Command Palette
Search for a command to run...
MultiActor-Audiobook:使用多位说话人的面部和声音进行零样本有声书生成
MultiActor-Audiobook:使用多位说话人的面部和声音进行零样本有声书生成
Kyeongman Park Seongho Joo Kyomin Jung
一键部署 Ebook2Audiobook:电子书转有声读物
摘要
我们介绍了 MultiActor-Audiobook,这是一种零样本有声书生成方法,能够自动生成一致、富有表现力且符合说话人特征的韵律(包括语调与情感)。以往的有声书系统存在若干局限性:它们需要用户手动配置说话人的韵律、以单调的语调逐句朗读(相较于专业配音演员),或依赖高昂的训练成本。然而,MultiActor-Audiobook 通过引入两个新颖的流程解决了这些问题:(1)MSP(多模态说话人人格生成)和(2)LSI(基于大语言模型的脚本指令生成)。借助这两个流程,MultiActor-Audiobook 能够在无需额外训练的情况下,生成具有更丰富情感表达且说话人韵律一致的有声书。我们通过人工评估和多模态大语言模型(MLLM)评估,将本系统与商业产品进行了比较,取得了具有竞争力的结果。此外,我们通过消融实验验证了 MSP 和 LSI 的有效性。
一句话总结
MultiActor-Audiobook 是一个零样本框架,通过整合多模态说话人角色生成与基于大语言模型的脚本指令生成,自动为多角色生成一致、富有表现力且符合说话人特征的有声书旁白。该框架无需手动配置韵律或进行高昂的训练,同时在人工与多模态大语言模型(MLLM)评估中展现出媲美商业产品的竞争力。
核心贡献
- MultiActor-Audiobook 是一个零样本框架,通过自动生成一致且符合角色特征的旁白,消除了手动配置韵律和昂贵训练的需求。该系统通过多模态说话人角色生成锚定说话人身份,该模块提取文本特征,合成 AI 人脸图像,并利用预训练的 Face-to-Voice 模型将其映射为独特的语音样本。
- 基于大语言模型的脚本指令生成过程采用 GPT-4o,根据叙事语境和角色人设动态生成句子级别的情感、语调和音高指令。这些结构化提示词使标准文本转语音模型能够输出符合语境且富有表现力的有声书旁白。
- 人工与 MLLM 评估表明,该框架在商业有声书产品中取得了具有竞争力的平均意见得分(MOS),并在自动化评估中实现了 0.225 分的平均提升。消融实验验证了角色生成模块与指令模块均独立促成了韵律一致性与情感表现力的提升。
引言
有声书生成需要将多角色文学作品转换为能够动态匹配情感语境与独特说话人特征的语音。现有系统往往受制于收集大规模训练数据集的高昂成本,或为每个句子手动标注韵律与情感的繁琐流程。作者通过 MultiActor-Audiobook 解决了这些瓶颈,这是一个无需额外训练即可自动化生成富有表现力语音的零样本框架。该系统利用多模态说话人角色流水线,从文本描述和 AI 生成的人脸中生成独特的角色声音,同时基于大语言模型的脚本指令模块为每个句子动态分配具备语境感知能力的情感与语调线索。这种结合使得系统能够跨不同角色实现一致且类似演员的演绎,同时免去了手动配置与高昂的数据收集工作。
数据集
- 数据集构成与来源: 作者结合叙事文本与 AI 生成的视觉内容构建多模态训练语料库。文本基础来源于 ReedsyPrompts,该来源被选中是因为其能够在单一叙事中容纳多个独立的说话人。视觉角色通过 Stable Diffusion 的写实变体模型生成。
- 核心子集详情: 由于音频合成过程中的计算成本较高,仅保留了精心筛选的故事子集。每个选定故事平均包含 4.3 个说话人、175 个句子和 749.56 秒的音频。在视觉组件方面,团队应用了严格的过滤规则,丢弃任何未能清晰呈现人脸的生成结果。
- 数据使用与处理: 过滤后的叙事文本与对应角色被用于训练骨干文本转语音模型。作者特别优先采用写实生成,以保持与主训练集中真实人类语音数据的领域一致性。该精选子集直接用于训练,无需额外的混合比例。
- 元数据与生成策略: 该流水线跟踪说话人数量、句子长度等叙事指标,以确保角色代表的多样性。人脸生成依赖于前一步骤生成的描述文本,并将人脸过滤器作为主要的质量控制机制。尽管未详细说明具体的裁剪操作,但过滤过程确保了仅保留有效的面部区域以供模型集成。
方法
作者利用一个两阶段框架来生成说话人对齐且富有情感表现的有声书,整体架构如图所示。该流程从输入故事开始,故事首先经过多模态说话人角色生成模块以确立独特的角色身份。此阶段涉及使用 GPT-4 从叙事中提取所有说话人(包括旁白),并生成详细描述每个角色外貌与性格特征的说明文本。这些说明文本随后通过 Stable Diffusion 合成面部图像,从而生成每个角色的视觉表征。与此同时,相同的文本描述与面部图像被输入 FleSpeech 模型,生成与每个角色人设相匹配的语音样本。

如图所示,第二阶段采用基于大语言模型的脚本指令生成模块,为每个句子标注适当的情感表达指令。大语言模型通过分析完整的故事语境与对话标记来识别每个句子的说话人,随后分配正确的说话人 ID 与人设。针对每个句子,模型会根据叙事语境与已确立的说话人角色生成简洁的情感指令(如语调、音高与语速),从而确保情感过渡的自然流畅。这些指令与目标文本随后被整合到预生成的面部图像、语音样本与说明文本中。
最终的多模态输入由骨干文本转语音模型 FleSpeech 进行处理,该模型集成了统一的多模态提示词编码器。该编码器基于查询的多层感知机(MLP)与扩散过程,将文本、音频与视觉输入映射到共享表示空间中。针对每个句子,系统输入目标文本、对应的情感指令、说话人面部图像、语音样本与说明文本。在整个故事期间,面部图像与语音样本针对每个角色保持固定,仅文本与情感指令会随句子更新。该设计使得系统能够生成语音与说话人严格对齐、情感表达连贯的自然有声书。
实验
评估设置结合了人工听音测试与多模态大语言模型(MLLM),用于验证角色语音一致性、音频质量、情感传达与说话人识别能力,同时定量分析验证了语音稳定性与情感流畅度。尽管商业平台通过大量训练或手动匹配语音实现了较高的人工评级一致性,但本文提出的系统通过有效利用多模态说话人角色与脚本指令,在自动化评估中取得了最高分。定量结果进一步证实该方法能够保持稳健的语音一致性并生成多样的音高变化,表明其具备出色的情感表现力。总体而言,该系统展示了高效的动态有声书生成能力,尽管未来的改进仍需将骨干 TTS 模型在包含更多样化视觉输入的大型数据集上进行训练。
作者对本文系统与多个基线模型进行了定量对比分析,重点关注说话人嵌入相似度与音高转折点,以此作为语音一致性与情感表现力的衡量标准。结果表明,本文系统在两项指标上均取得最高值,说明其在整个音频样本中具备极强的语音一致性与丰富的情感变化。尽管 ElevenLabs 在人工评估的角色语音一致性方面表现优异,但本文系统在维持说话人身份与表达情感细微差别方面展现出更优的性能。该系统在说话人嵌入相似度和音高转折点数量上均居首位,进一步印证了其卓越的语音一致性与情感表现力。ElevenLabs 在人工评估中得分较高,但在说话人相似度与音高变化的定量指标上表现较弱。本文系统在维持一致的说话人身份及生成情感丰富的语音模式方面优于基线模型。
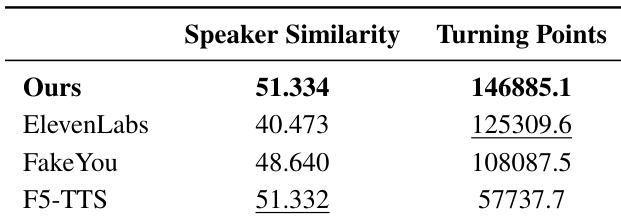
作者结合人工评估与 MLLM 评估,将本文系统与多个基线模型进行对比,重点考察角色语音一致性、音频质量、情感表达与说话人识别。结果表明,该系统在维持语音一致性与情感表现力方面表现良好,在说话人嵌入相似度与音高变化指标上表现强劲,尽管部分基线模型在特定人工评估中得分更高。该系统在说话人嵌入相似度与音高转折点数量上均取得最高分,表明其具备出色的语音一致性与情感表现力。ElevenLabs 在角色语音一致性的人工评估中得分最高,而本文系统在同一指标的 MLLM 评估中位居榜首。该系统在说话人识别方面优于基线模型,并在各项评估中保持了较高的音频质量。

本文提出的系统通过定量分析、人工评估与机器学习模型评估,与多个基线模型进行了对比,以验证语音一致性、情感表现力与角色匹配度。结果表明,该系统在维持稳定的说话人身份的同时,能够生成高度细腻的情感语音模式,在自动化与基于模型的评估中持续优于竞争对手。尽管部分基线模型在角色语音一致性方面获得了更高的人工评分,但本文方法在说话人识别与整体音频质量上展现出更优的能力。最终,研究结果证实该系统能够在多样化的语音样本中,有效平衡一致的发声身份与丰富的情感变化。