Command Palette
Search for a command to run...
AR-RAG:用于图像生成的自回归检索增强
AR-RAG:用于图像生成的自回归检索增强
Jingyuan Qi Zhiyang Xu Qifan Wang Lifu Huang
一键部署 InfiniteYou:高保真图像生成 Demo
摘要
我们提出了自回归检索增强(Autoregressive Retrieval Augmentation, AR-RAG),这是一种新颖的范式,通过在补丁(patch)级别以自回归方式融合k近邻检索结果来增强图像生成能力。与以往在生成前执行单次静态检索并将整个生成过程基于固定参考图像的方法不同,AR-RAG在每个生成步骤中进行上下文感知的检索,利用先前生成的补丁作为查询,检索并融合最相关的补丁级视觉参考,从而使模型能够响应不断变化的生成需求,同时避免现有方法中普遍存在的局限性(例如过度复制、风格偏差等)。为了实现AR-RAG,我们提出了两种并行框架:(1) 解码中的分布增强(Distribution-Augmentation in Decoding, DAiD),这是一种无需训练的即插即用解码策略,直接将模型预测补丁的分布与检索补丁的分布进行融合;(2) 解码中的特征增强(Feature-Augmentation in Decoding, FAiD),这是一种参数高效的微调方法,通过多尺度卷积操作逐步平滑检索补丁的特征,并利用这些特征来增强图像生成过程。
一句话总结
作者提出 AR-RAG,这是一种自回归图像生成框架,将静态的预生成检索替换为每个生成步骤中基于上下文感知的图块级 k 近邻检索,通过免训练的 DAiD 分布合并策略或参数高效的 FAiD 微调方法实现,以缓解过度复制和风格偏差问题。
核心贡献
- 自回归检索增强(AR-RAG)通过在每个解码步骤执行基于上下文感知的图块级 k 近邻检索来增强图像生成,而非依赖静态的预生成参考。这种动态方法能够适应不断演变的生成状态,并缓解过度复制和风格偏差等局限性。
- 两种并行解码框架实现了该范式。解码分布增强(DAiD)在不进行额外训练的情况下,使用逆距离加权将原生图块分布与检索到的图块合并;而解码特征增强(FAiD)则通过参数高效的多尺度卷积和兼容性评分来细化并融合检索到的特征。
- 在 Midjourney-30K、Geneval 和 DPG-Bench 基准上的实验表明,两种框架均以极小的计算开销提升了图像的连贯性与自然度。
引言
现代图像生成模型在生成逼真视觉内容方面表现出色,但经常难以处理结构不一致、复杂物体交互以及领域差异等问题。检索增强生成通过引入外部视觉参考来引导合成过程,从而应对这些挑战。然而,先前的方法依赖于在解码开始前对整张参考图像进行静态的、基于提示词的检索。这种固定策略无法适应不断演变的生成状态,往往会引入无关细节、风格偏差和视觉幻觉。为克服这些局限性,作者在整个生成过程中采用动态的图块级 k 近邻检索。通过将已生成的周围图块作为局部查询,系统从预建数据库中获取上下文相关的视觉 tokens,并通过两种并行策略进行整合。第一种是免训练的解码技术,将预测分布与检索到的图块合并;第二种是参数高效的微调流程,通过学习平滑操作来融合细化后的特征。这种自回归设计确保了精确且自适应的条件控制,在最小化计算开销的同时保留了局部语义连贯性。
数据集
- 数据集构成与来源: 作者构建了一个大规模的基于图块的检索数据库和专用的微调数据集,数据来源包括 CC12M、JourneyDB、DataComp 和 Midjourney-v6。
- 子集详情: 检索数据库包含 1360 万张图像,其中 570 万张来自 CC12M,330 万张来自 JourneyDB,460 万张来自 DataComp。微调数据集包含 5 万对图像-文本对,均匀分配,CC12M 和 Midjourney-v6 各 2.5 万样本。所有样本均经过严格过滤,排除任何出现在官方测试划分中的图像,以防止数据泄露。
- 处理与元数据构建: 使用 Janus-Pro 量化自编码器分词器将每张图像编码为 576 个图块特征及其对应的 tokens。检索数据库将每个图块向量索引为值,其键通过按从上到下、从左到右的顺序拼接其 h-跳周围邻居的向量生成。位于图像边界且缺少邻居的图块使用零向量填充,以保持键维度一致。作者利用 FAISS 库实现索引图块间的高效相似度搜索。
- 使用与训练设置: 在微调期间,通过检索与每个真实图块具有相似邻域关系的 top-K 数据库 tokens 来扩充 5 万对数据集。这种上下文增强数据用于微调 Janus-Pro-1B 和 Show-o 骨干网络。训练运行单个 epoch,全局批量大小为 256,使用 AdamW 优化器、10% 的线性预热调度以及 2e-4 的固定学习率。
方法
作者提出自回归检索增强(AR-RAG),该框架旨在通过在自回归生成过程中动态融入图块级视觉参考来增强图像生成。与在生成前执行单次静态检索的传统检索增强方法不同,AR-RAG 在每个生成步骤执行基于上下文感知的检索,利用已生成的图块作为查询以检索相关的视觉内容。这种自回归检索机制使模型能够适应不断变化的生成需求,缓解现有方法中常见的过度复制和风格偏差问题。
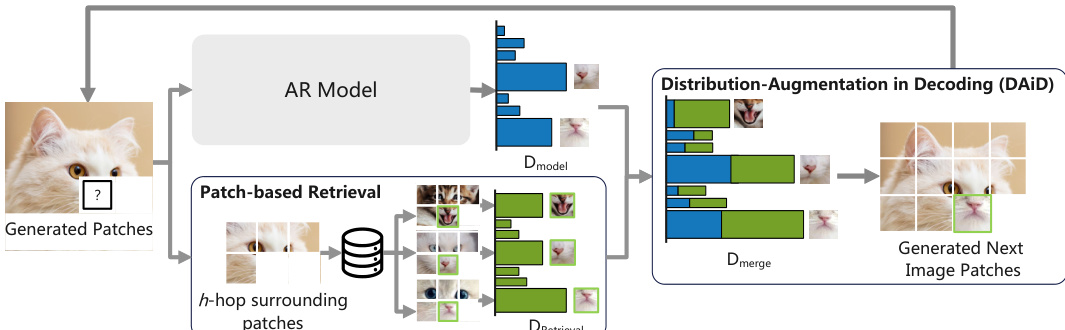
AR-RAG 的核心建立在两个互补框架之上:解码分布增强(DAiD)和解码特征增强(FAiD)。DAiD 是一种免训练、即插即用的策略,通过修改下一个图像 token 的概率分布,将检索到的图块信息直接整合到生成过程中。在预测下一个 token 时,DAiD 将当前位置的 h-跳周围图块作为查询,从预建数据库中检索 top-K 个最相似的图块表示。这些检索到的图块通过码本映射回离散的 token 索引,并通过在其 l2 距离上应用 softmax 构建基于检索的分布,该分布由检索温度进行缩放。随后,该分布与模型预测的分布通过加权平均进行合并,其中检索权重 λ 控制检索图块的影响。最终 token 从该合并分布中采样。
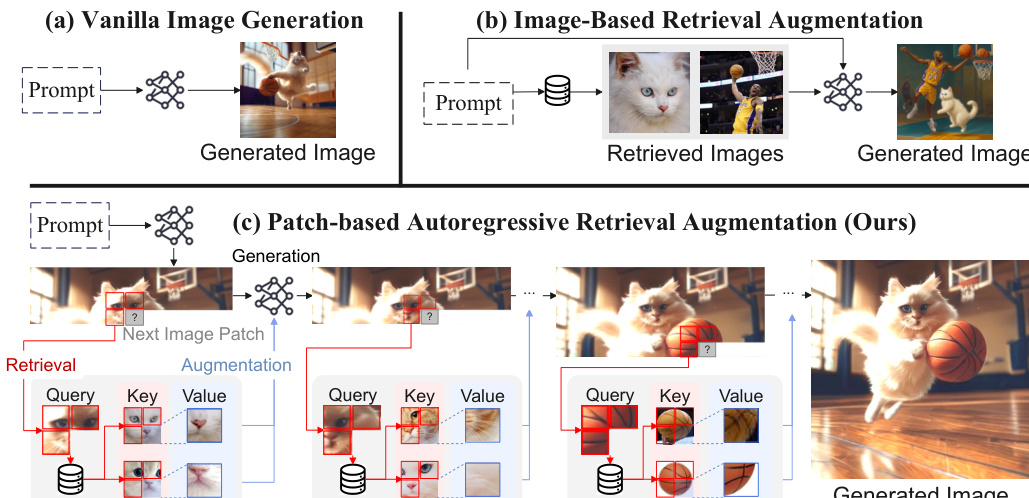
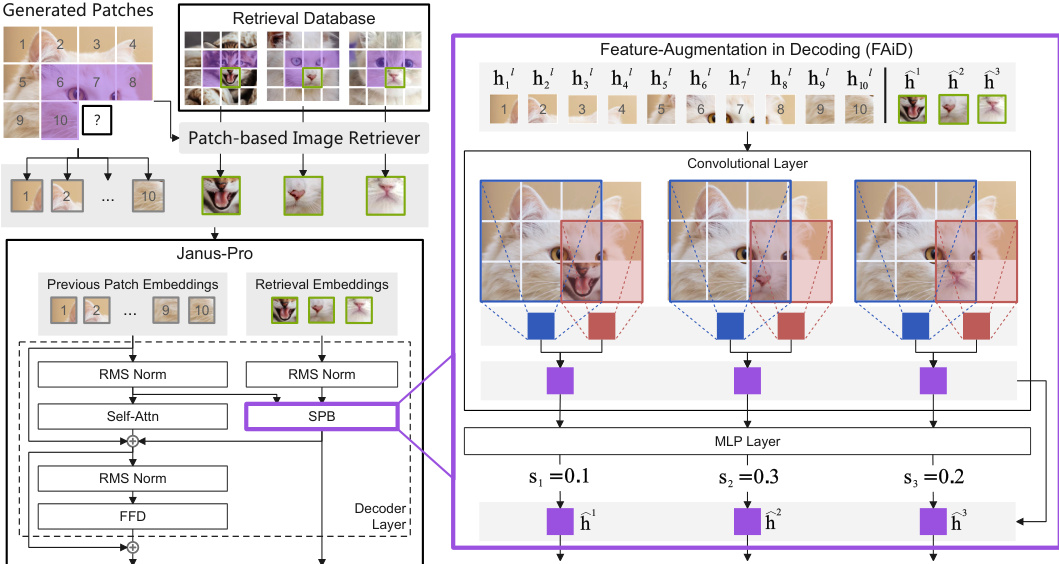
另一方面,FAiD 是一种参数高效的微调方法,通过逐步细化和融合检索图块的特征来增强生成过程。它通过在自回归模型的解码器层中以固定间隔插入 FAiD 模块来运行。对于每个预测的 token,FAiD 首先检索 top-K 个相关图块及其表示。为确保空间连贯性,它应用多尺度特征平滑,即将检索到的图块表示转换到模型的隐藏空间,然后在多个尺度(从 2×2 到 Q×Q)上应用卷积操作以捕捉上下文模式。该过程仅在卷积核覆盖目标位置时执行,以确保计算效率。每个检索图块的最终细化表示是多尺度特征的加权和,权重由可学习参数决定。特征平滑后,计算每个细化图块的兼容性评分,以确定其对最终表示的贡献。随后,通过组合残差、更新的 Transformer 层输出以及检索图块特征的加权和,计算出下一个图像 token 的增强表示。
该框架基于 Janus-Pro 实现,这是一个使用量化自编码器将图像编码为离散 tokens 的自回归图像生成模型。自编码器由编码器、解码器和码本组成,支持从离散图像 tokens 构建检索数据库。在 Midjourney-30K、GenEval 和 DPG-Bench 等基准上的大量实验证明了 AR-RAG 的有效性,相较于最先进模型展现出显著的性能提升。此外,作者表明其方法具有可迁移性,通过调整检索机制以适应不同的生成策略,可将其应用于 Show-o 等其他模型。
实验
该评估结合多个生成基准、定性视觉比较和推理计时测试,以验证自回归图块级检索框架。基准和定性结果表明,在生成过程中动态整合细粒度视觉特征能显著提升指令遵循能力和多物体构图能力,同时防止静态检索方法中常见的无关参考元素过度复制。效率测试证实,该方法在带来显著质量提升的同时,保持了实用的计算开销。总体而言,该框架建立了一种稳健且与架构无关的增强方案,在多样化的合成任务中保留了生成灵活性和整体图像保真度。
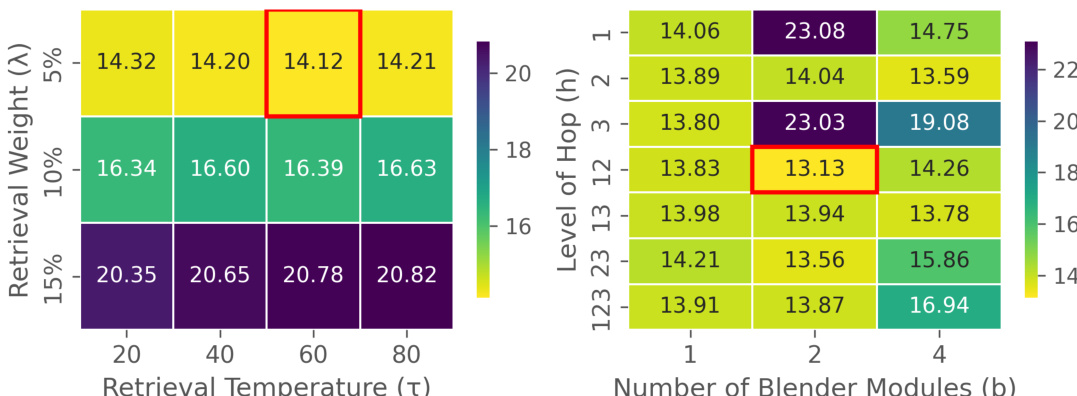
作者分析了超参数对其 AR-RAG 方法性能的影响,重点关注 DAiD 的检索温度和合并权重,以及 FAiD 的跳级数和混合器模块数量。结果表明,最佳配置涉及检索信息的适度整合以及检索上下文的平衡组合,特定设置能在基准测试中取得最佳性能。这些发现支持了仔细调整超参数以实现有效自回归图块级检索和细化的重要性。通过适度整合检索信息和平衡的超参数设置可实现最佳性能。检索温度和合并权重的特定配置使 DAiD 取得最佳结果。结合多级跳数和中等数量的混合器模块使 FAiD 达到最优性能。
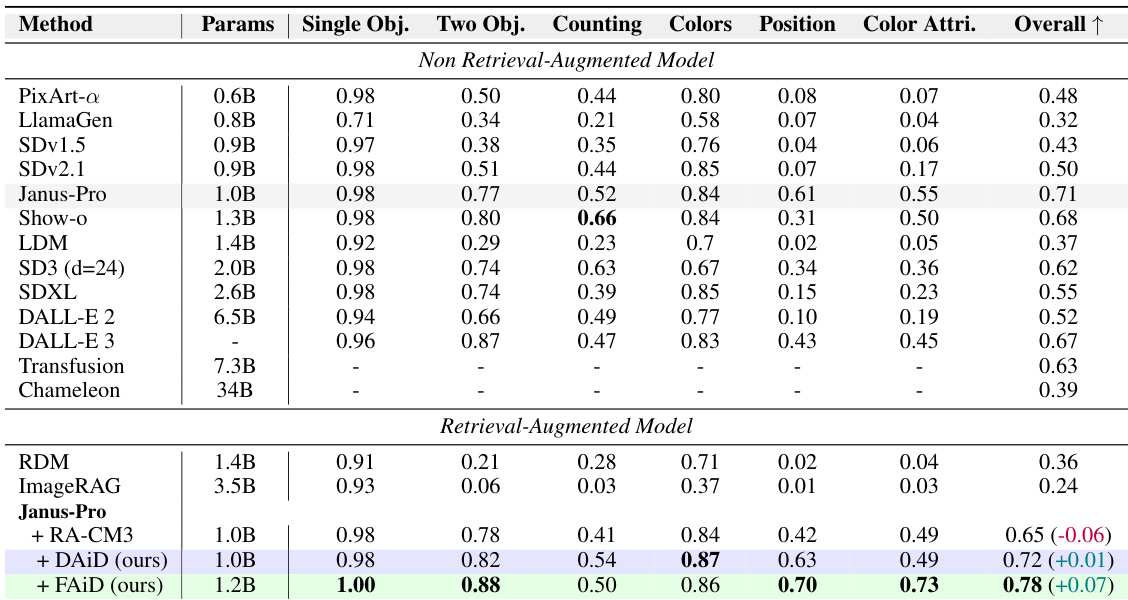
作者在多个基准上评估了文生图方法,将检索增强方法与无检索基线进行对比。其基于 Janus-Pro 提出的方法在整体性能上表现出持续提升,特别是在需要准确多物体生成和空间排列的类别中,同时保持了计算效率。结果凸显了自回归图块级检索相较于图像级检索的优势,后者往往导致过度复制和指令遵循能力差。提出的检索增强方法在多个基准上始终优于无检索基线,在多物体和空间推理任务中取得显著提升。图像级检索方法存在过度复制和指令遵循能力差的问题,而自回归图块级方法实现了视觉特征的选择性和上下文感知整合。所提方法以极小的推理时间开销实现了更高的质量和连贯性,展现出实用的效率与可扩展性。
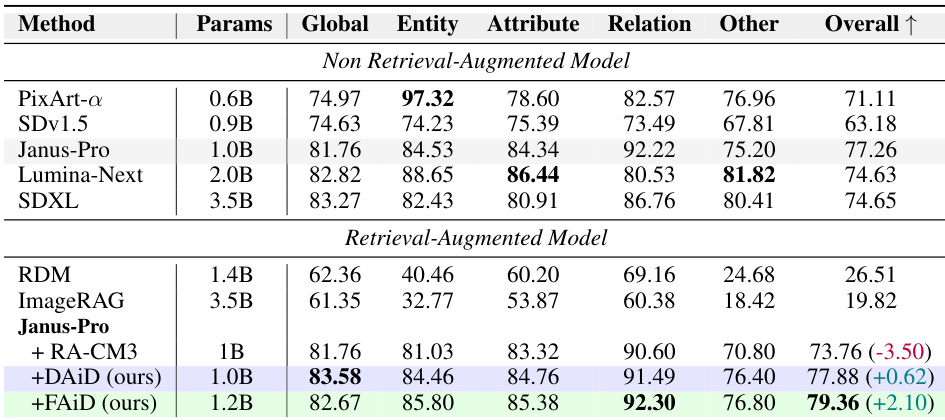
作者在多个基准上将其自回归检索增强生成方法与现有方法进行评估对比,展示了文生图质量的持续改进。其方法在需要准确多物体排列和详细提示词遵循的复杂场景中取得更好结果,同时保持计算效率。性能提升归功于动态的图块级检索,该机制避免了对检索参考中无关视觉结构的过拟合。在需要准确多物体生成和空间排列的基准上,该方法优于现有的检索增强方法。与图像级检索方法相比,自回归图块级检索减少了无关视觉元素的过度复制,并提升了指令遵循能力。所提方法在保持低推理时间开销的同时,实现了图像质量指标的显著改进。
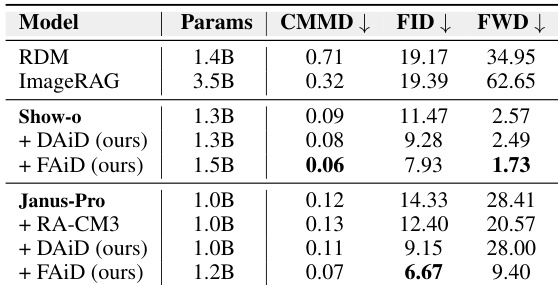
作者在多个基准上评估了文生图模型,对比了无检索增强与检索增强方法。结果表明,其提出的 AR-RAG 方法始终优于现有检索增强模型,特别是在需要准确多物体生成和空间排列的任务中,类别特定指标和整体性能指标均有提升。所提 AR-RAG 方法在多个基准上取得了高于现有检索增强方法的性能,尤其是在多物体和空间推理任务中。AR-RAG 方法在双物体生成和定位等类别中表现出显著改进,优于无检索和检索增强基线。结果证明,自回归图块级检索提升了图像质量和指令遵循能力,与图像级检索方法相比,减少了过度复制并改善了物体一致性。
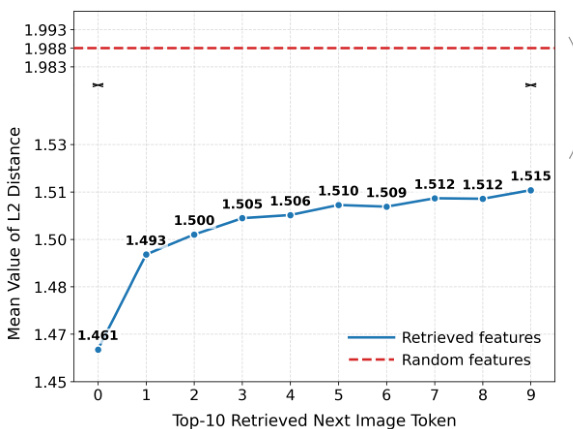
作者通过测量不同检索排名下检索特征与下一个图像 token 之间的平均 L2 距离,分析了检索特征对生成质量的影响。结果表明,在最初几个检索 token 之后,平均 L2 距离迅速稳定,表明早期检索的特征信息更丰富,对生成过程的贡献更大。随机特征的距离始终较高,表明检索到的特征更具相关性且与生成上下文对齐。该趋势显示,检索特征的质量在初始检索排名时提升,随后趋于平稳,突出了在过程早期选择最相关特征的重要性。初始检索排名后平均 L2 距离迅速稳定,表明早期检索的特征影响力更大。与随机特征相比,检索特征表现出更低的平均 L2 距离,说明其与生成上下文的相关性和对齐度更高。特征质量的提升在最初几个检索排名后减弱,突出了后期检索特征收益递减的特点。
作者在多个文生图基准上评估了其自回归检索增强生成框架,验证了其在无检索和图像级检索基线下的有效性。超参数分析表明,适度整合策略和平衡配置对实现最佳性能至关重要,而特征相关性研究证实,早期检索排名能提供最丰富且与上下文对齐的视觉线索。综合来看,这些实验表明,图块级检索通过最小化无关的过度复制并提升指令遵循能力,显著增强了多物体构图和空间推理能力。该方法在保持实用计算效率的同时,持续提供更高的生成质量和连贯性。