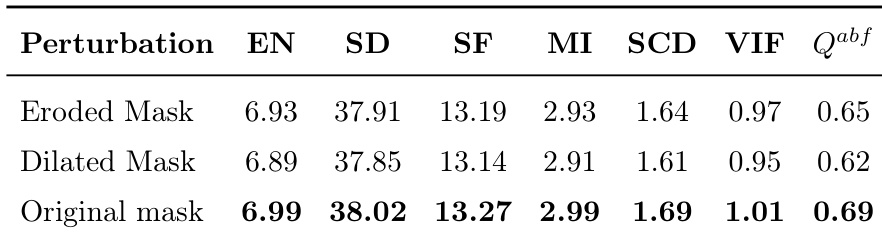
研究团队通过评估腐蚀与膨胀掩码对融合性能的影响,分析了方法对语义先验扰动的鲁棒性。结果表明,尽管扰动导致指标出现可测量的下降,模型仍保持高性能与结构保真度,显示出对分割误差的抵抗力。原始掩码配置在所有评估指标上均取得最佳整体结果。即使在语义掩码受到扰动的情况下,模型仍维持高性能,表现出对分割误差的鲁棒性。随着掩码扰动加剧,性能呈逐渐下降趋势,表明该框架对先验误差不过度敏感。原始掩码配置在所有指标上获得最高得分,证明了其最优的语义引导效果。
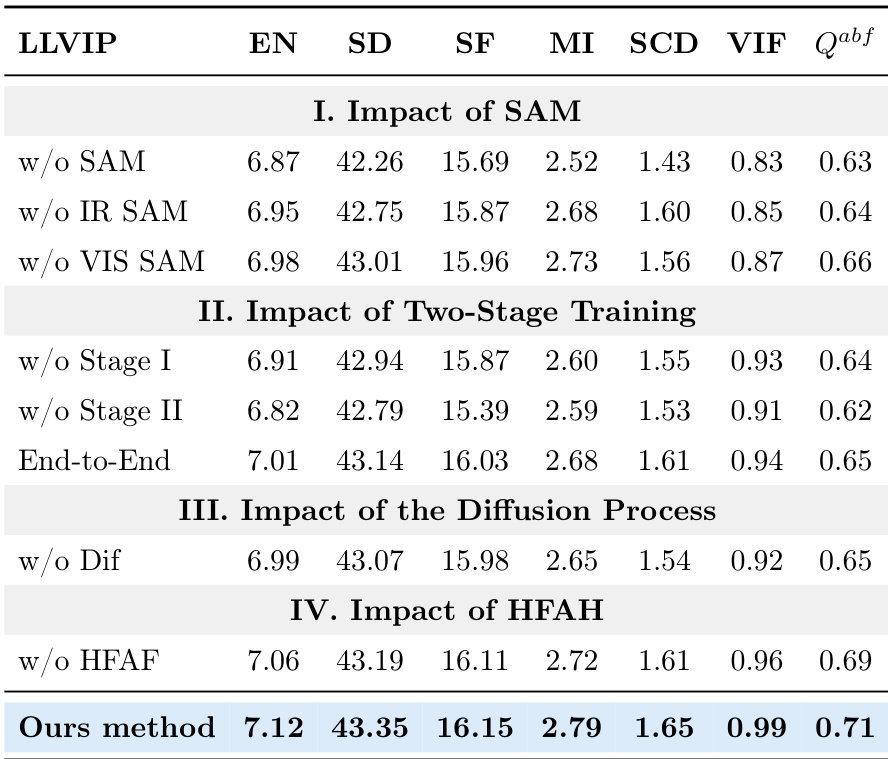
该表格展示了在 LLVIP 数据集上的消融实验结果,评估了所提方法中关键组件的影响。结果表明,移除语义引导、两阶段训练、扩散过程或分层特征聚合均会导致多项指标性能下降。完整方法在所有评估指标上均取得最高分数,证明了各组件的有效性。移除语义引导(SAM)会导致所有指标性能低于完整方法。两阶段训练方法在所有评估指标上均优于单阶段替代方案。扩散过程与分层特征聚合至关重要,因为移除它们会导致性能显著下降。
研究团队在 MSRS 数据集上使用目标检测指标,将所提方法与多种最先进的融合方法进行了对比。结果表明,该方法在大多数类别中取得了最高性能,尤其在背景与车辆检测方面表现突出,显示出更优的结构保真度与语义一致性。评估结果凸显了其在复杂场景中的高检测精度与鲁棒性。该方法在大多数类别中实现了最高的检测精度,尤其是在背景与车辆检测方面。所提方法在平均交并比(mean IoU)上超越所有基线,证明了其卓越的结构保真度与语义一致性。与其他方法相比,该方法在复杂场景中保持了更清晰的边界与更完整的轮廓。
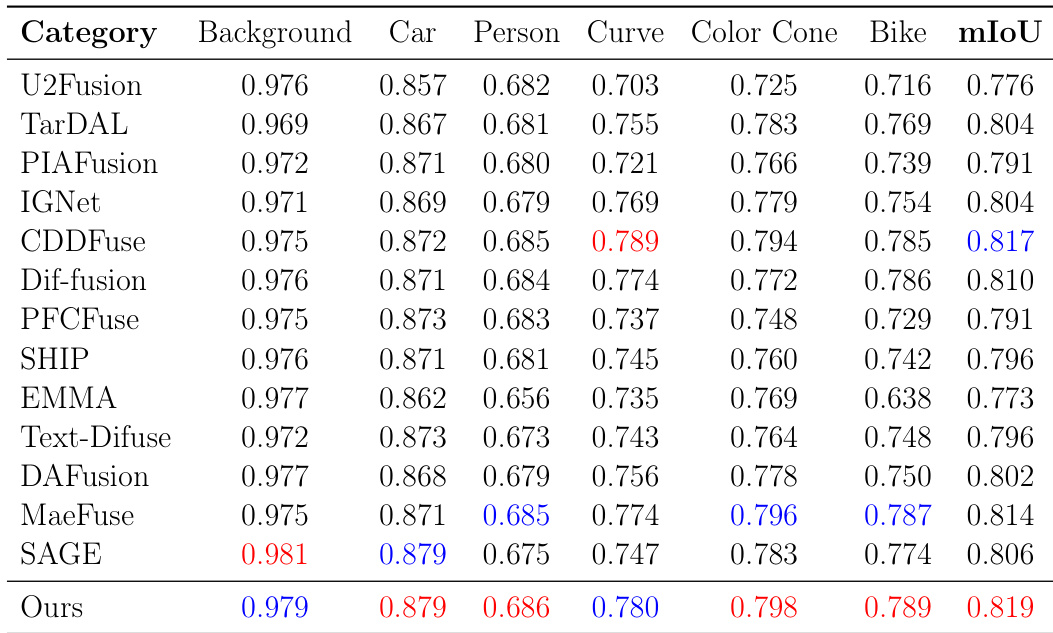
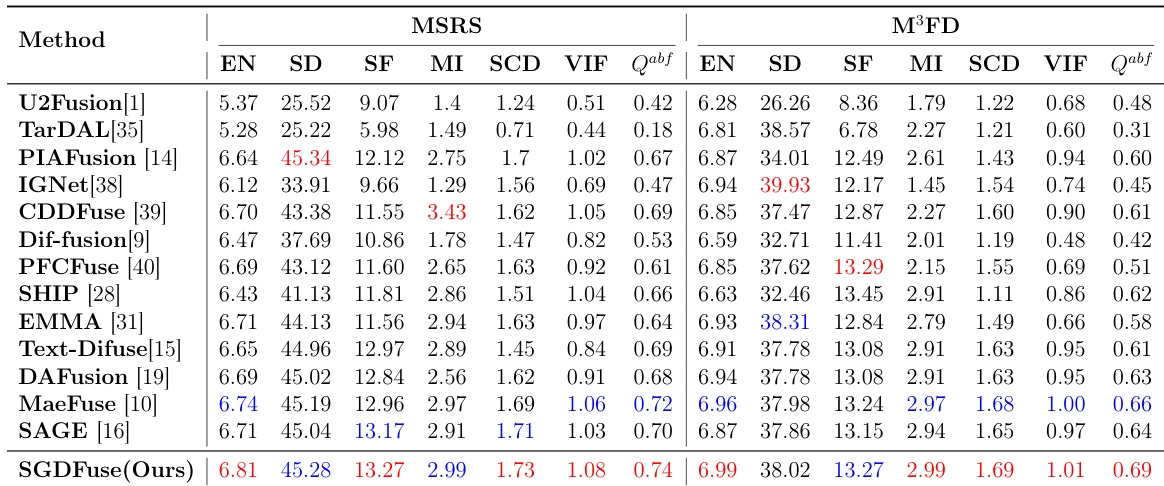
研究团队在包括 MSRS 与 M3FD 在内的多个基准数据集上,对提出的 SGDFuse 方法与多种最先进的融合方法进行了评估。结果表明,SGDFuse 在这两个数据集的多数指标上均取得了最佳性能,相较于现有方法展现出更优的图像质量、结构一致性与感知保真度。该方法表现出强大的泛化能力与鲁棒性,尤其在低光照场景与复杂交通环境等挑战性条件下。SGDFuse 在多个数据集的多数指标上实现最佳性能,表明其具有卓越的融合质量与结构一致性。该方法展现出强劲的泛化能力,在低光照条件与复杂交通环境等多样化场景中表现优异。SGDFuse 在目标检测与语义分割等下游视觉任务中优于现有方法,证明了其实际应用价值。
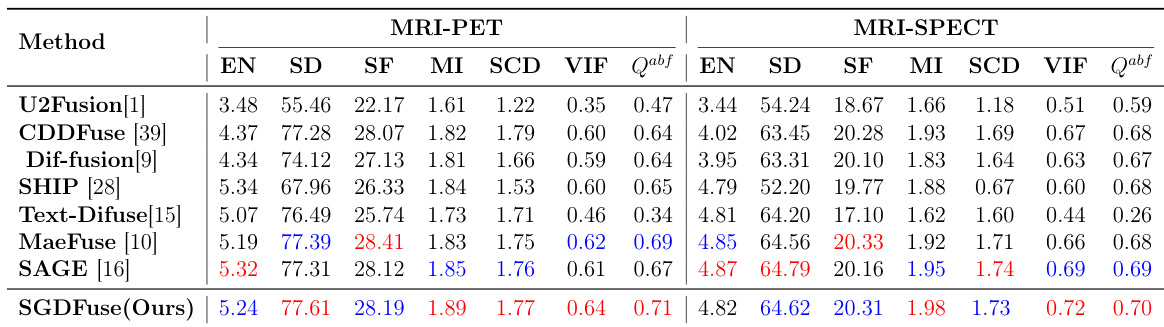
研究团队在医学图像融合数据集上评估了所提方法,并将其与多种先进方法进行了对比。结果表明,该方法在多项指标上取得了最佳或接近最佳的性能,显示出强大的泛化能力,以及在医学成像应用中保留结构细节与提升图像质量方面的有效性。该方法在 MRI-PET 与 MRI-SPECT 数据集的关键指标上均取得领先性能。它在保留精细结构与提升整体图像质量方面优于竞争方法。结果证明了该方法在可见光-红外融合之外的医学图像融合领域具有稳健的泛化能力。
评估工作涵盖了对语义掩码扰动的鲁棒性测试、全面的消融研究,以及在可见光-红外与医学成像基准上的对比分析。这些实验验证了所提框架即使在分割存在误差的情况下,仍能保持高结构保真度与语义一致性,同时证实了各架构组件对实现最优性能不可或缺。在多样化的数据集与下游任务中,该方法始终优于现有先进替代方案,展现出卓越的融合质量、在挑战性环境中的稳健泛化能力,以及对医学成像等专业领域的强大适应性。