Command Palette
Search for a command to run...
利用AlphaFold3和纯化序列进行状态感知蛋白质-配体复合物预测
利用AlphaFold3和纯化序列进行状态感知蛋白质-配体复合物预测
Enming Xing Junjie Zhang Shen Wang Xiaolin Cheng
一键部署 AlphaFold3
摘要
基于深度学习的蛋白质-配体复合物预测随着AlphaFold3、Boltz-1、Chai-1、Protenix和NeuralPlexer等架构的发展取得了显著进展。多序列比对(MSA)一直是关键输入,提供了对结构推断至关重要的共进化信息。然而,最近的基准测试揭示了一个主要局限性:这些模型往往从训练数据中记忆配体构象,并且在面对新的化学型或涉及结合口袋显著构象变化的动态结合事件时表现不佳。为了克服这一缺陷,我们引入了一种状态感知的蛋白质-配体预测策略,该策略利用了由AF-ClaSeq生成的纯化序列子集——这是我们要团队先前开发的一种方法。AF-ClaSeq分离共进化信号,并选择那些优先编码由AlphaFold2预测的不同结构状态的序列。通过应用源自MSA的构象约束,我们在预测配体构象方面观察到了显著改进。在AlphaFold3此前失败的情况下——即产生错误的配体放置及其相关的蛋白质构象——我们通过使用对应于相关功能状态(例如,与负别构调节剂结合的酶的非活性形式)的序列子集,成功纠正了这些预测。
一句话总结
本研究提出了一种状态感知的蛋白质-配体复合物预测策略,该策略将AlphaFold3与AF-ClaSeq纯化的序列子集相结合,以分离不同结构状态的共进化信号,并应用基于多序列比对(MSA)的构象约束,以克服配体构象记忆问题,并修正AlphaFold3在动态结合事件中的预测失败。
核心贡献
- 一种状态感知的蛋白质-配体预测策略将基于AF-ClaSeq的纯化序列子集整合至深度学习结构预测流程中。该方法过滤多序列比对,仅保留编码不同结构构象的序列,并应用进化约束引导折叠算法朝向与配体兼容的状态。
- 准确的构象采样依赖于序列纯度而非比对深度,特定状态的进化信号分布在不同的系统发育分支中。该发现规避了基于注意力机制的Transformer在处理异构进化数据时面临的信号平均化局限。
- 将纯化序列子集整合至AlphaFold3框架中,可生成比默认预测更准确的配体结合位置和结合口袋几何结构。该方法修正了先前在需要显著构象重排或新型化学型结合的靶点上出现的建模失败问题。
引言
蛋白质-配体复合物的准确预测是计算药物发现和分子建模的基石,近期如AlphaFold3等深度学习架构通过利用多序列比对中的共进化信号实现了突破性精度。尽管取得这些进展,当前模型在处理新型化学型时仍常遇到困难,且无法捕捉结合口袋的柔性,通常默认生成单一静态构象或依赖训练数据中记忆的结构模式。为突破这些障碍,研究人员利用名为AF-ClaSeq的序列纯化框架,分离出专门编码特定蛋白质构象的进化子集。通过将这类状态特异性序列子集整合至AlphaFold3中,引入了构象约束以引导模型朝向具有功能意义的结构状态,显著提升了配体构象预测精度,并实现了对动态结合事件的可靠预测。
方法
研究人员采用序列纯化策略,以提升涉及变构抑制剂的蛋白质-配体复合物预测效果,尤其针对EGFR和IL-1β等蛋白,其目标构象与AlphaFold3(AF3)预测的默认状态存在显著差异。该方法的核心在于对AF3使用的多序列比对(MSA)施加偏向性,使其倾向于特定蛋白质构象,从而引导模型朝向预期的结构状态。该流程始于从大量同源序列池中生成的深度MSA。针对EGFR,初始包含49,743条序列的MSA通过覆盖度阈值过滤至43,365条。为评估该MSA中编码的构象偏向性,研究人员进行了一系列M重采样实验,通过随机打乱的序列组预测结构。初步分析显示存在强烈的活性状态偏向,这归因于模型倾向于预测代表性充分的构象。
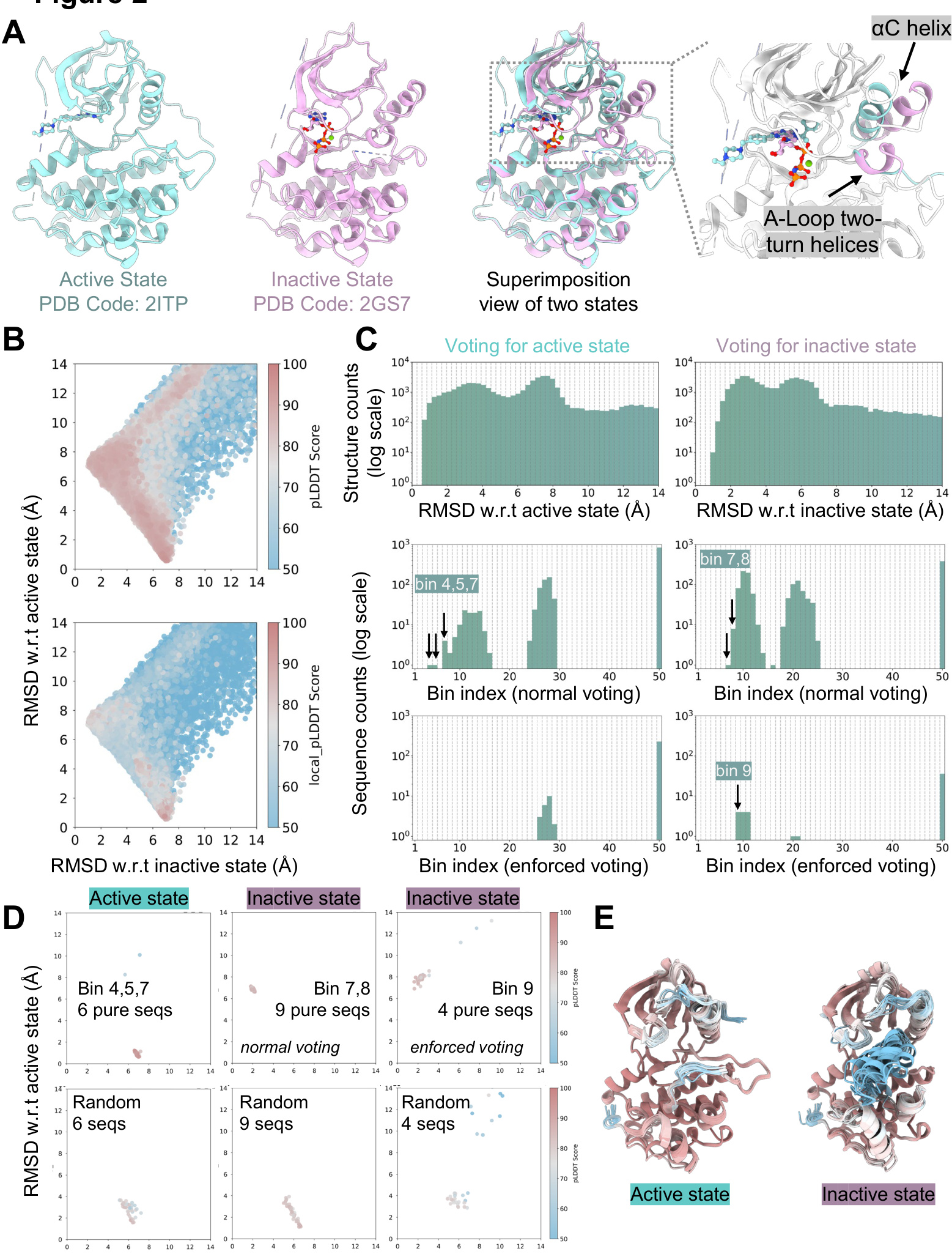
为纠正该偏向性,研究采用迭代富集流程。该方法以关键结构元件(αC螺旋与激活环A-Loop)相对于目标非活性状态参考结构(PDB 2GS7)的均方根偏差(RMSD)作为评估指标。序列被分为每组六条,预测完成后,筛选出生成结构与非活性状态RMSD最低的序列进入下一轮迭代。该过程重复四次,逐步富集编码非活性构象的序列池。最终迭代的富集序列集随后用于M重采样,生成大量预测结果以绘制构象景观。结果以散点图形式呈现,显示预测结构沿构象轴的分布,局部pLDDT分数反映了预测二级结构的置信度。
为识别偏向性最强的序列,研究采用投票机制。预测结果根据其与活性状态和非活性状态的RMSD进行分箱。一种“常规投票”方案选择特定分箱中出现频率最高的序列。一种更严格的“强制投票”方案不仅要求频率最高,还要求频率超过0.15的阈值,从而分离出具有极强构象偏好性的序列。该流程识别出一组被标记为“纯序列”的序列子集,这些序列高度偏向非活性状态。这些纯化序列用于生成最终的MSA,以供AF3预测蛋白质-配体复合物,输入中包含配体的SMILES字符串。
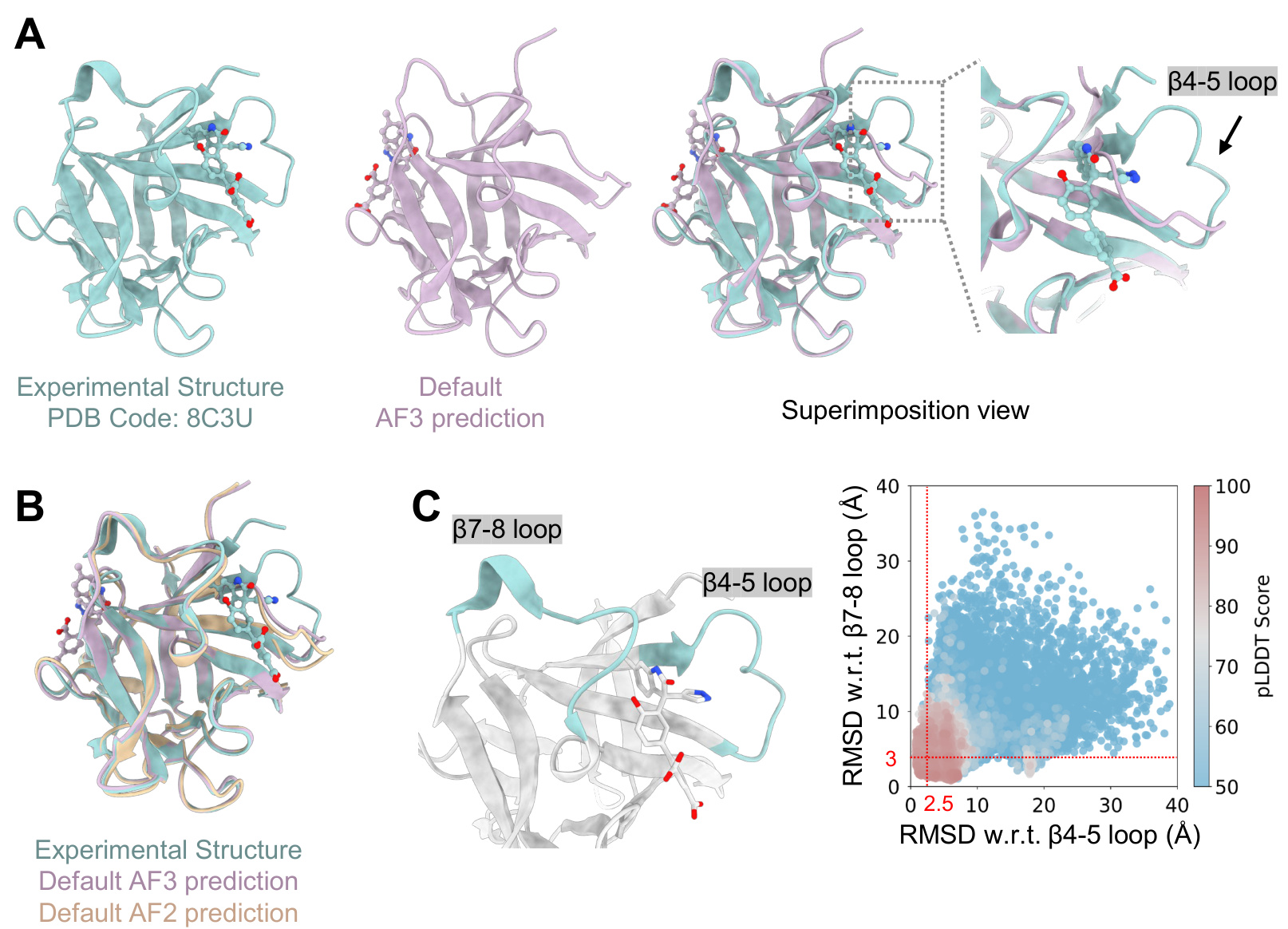
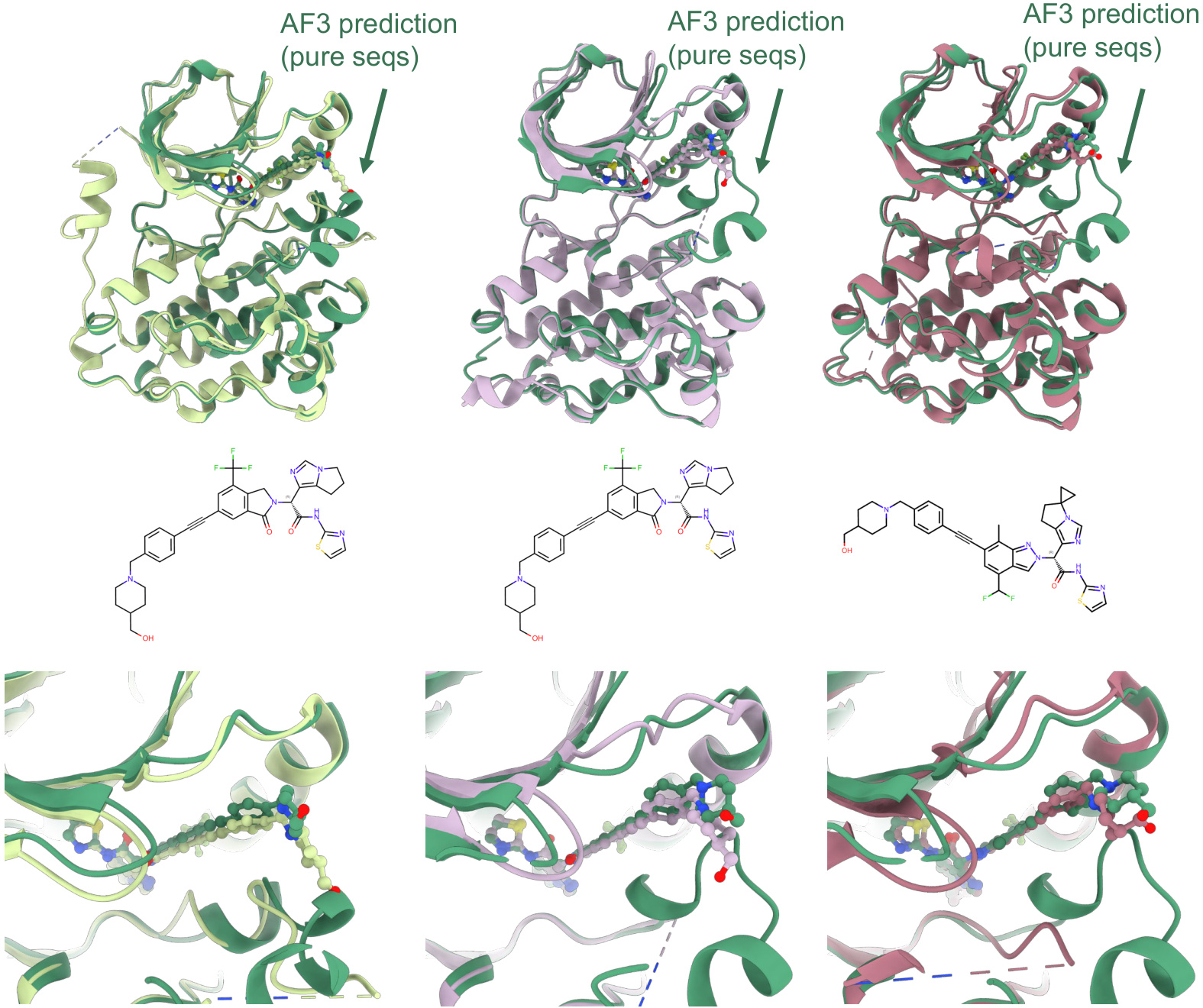
该方法在EGFR-4变构抑制剂复合物上进行了验证。默认AF3预测结果高度发散,未能重现正确的配体构象。然而,使用纯化非活性状态序列进行的预测显示出显著改善的精度与一致性。配体RMSD降至2.5 Å附近或以下,配体原子pLDDT分数大幅提升,表明结合模式预测可靠。类似方法也应用于IL-1β/配体系统,其关键构象变化涉及β4-5环的位移。基于与位移环状态RMSD的迭代富集流程被用于生成富集序列集。使用目标构象区域中频率最高的前20条序列进行的预测与实验结构实现完美对齐,证明了源自MSA的构象约束的有效性。
实验
本研究通过比较默认AlphaFold3预测与基于通用构象参考的迭代序列纯化引导预测,评估了两个变构抑制剂系统:EGFR突变体与IL-1β隐蔽口袋拮抗剂。默认模型始终未能捕捉必要的变构或隐蔽结合构象,且倾向于回退至记忆的训练模式,而纯化方法成功将多序列比对偏向于具有功能意义的非活性或变构状态。因此,优化后的预测在蛋白质主链与配体构象上均与实验晶体结构高度吻合,证明由构象约束引导的序列富集为准确建模新型变构药物-靶点相互作用提供了广泛适用的框架。