Command Palette
Search for a command to run...
一键部署音乐生成基础模型 ACE-Step:
摘要
一句话总结
ACE-Step 是一款开源的音乐生成基础模型,它将基于扩散的生成方法与 Sana 的 Deep Compression AutoEncoder 及轻量级线性 Transformer 相结合,利用 MERT 和 m-hubert 进行语义对齐。该模型在 A100 GPU 上仅需 20 秒即可生成长达 4 分钟的音乐,相比基于 LLM 的基线方法实现了 15 倍的速度提升,同时在旋律、和声与节奏指标上展现出更优的音乐连贯性与歌词对齐能力。
核心贡献
- 本文提出 ACE-Step,一款面向音乐生成的开源基础模型,旨在解决推理速度、结构连贯性与可控性之间固有的权衡问题。
- 该架构将基于扩散的生成器与 Deep Compression AutoEncoder 及轻量级线性 Transformer 相融合,并利用语义表示对齐技术加速训练收敛,同时保留细粒度的声学细节。
- 评估结果表明,该模型在 A100 GPU 上仅需 20 秒即可合成长达 4 分钟的音频,推理速度比基于 LLM 的基线方法快 15 倍,同时在旋律、和声、节奏及歌词对齐指标上达到领先水平。
引言
文本到音乐的生成在人工智能领域面临独特挑战,这源于旋律、和声、节奏与精确歌词对齐之间的复杂交互。尽管商业平台发展迅速,但开源模型在平衡生成速度、长程结构连贯性与细粒度可控性方面仍面临困难。两阶段自回归方法通常存在推理缓慢与误差传播的问题,而潜在扩散方法则往往缺乏音乐一致性且条件控制不够灵活。为突破这些局限,研究团队采用 Deep Compression AutoEncoder,并将其与由轻量级线性 Transformer 驱动的流匹配过程相结合。此外,引入基于预训练 MERT 和 mHuBERT 编码器的表示对齐技术,以加速训练收敛并严格保证语义与歌词的忠实度。该架构设计使得在数秒内合成多分钟时长的音乐成为可能,同时支持歌词编辑与声音克隆等高级创意控制功能,为下一代音乐 AI 应用奠定了快速且可扩展的基础。
数据集

-
数据集构成与来源: 研究团队构建了一个包含约 180 万首独立音乐作品的大型音频语料库,总时长约 10 万小时。该合集涵盖 19 种语言,其中英语占主导地位。
-
关键细节与过滤规则: 为确保严格的音频质量,整个语料库均通过 Audiobox 美学工具包进行处理。该自动化质量控制流程系统性地识别并剔除低保真录音与现场演出,有效清除了容易产生不良声学伪影的曲目。
-
元数据构建与标注: 数据集通过多模态条件信号进行增强,以指导模型生成。捕捉音乐内容与情绪的描述性字幕由 Qwen-omini 生成。人声曲目通过 Whisper 3.0 进行转录,随后利用映射国际音标(IPA)表示的局部敏感哈希方法将其与标准歌词数据库对齐。结构分割通过专用的音乐理解模型识别歌曲段落(如主歌与副歌)。节奏与调性特征(包括每分钟节拍数与音乐调性)由 Beatthis 和 Essentia 提取,随后由 Qwen-omini 标准化为一致的自然语言短语。
-
数据使用与处理流程: 该精选合集作为 ACE-Step 模型的主要训练语料库。研究团队将清洗后的音频与生成的元数据相融合,在训练阶段提供丰富的条件信号。尽管提供的部分未详细说明具体的训练集划分与混合比例,但完整的预处理流程确保了模型能够接收格式统一、无伪影且语义结构清晰的音频-文本对,从而实现稳健的优化。
方法
ACE-Step 模型被设计为一款快速、通用且灵活的音乐生成基础模型,借鉴了成功的文本到图像框架中的基于扩散的生成范式。整体架构融合了高效的架构选择与先进的语义对齐技术,以实现高质量且可控的音频合成。如图所示,该模型在压缩的梅尔频谱图潜在表示上运行,核心生成过程由三个专用编码器提供的条件信息引导:文本提示编码器、歌词编码器与说话人编码器。这些嵌入向量经过拼接后,通过交叉注意力机制整合至扩散模型中,从而实现对生成输出的细粒度控制。
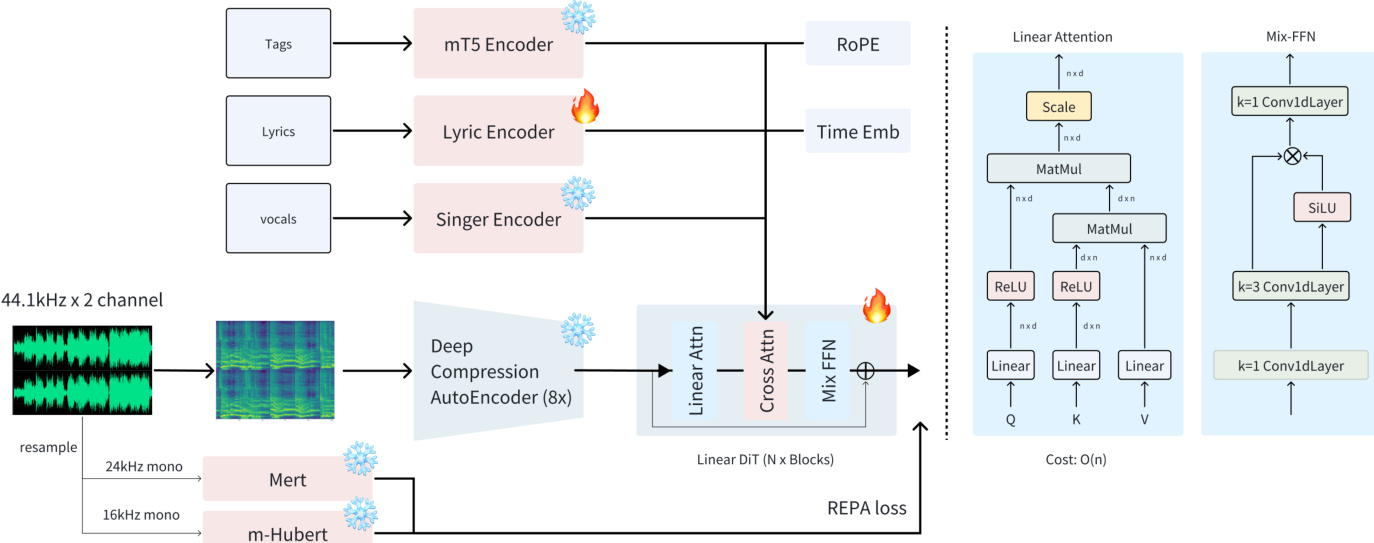
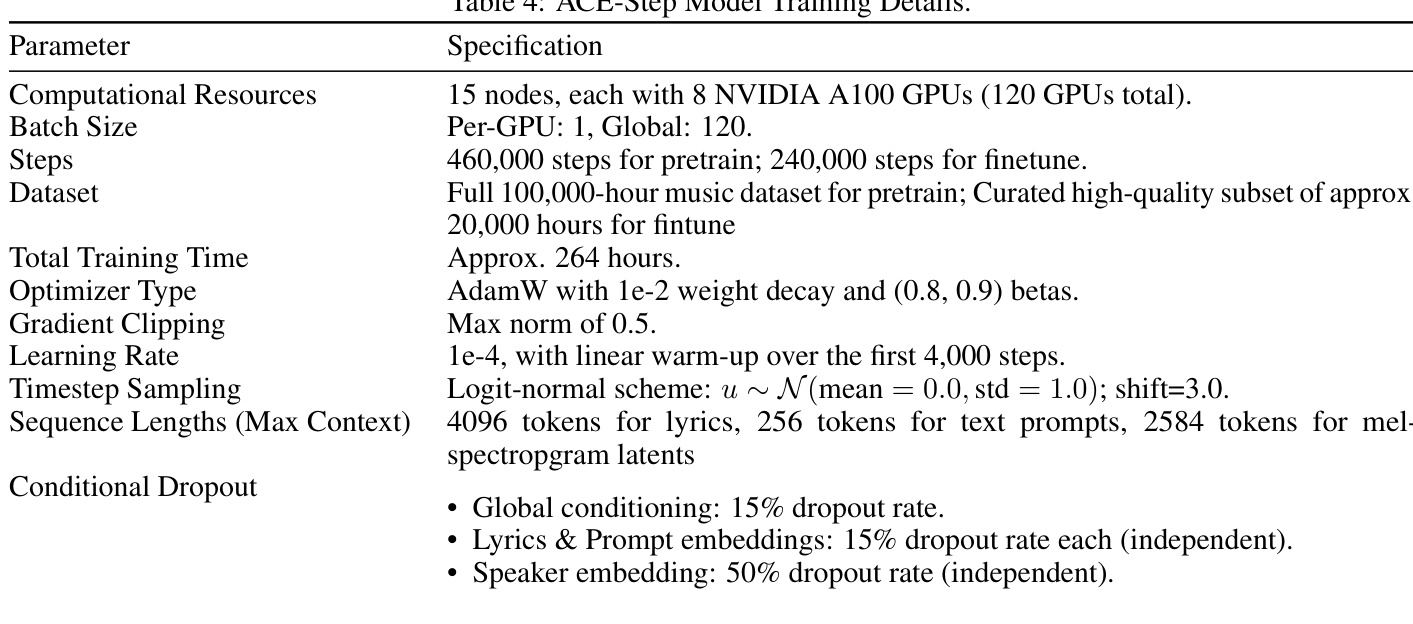
音频表示流程始于 Deep Compression AutoEncoder (DCAE),该模块将输入音频压缩至潜在空间。DCAE 配置为 8 倍压缩设置(f8c8, channel=8),实现约 10.77Hz 的时间分辨率,相较于更高压缩倍率,在压缩比与保真度之间取得了更优的平衡。生成的梅尔频谱图随后通过 Fish Audio 的预训练通用音乐声码器还原为波形。核心去噪网络为 Linear Diffusion Transformer (DiT),该结构源自 Sana 并进行两项关键改进:采用简化的自适应层归一化(AdaLN-single)以降低模型体积与内存占用;将 2D 卷积前馈层替换为 1D 卷积,以更好地契合音频数据的序列特性。
条件编码器在引导生成过程中发挥关键作用。文本编码器采用冻结的 Google mT5-base 模型,利用其强大的多语言能力从文本提示中生成 768 维嵌入向量。歌词编码器源自 SongGen,在训练期间可训练,并使用 XTTS VoiceBPE token 分词器处理歌词,非罗马化脚本通过图音转换工具转为音位表示。说话人编码器处理 10 秒无伴奏人声片段,生成 512 维嵌入向量,器乐曲目则使用零向量。训练过程中,对说话人嵌入向量应用 50% 的随机丢弃率,以防止对音色信息的过度依赖,从而增强风格控制能力。
训练过程通过优化复合目标函数实现,该函数在生成保真度与语义连贯性之间取得平衡。主要损失函数为连续时间流匹配(Flow Matching, FM)目标,通过预测从噪声到目标数据分布的线性路径所关联的恒定速度场的负值,学习潜在空间中的数据分布。该目标通过重建预测值与真实潜在表示之间的均方误差进行实现。此外,受表示对齐(REPA)框架启发,引入了辅助语义对齐损失,用于约束 Linear DiT 主干网络的中间表示与预训练音频自监督学习(SSL)模型(如 MERT 和 mHuBERT)的表示相一致。这确保了稳健的歌词遵循性与音乐连贯性,尤其在演唱歌词的对齐方面表现突出。
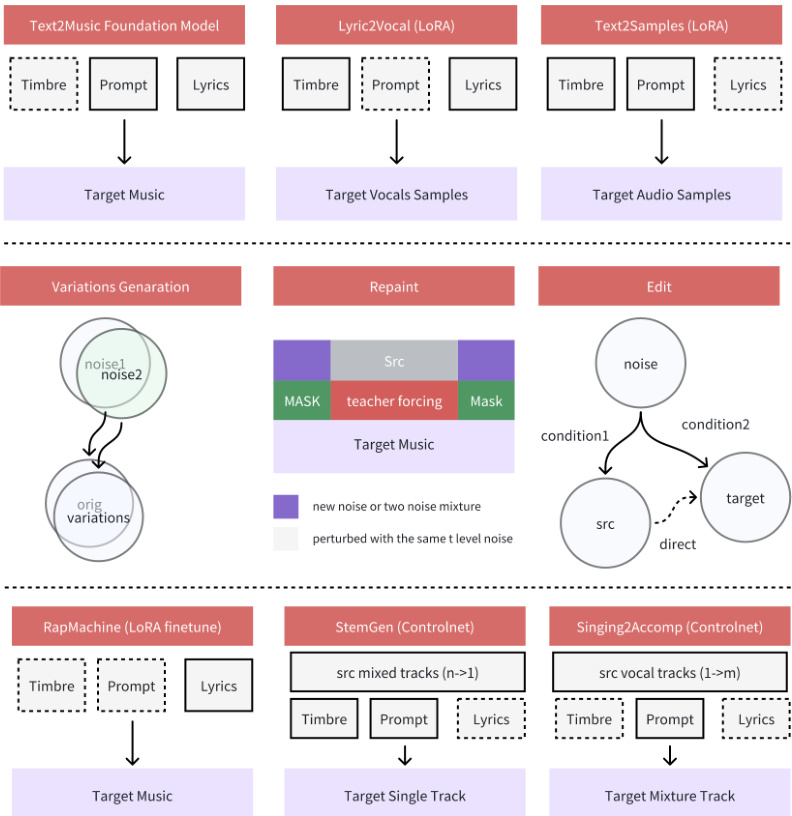
实验
评估工作结合了盲听人类主观评测与全面的自动化基准测试,以验证多种音乐生成模型在波形重建保真度、风格与歌词对齐、感知音乐性及生成效率方面的表现。尽管由于固有的感知差异与当前基准测试的局限性,自动指标与人类主观偏好之间出现了显著分歧,但 ACE-Step 在开源方案中始终展现出更优的流派保真度、音乐连贯性与生成速度。纯文本评估协议进一步证实了其强大的多语言能力和实用效率,将其定位为领先的开源解决方案,同时也凸显了音乐 AI 研究中对感知对齐评估框架的需求。
研究团队使用 FAD 与 Audiobox-aesthetics 分数对比了 Music DCAE 与 DiffRhythm VAE 的波形重建性能。Music DCAE 获得更低的 FAD 分数,表明重建质量更优,而 DiffRhythm VAE 在部分 Audiobox-aesthetics 维度上得分更高,暗示其在特定方面具备更好的音频质量。Music DCAE 的 FAD 分数低于 DiffRhythm VAE,进一步印证了其卓越的波形重建能力。在部分 Audiobox-aesthetics 维度上,DiffRhythm VAE 的表现优于 Music DCAE,表明其在特定音频质量指标上具有优势。Music DCAE 在不同音频条件下均展现出更佳的重建性能,而 DiffRhythm VAE 则在部分质量指标上取得更高分数。

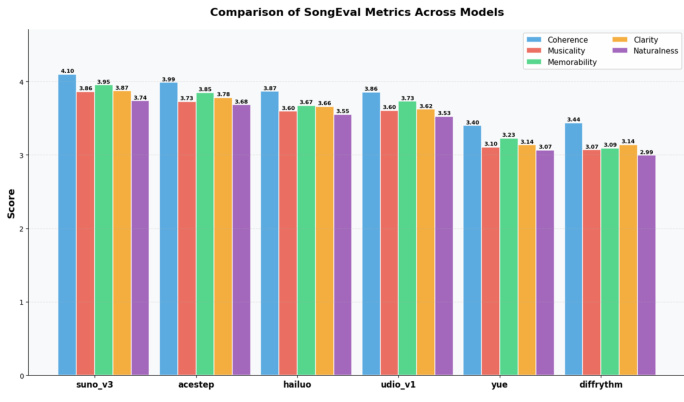
研究团队结合人类主观评测与自动指标对 ACE-Step 的音乐生成性能进行评估,并将其与多种基线模型进行对比。结果表明,ACE-Step 在 SongEval 的多个维度上均取得优异分数,尤其在连贯性与记忆性方面表现突出,且在音乐性与整体质量上与其他模型具备竞争力。该评估凸显了人类主观判断与客观指标之间的差异,SongEval 展现出与人类感知更高的契合度。根据 SongEval 指标,ACE-Step 在连贯性与记忆性上得分较高,超越其他模型。在音乐性与整体质量方面,ACE-Step 表现强劲,在自动评测中位列前茅。研究揭示了人类评测与客观指标之间的分歧,SongEval 相较于其他自动化评估工具,与人类感知的对齐程度更强。
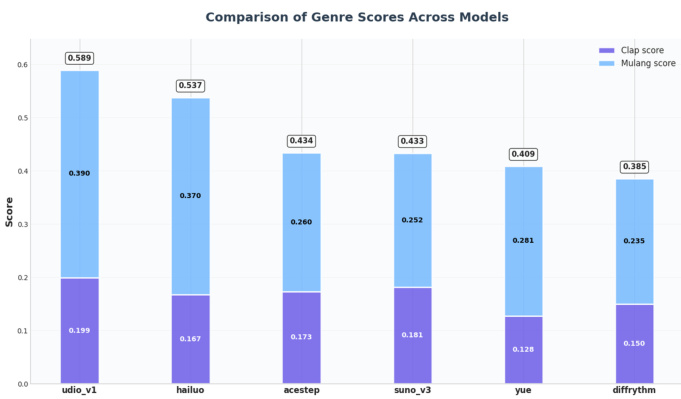
研究团队在流派与歌词对齐、美学质量及音乐性等多项评估指标上,将 ACE-Step 与多种基线模型进行对比。结果表明,ACE-Step 在音乐性与流派保真度上表现强劲,尤其在风格对齐与生成速度方面优势显著,而其他模型则在歌词对齐或美学评分等特定领域具备长处。ACE-Step 在流派对齐上表现优异,在 CLAP 与 Mulan 评分中均超越多项基线。ACE-Step 实现高生成速度,在实时因子方面大幅领先其他模型。尽管 ACE-Step 在音乐性上取得竞争性结果,但受架构差异影响,DiffRhythm 等其他模型在歌词对齐方面得分更高。
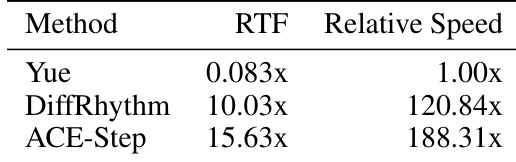
研究团队在 RTX 4090 GPU 上使用实时因子(RTF)对比了 ACE-Step、DiffRhythm 与 Yue 的生成速度,结果显示 ACE-Step 速度最快,显著优于另外两款模型。结果表明,ACE-Step 的生成速度大幅领先于 Yue,同时也快于 DiffRhythm,相对速度提升幅度分别达到 188 倍与 120 倍。这些发现表明,尽管模型体积更大且具备多语言能力,ACE-Step 仍保持了极高的运行效率。在对比模型中,ACE-Step 实现了最高的生成速度。ACE-Step 的速度显著快于最慢的 Yue 模型。尽管模型体积较大,ACE-Step 的生成速度仍快于 DiffRhythm。
研究团队开展实验以评估 ACE-Step 模型,重点通过人类主观评测与自动测试检验其音乐生成性能。训练过程消耗大量计算资源并采用特定配置,结果显示该模型在音乐性与生成速度方面与其他模型具备竞争力。评估工作凸显了人类主观判断与客观指标之间的差距,强调了开发更具感知对齐性评估方法的必要性。在人类评测中,ACE-Step 在音乐性与情感表达方面表现强劲,超越多项基线模型。与其他开源方案相比,该模型展现出卓越的生成速度,支持近乎实时的音频制作。自动指标揭示了客观分数与人类感知之间的差异,SongEval 相较于其他指标,与人类判断的对齐程度更佳。
实验通过对比自动化评测与人类主观评估,检验了多种模型在波形重建与音乐生成方面的性能。重建分析证实,Music DCAE 在不同音频条件下能够提供更一致的波形保真度,而 DiffRhythm VAE 则在特定美学维度上展现优势。生成基准测试验证了 ACE-Step 在连贯性、流派对齐与计算效率方面的卓越表现,证明其在大幅超越其他架构的同时仍能保持高质量。综合来看,这些评估揭示了自动化评分与人类感知之间持续存在的差距,凸显了为音乐合成开发更具感知对齐性评估方法的重要性。