Command Palette
Search for a command to run...
MAKIEVAL:一种基于多语言自动WiKIdata的LLMs文化意识评估框架
MAKIEVAL:一种基于多语言自动WiKIdata的LLMs文化意识评估框架
Raoyuan Zhao Beiduo Chen Barbara Plank Michael A. Hedderich
摘要
大型语言模型(LLMs)在全球多种语言中被广泛应用,但其以英语为中心的预训练方式引发了人们对跨语言文化意识差异的担忧,往往导致输出结果存在偏见。然而,由于现有的基准测试有限且翻译质量参差不齐,全面的多语言评估仍面临挑战。为了更准确地衡量这些差异,我们引入了 MAKIEVAL,这是一种自动化的多语言框架,用于评估 LLMs 在不同语言、地区和主题上的文化意识。MAKIEVAL 评估开放式文本生成任务,捕捉模型如何用自然语言表达根植于文化的知识。该框架利用 Wikidata 的多语言结构作为跨语言锚点,自动识别模型输出中的文化实体,并将其链接到结构化知识库中,从而实现可扩展的、语言无关的评估,无需人工标注或翻译。我们随后引入了四个指标,分别衡量文化意识的互补维度:粒度(granularity)、多样性(diversity)、文化特异性(cultural specificity)以及跨语言的一致性(consensus across languages)。我们评估了来自全球不同地区的 7 种 LLMs,包括开源和专有系统,测试范围涵盖 13 种语言、19 个国家和地区,以及 6 个具有显著文化特征的主题(例如食物、服饰)。
一句话总结
MAKIEVAL 是一个利用 Wikidata 结构化知识的多语言自动评估框架,通过识别开放式文本中具有文化基础的实体来评估大语言模型的文化意识。该框架引入了四个指标,分别衡量颗粒度、多样性、文化特异性和跨语言一致性,并在不依赖人工标注或翻译的情况下,对七个模型在十三种语言、十九个国家与地区以及六个文化主题上进行了评估。
核心贡献
- 提出了 MAKIEVAL,一个多语言自动评估框架,利用 Wikidata 作为跨语言锚点来识别大语言模型开放式输出中的文化实体,从而在无需人工标注或翻译的情况下实现可扩展的评估。
- 定义了四个指标——颗粒度、多样性、文化特异性和跨语言一致性——以捕捉生成文本中文化意识的不同互补维度。
- 在 7 个大语言模型、13 种语言、19 个国家/地区以及 6 个文化主题上的实验表明,提示语言对文化表达有显著影响。同时,公开了模型输出及提取的文化实体数据集,以支持进一步的分析。
引言
作者阐述了对大语言模型的文化意识进行评估时所面临的挑战。随着这些系统在全球范围内部署,却常常表现出根植于以英语为中心的训练所带来的偏见,使得文化意识成为一个关键问题。以往的评估方法存在局限,例如依赖多项选择题等简化测试格式、局限于单语或依赖翻译的设置,以及采用静态基准,无法捕捉开放式文本生成中文化表达的多变特性。作者提出了 MAKIEVAL,一个自动化的多语言评估框架,利用 Wikidata 的结构化知识库作为语言无关的锚点。该方法通过四个新颖的指标衡量颗粒度、多样性、文化特异性和跨语言一致性,能够在不需要人工标注或翻译的情况下,直接在生成的文本中评估文化意识。
数据集
以下是根据论文相关段落整理的简要数据集描述。
作者构建了一个以开放式文本生成为中心的多语言评估框架。核心数据集并非静态的文本集合,而是一组结构化的提示词,以及一个用于从模型回复中提取并丰富文化实体的后续流程。
数据集构成与来源
- 提示词: 主要输入数据包含跨越 13 种语言和 6 个文化主题的结构化文本提示词。
- 实体元数据: 提取的实体会与 Wikidata 进行匹配,以检索结构化元数据,包括唯一的 QID、描述、来源国以及作者/表演者的国籍。
各子集关键细节
- 语言(共13种): 阿拉伯语、英语、德语、印地语、意大利语、日语、韩语、波斯语、简体中文、西班牙语、泰语、繁体中文和土耳其语。这些语言涵盖多种语系、书写系统和地理区域。
- 主题(共6个): 食物、饮品、服饰、书籍、音乐和交通,均选自具有文化意义的日常生活方面。
- 提示条件(共3种类型):
- 显式情境化: 直接陈述文化背景(例如,“关于一个来自西班牙的人”)。
- 隐式情境化: 使用一个具有文化联想的人名作为提示(例如,“关于胡安”)。
- 中性: 不提及任何国籍、种族或地点,以评估模型的默认文化偏好。
数据使用方式
- 生成: 使用提示词从大语言模型获取开放式文本。对于出现语言错位的模型(例如,Mistral 用英语回复,Qwen 用中文回复),会附加一条特定于语言的指令以强制保持一致性。
- 实体抽取: 作者使用 GPT-4o-mini 从生成的文本中提取与主题相关的文化实体,并根据语义颗粒度对其分类(例如,区分特定菜名和食材类)。
- 实体匹配与消歧: 提取的实体会使用提示词语言下的标签和别名与 Wikidata 条目进行匹配,并在匹配失败时回退到英语。使用递归消歧程序遍历本体关系(实例,子类),通过检查是否存在任何通往文化相关类别的语义路径来解决模糊标签问题。
处理与元数据构建
- 提示词验证: 所有提示词模板均由 15 位母语者审核,每种语言至少一位标注员,以确保语言准确性和文化适宜性。
- 元数据表: 所有匹配的实体被汇编成一个支持定量和定性分析的结构化表格。每个条目包含实体的 QID、多语言表层标签、颗粒度标签以及国家/地区层级的信息。未能成功消歧的实体将从评估中移除。
方法
作者提出了 MAKIEVAL,一个旨在评估语言模型文化意识的多语言自动评估框架。如下图所示,该流程通过四个序贯步骤运作:文本生成、文化实体抽取、基于 Wikidata 的实体匹配以及基于指标的分析。
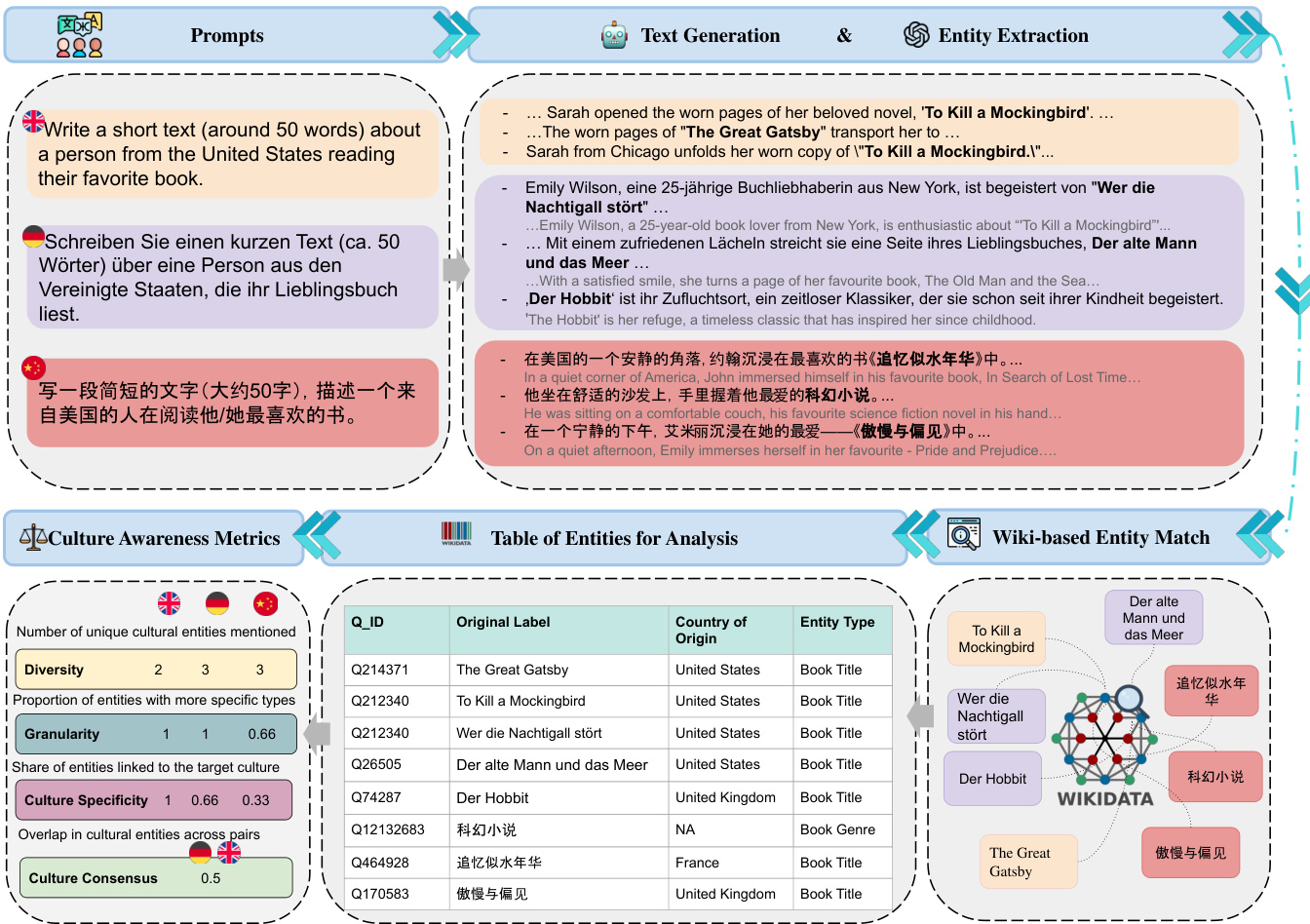
该过程始于文本生成,其中模型会用不同语言对相同的查询进行提示。生成之后,系统执行文化实体抽取。作者利用动态提示词,根据特定主题切换分支,提取特定主题的实体以及诸如人名和地名之类的命名实体。每个提取出的实体也会被分配一个颗粒度标签。由于 Wikidata 的层级结构对此目的并不一致,作者使用 ChatGPT-4-o-mini 来推断颗粒度,将实体归类为特定指代(得分为 1)或一般类别(得分为 0)。最终的颗粒度分数是这些二元值的平均值。
接下来,提取出的实体经过基于 Wikidata 的实体匹配。每个实体都被链接到一个 Wikidata QID,以检索诸如来源国和实体类型之类的元数据,形成一个用于分析的综合性实体表格。设 E 表示针对特定被评估大语言模型和提示词的所有回复中,预测实体的并集。
最后,该框架应用四个指标来评估文化意识的不同方面:颗粒度、多样性、文化特异性和文化一致性。文化一致性量化了模型针对相同主题和文化背景在不同语言下的输出之间的一致程度。设 QA 和 QB 分别表示从语言 A 和 B 对同一提示词的回复中提取的 Wikidata QID 集合。作者使用 Jaccard 相似度计算它们的重叠度:
Consensus(A,B)=∣QA∪QB∣∣QA∩QB∣.更高的一致性表明跨语言的文化基础更稳定,这意味着模型在表层语言变化的情况下仍能保持连贯的文化知识。
实验
该评估框架使用四个指标(颗粒度、多样性、文化特异性和文化一致性)对七个多语言大语言模型在 13 种语言和 6 个文化主题上进行了评估。实验表明,对于给定的模型-语言对,无论文化背景如何,颗粒度都保持稳定,而多样性则因模型而异,并且当使用某个国家的母语进行提示时,多样性通常更高,但这并非必然。当提供显式文化背景时,文化特异性会增加,其中英语提示显示出最高的提升。文化一致性则突显了欧洲语言之间共享了更多对齐的实体表示,表明语言和区域文化联系共同塑造了模型输出。这些发现强调,这些指标是互补的,其可取性取决于下游任务,而不是规定普遍的最优值。
作者通过测量生成的独特文化实体数量,评估了七个多语言大语言模型的文化多样性。结果表明,不同模型之间的多样性得分存在显著差异,其中 Llama3-8B 和 Mistral 展现出比 DeepSeek 和 Qwen 等其他模型更高的多样性水平,后者的输出变化更为受限。Llama3-8B 和 Mistral 达到了最高的平均多样性,这表明它们生成了更丰富的独特文化实体。DeepSeek 和 Qwen 展现出最低的平均多样性和方差,表明其文化输出更具重复性。将 Llama3 的模型大小从 8B 参数增加到 70B 参数版本,会导致平均多样性下降。
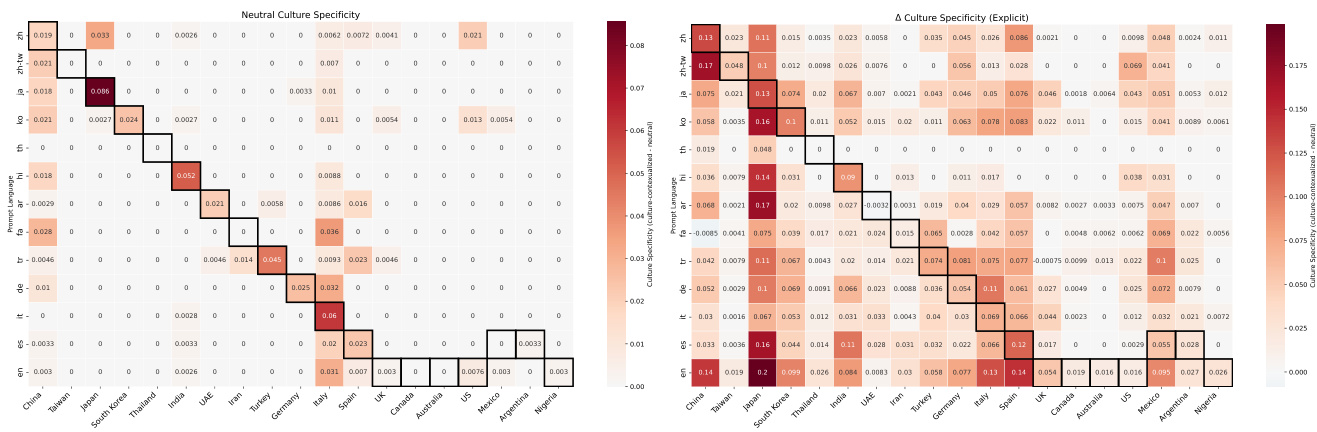
作者通过比较模型对中性提示词和包含显式文化背景的提示词的输出,评估了文化特异性。结果表明,当提示语言与所引用国家的母语一致时,中性提示自然表现出更高的特异性。此外,在大多数组合中添加显式文化背景通常会提高特异性,其中英语提示的提升最为显著。当中性提示的提示语言与目标国家的母语一致时,会产生更高的文化特异性。在大多数语言和国家配对中,在提示中明确提供文化背景会提高文化特异性。当显式添加文化背景时,英语提示始终获得最大的特异性提升。
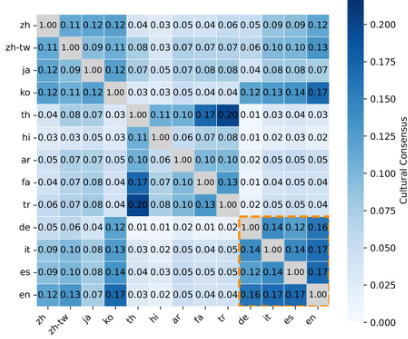
作者评估了各种多语言大语言模型的文化一致性,以衡量文化实体在不同提示语言中表示的相似程度。结果表明,与较小的模型相比,较大的模型倾向于获得更高且更一致的一致性分数。然而,模型大小并非唯一的决定因素,因为在规模相当的较小模型之间也观察到了显著的一致性差异。评估中最大的模型取得了最高且最一致的文化一致性分数。较小的模型之间一致性存在显著差异,这表明规模并非唯一的影响因素。Mistral 在所有测试模型中记录了最低的文化一致性分数。
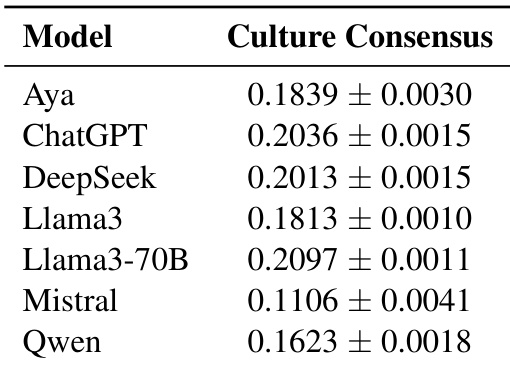
作者通过评估文化一致性来衡量模型在不同提示语言下表示文化实体的相似程度。结果表明,模型大小影响一致性水平,较大的模型展现出更一致的分数。此外,分析揭示了强大的区域内一致性,特别是在欧洲语言之间以及日语和韩语之间,这表明训练数据中共享的文化视角塑造了跨语言表示。模型大小似乎会影响文化一致性,较大的模型在跨语言上实现了相近的一致性分数。欧洲语言在彼此之间表现出更高的文化一致性,这表明训练数据中存在共享的区域视角。日语和韩语显示出很强的一致性,表明潜在的文化联系塑造了跨语言实体表示。
作者评估了他们的实体抽取管线在英语中不同文化领域的表现。结果表明,抽取模型在所有测试类别中均实现了一致的高准确率,证明了该方法识别文化实体的可靠性。实体抽取模型在所有文化领域都表现强劲,始终保持高准确率。与食物和饮品相比,书籍、音乐和交通等类别的抽取准确率更高。尽管在不同领域的表现有微小差异,但整体结果始终强劲。
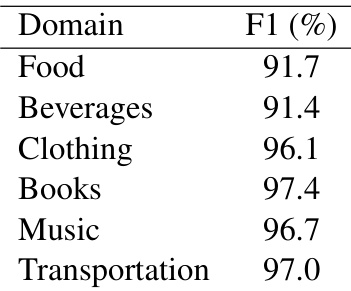
评估通过从不同提示中抽取实体,测量了七个多语言大语言模型的文化多样性、特异性和一致性。像 Llama3-8B 和 Mistral 这样的模型生成了更多独特的文化实体,而 DeepSeek 和 Qwen 则产生了更多重复输出。将 Llama3 的参数从 8B 扩展到 70B,出人意料地降低了多样性。当提示中包含显式文化背景时,文化特异性得到改善,其中英语提示受益最大;而当提示语言与目标国家的母语一致时,中性提示更具特异性。较大的模型取得了更高且更一致的文化一致性分数,尽管较小的模型之间差异很大。分析揭示了欧洲语言之间以及日语和韩语之间强大的区域内一致性,表明训练数据中存在共享的文化视角。