Command Palette
Search for a command to run...
面向视频配音的长度感知语音翻译
面向视频配音的长度感知语音翻译
Harveen Singh Chadha Aswin Shanmugam Subramanian Vikas Joshi Shubham Bansal Jian Xue Rupeshkumar Mehta Jinyu Li
一键部署 Linly-Dubbing:一键视频下载+翻译+配音+字幕
摘要
在视频配音中,将翻译后的音频与源音频对齐是一项重大挑战。我们的重点在于实现高效对齐,以适配实时、设备端的视频配音场景。我们开发了一种基于音素的端到端长度敏感型语音翻译(LSST)模型,该模型使用预定义标签生成不同长度(短、正常、长)的译文。此外,我们引入了长度感知束搜索(LABS),这是一种在一次解码过程中生成不同长度译文的高效方法。该方法在保持与无长度感知基线相当BLEU分数的同时,显著提升了源音频与目标音频之间的同步质量,分别使西班牙语和韩语的平均意见得分(MOS)提高了0.34和0.65。
一句话总结
作者提出了一种基于音素的端到端长度敏感语音翻译(LSST)模型,用于实时设备端视频配音。该模型采用预定义的长度标签和长度感知束搜索(LABS)解码器,在单次解码过程中生成短、中、长三种长度的译文,在保持与无长度感知基线相当的 BLEU 分数的同时,为西班牙语和韩语分别实现了 0.34 和 0.65 的平均意见得分(MOS)同步性提升。
核心贡献
- 基于音素的长度敏感语音翻译(LSST)模型利用预定义的长度标签生成短、中、长三种候选译文。这种基于音素的比例方法为跨语言时长建模提供了一致且可扩展的表示方式。
- 长度感知束搜索(LABS)解码策略在单次解码过程中生成不同长度的译文。该方法消除了多次解码迭代的计算开销,显著降低了延迟和系统复杂度,有利于实时设备端部署。
- 该框架在保持与标准基线相当的 BLEU 分数的同时,显著提升了音频同步性。该方法为西班牙语和韩语分别实现了 0.34 和 0.65 的平均意见得分提升,证实了其在时间对齐视频配音中的有效性。
引言
端到端语音转文本翻译已成为自动视频配音的关键技术,该技术显著提升了全球内容的可访问性。成功的配音要求源音频与目标音频之间实现精确的时间对齐,但语音时长在不同语言中天然存在差异,这通常会导致节奏不匹配和表达不自然。以往的长度控制方法通常依赖文本到文本的翻译、缺乏跨语言一致性的基于字符的建模,或引入不可接受延迟的多遍解码策略,这些均难以满足实时设备端部署的需求。为克服这些障碍,作者提出了一种长度敏感语音翻译框架,并结合长度感知束搜索。该方法利用基于音素的比例在单次解码过程中高效生成短、中、长三种翻译候选,从而确保精确且流畅的时间对齐。
方法
作者采用了一种基于音素的端到端长度敏感语音翻译(LSST)模型,该模型专为实时设备端视频配音场景设计,能够生成短、中、长不同长度的译文。该方法的核心在于利用预定义的长度控制 token(<short>、<normal> 和 <long>)来调节翻译过程。在训练阶段,这些 token 被添加至每条目标译文的前端,以替换标准的序列起始(SOS)token。长度标签的分配由目标文本与源文本的长度比值决定,并通过音素数量进行计算以确保跨语言一致性。具体而言,长度标签 ℓ 的分配规则如下:
其中 r 表示目标与源文本的长度比值,α=0.1。相较于基于字符的方法,基于音素的长度计算更具优势,尤其是在处理英语和韩语等不同书写系统的语言时。由于正字法结构的差异,字符数量在时长估算中可靠性较低。
在推理阶段,LSST 模型可通过条件化相应的长度 token 生成多种长度变体。然而,独立生成全部三种变体会带来较高的计算成本。为解决此问题,作者引入了长度感知束搜索(LABS)算法,该算法能够在单次解码过程中高效生成所有长度变体。

如图所示,LABS 算法对标准束搜索进行了改进,使用长度特定 token L={s,n,l}(分别对应 <short>、<normal> 和 <long>)初始化束。在每个时间步 t,算法为每个长度标签 ℓ∈L 生成新的假设,并将长度特定子束 Bt(ℓ) 中的每个假设 b 与目标词表 V 中的每个 token v 进行拼接扩展。每个长度标签的新假设集合表示为:
其中 ⊕ 表示 token 拼接,St+1(ℓ) 为扩展假设的更新得分,计算方式如下:
St+1(ℓ)=St(ℓ)+logP(v∣b,ℓ,x)时间步 t+1 的完整束由所有长度特定子束的并集构成:
Bt+1=ℓ∈L⋃Bt+1(ℓ)剪枝操作采用长度感知方式进行,以在控制束大小的同时保持多样性。剪枝函数 Prune(Bt+1,N,L) 从合并后的束 Bt+1 中选取前 N 个假设,并在条件允许的情况下确保保留每个长度标签的至少一个假设。选择过程优先保留高分假设,同时强制保证长度类别间的多样性。具体而言,每个长度标签的前三个假设会被纳入,其余 N−3 个候选者则根据得分进行筛选。若所有标签下的假设总数不足 N 个,则全部保留。此外,已到达序列结束 token ⟨EOS⟩ 的假设会被优先处理,以确保最终候选集中包含完整的译文。
该算法迭代执行束扩展与剪枝步骤,直至达到最大长度 T 或所有假设均生成 ⟨EOS⟩。最终的 n-best 列表 H^ 从已完成假设集合 Bfinal 中通过选择函数 SelectNBest(Bfinal,N,L) 得出。该函数在尽可能保证各长度标签均有代表的前提下,主要依据得分进行排序。该方法使得在单次解码过程中高效生成多种长度变体成为可能,从而在不牺牲翻译质量的前提下,实现与源音频时长的同步。
实验
评估设置采用在西班牙语和韩语数据上训练的跨语言语音转文本模型,并通过 FLEURS 测试集评估翻译质量与时间对齐效果。第一组实验验证了基于音素长度 token 作为调节输出时长并保持翻译保真度的有效单元。第二组实验验证了 LABS 解码策略,结果表明该策略在提升语速合规性与感知同步性方面取得显著进展,且未损害流畅性也未引入显著延迟。综合来看,这些发现证实了将长度感知解码与基于音素的控制相结合,能够生成节奏更自然、时间更精准的译文,从而紧密匹配源音频的语速。
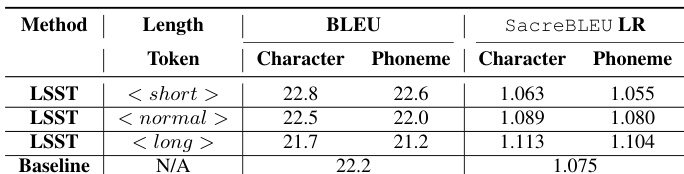
作者评估了使用基于字符和基于音素长度 token 的长度敏感语音翻译模型,并将其性能与基线进行对比。结果表明,两种长度 token 类型均能在控制输出长度的同时保持翻译质量,且基于音素的方法表现与基于字符的方法相当。所提出的 LABS 方法提升了语速合规性与同步质量,尤其在韩语任务中表现突出,同时保持了低延迟与高翻译质量。基于字符和基于音素的长度 token 均能在实现长度控制的同时,达到与基线相当的翻译质量。基于音素的长度 token 表现与基于字符的 token 相当,这支持了在长度敏感翻译中使用音素的做法。LABS 方法在延迟增加极小的情况下,显著提升了语速合规性与同步质量,尤其在韩语任务中效果明显。
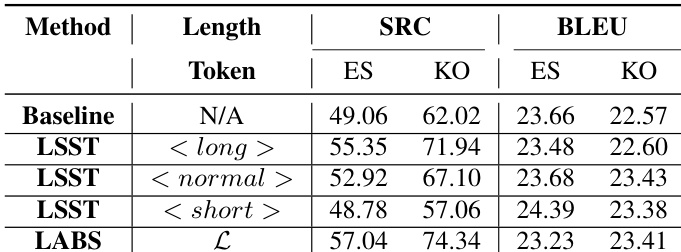
作者评估了采用不同长度控制机制的长度敏感语音翻译模型,对比了使用基于字符和基于音素长度单元时的基线与 LSST 方法。结果表明,LABS 方法在保持翻译质量的同时提升了语速合规性,在不同语言中均取得一致改善,且延迟增加极小。对于西班牙语和韩语,LABS 在语速合规性方面均显著优于基线。LABS 方法维持了翻译质量,西班牙语 BLEU 分数仅有轻微下降,韩语则有所提升。与传统束搜索相比,LABS 实现了更好的同步性,且延迟增加微乎其微。
实验通过对比标准基线与所提出的长度感知对齐方法,评估了长度敏感语音翻译框架。该方法同时利用基于字符和基于音素的 token 进行输出长度控制。评估结果验证了两种 token 类型均能有效保持翻译质量并实现精确的长度管理,且基于音素的单元表现与基于字符的替代方案相当。最终,所提出的方法在保持极低处理延迟与稳健整体翻译性能的同时,显著提升了各测试语言的语速合规性与音文同步性。