Command Palette
Search for a command to run...
Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
一键部署 Triton 编译器教程
摘要
随着单芯片扩展逐渐接近其瓶颈,单个加速器已无法支持现有大语言模型的训练和推理。因此,使用由多个加速器组成的分布式系统进行训练和推理已成为迫切需求。在分布式系统中,存在三个基本活动并发执行:计算、内存访问和通信。在现有的训练/推理框架中,这些方面通常在不同编程级别被独立优化。因此,这些活动难以相互协调,从而无法释放集群的全部性能潜力。在本报告中,我们提出了 Triton-distributed,这是对现有 Triton 编译器的扩展,旨在克服分布式 AI 系统中的编程挑战。Triton-distributed 是首个支持分布式 AI 工作负载原生重叠优化的编译器,提供了对不同框架中现有优化的良好覆盖。首先,我们将符合 OpenSHMEM 标准的通信原语集成到编译器中。这使得程序员能够以更高阶的 Python 编程模型利用这些原语。
一句话总结
Triton-distributed 通过将符合 OpenSHMEM 标准的原语集成到 Python 编程模型中,扩展了 Triton 编译器,使其能够原生地实现分布式 AI 工作负载中的计算、内存访问与通信的重叠。该框架通过协调集群的并发操作,旨在最大化大语言模型训练与推理的性能。
核心贡献
- 本报告介绍了 Triton-distributed,这是一种编译器扩展,它将符合 OpenSHMEM 标准的通信原语集成到 Python 编程模型中,以统一分布式计算与计算内核的开发。
- 该框架通过自动将编译器辅助的原语下推至 NVSHMEM 或 ROCSHMEM,实现了原生的细粒度计算-通信重叠。开发者仅需进行极少的代码修改即可实现复杂分布式工作负载,同时达到与底层实现相当的性能。
- 在 Nvidia 和 AMD GPU 上的评估表明,在包括 AllGather GEMM、GEMM ReduceScatter 以及专家并行 AllToAll 在内的多种工作负载下,其性能相较于 NCCL 和 RCCL 提升了 1.09 倍至 44.97 倍。
引言
大语言模型的快速扩展已将 AI 部署从单一加速器转向分布式多节点集群,使得计算与通信重叠成为维持吞吐量和控制基础设施成本的关键。以往的分布式编程方法难以适应这一转变,因为它们通常针对 CPU 集群设计,需要复杂的底层 CUDA 或 C++ 工程开发,或依赖会疏远 Python 算法开发者的专有领域特定语言。这种工作流脱节迫使开发者进行跨语言开发,抑制了生产力,并将高级优化限制在拥有卓越工程资源的团队中。为弥补这一差距,研究团队引入了 Triton-distributed。该编译器扩展基于开源 Triton 框架构建,完全在 Python 环境中实现了细粒度的计算与通信重叠。通过将高级原语直接编译为优化的加速器代码,该方法能够提供与手写实现相媲美的性能,同时大幅降低开发开销并支持多样化的硬件架构。
方法
研究团队为分布式 AI 工作负载采用了一种基于编译器的编程模型,该模型以 MPMD(多程序多数据)范式为核心,支持计算、内存访问和通信任务的并发执行与协调。该模型的核心包含三个关键概念:对称内存、信号交换和异步任务。对称内存为每个 rank 提供全局作用域的内存缓冲区,每个缓冲区位于独立的地址空间中,因此无法通过指针直接进行远程内存访问,必须使用通信原语。信号交换通过在对称内存中存储数据对象,促进 rank 之间的一致性协调,支持设置、递增、检查和自旋锁等信号操作。异步任务将数据传输和计算等操作视为可并行运行的异步单元,并通过信号进行同步,其具体实现细节因硬件后端而异——对于 GPU,多流和多线程是常见的实现方式。
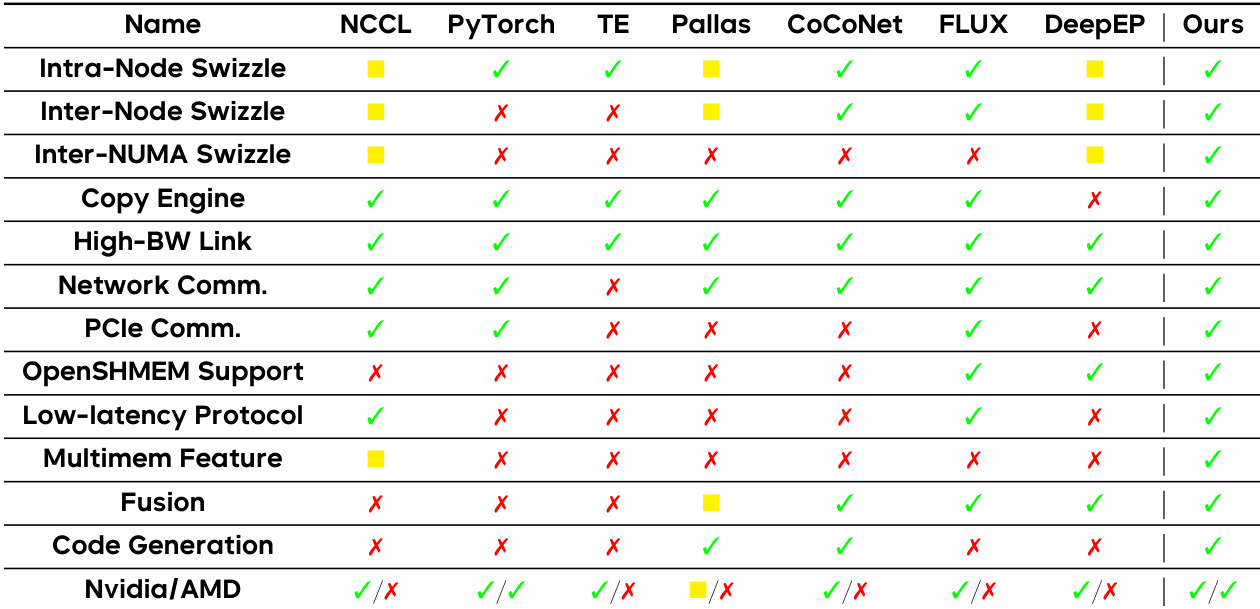
该编译器集成了符合 OpenSHMEM 标准的通信原语,使程序员能够通过高级 Python 编程模型使用这些原语。这些原语包括 OpenSHMEM 实现(Nvidia GPU 的 NVSHMEM 和 AMD GPU 的 ROCSHMEM)以及非 OpenSHMEM 原语(例如 wait、consume_token、notify),后者专为流水线化和低延迟通信等特定优化目的而设计。例如,wait 和 consume_token 原语用于在信号操作与后续内存访问之间建立数据依赖关系,从而实现细粒度同步。该框架支持广泛的优化重叠策略,如表 2 所示,涵盖节点内与节点间 swizzling、拷贝引擎利用、高带宽链路映射、网络通信优化、PCIe 调度,以及硬件特定特性(如 Nvidia 的 TMA 指令和 AMD 的持久化内核优化)。
如图 1 所示,该编译器架构作为 Triton 编译器的扩展运行。用户使用 Python 编写程序,通常使用 compute.py 文件处理计算,使用 communication.py 文件处理通信,两者被编译为统一的 IR。该 IR 由 Triton 编译器后端处理,生成 TTIR 和 TTIIR 等中间表示。随后,编译器将其转换为 LLVM IR,并进一步优化和下推为特定于目标的代码,包括 Nvidia GPU 的 PTX 和 AMD GPU 的 AMDGCN。编译工作流集成了 SHMEM.bc lib 和 extra.ll lib 等硬件特定库,以生成能高效利用底层硬件能力的代码。该设计使编译器能够生成针对单节点和多节点场景均可优化的代码。
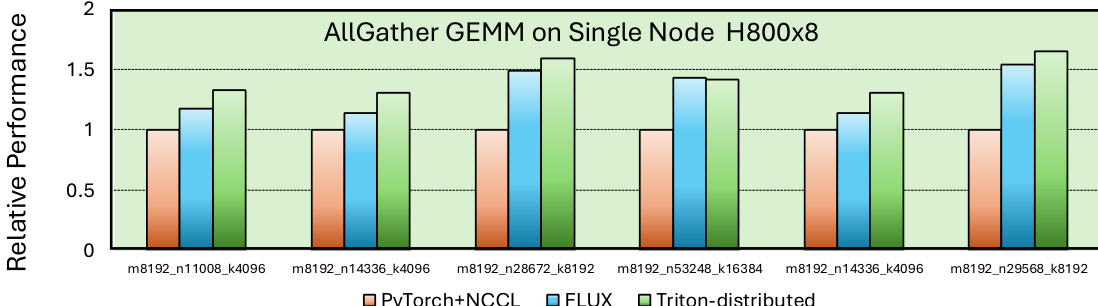
为演示该编程模型,研究团队提供了一个节点间重叠的 AllGather GEMM 示例。程序的通信部分被分配至不同的 threadblock,其中部分负责节点内数据传输,其余负责节点间数据传输,从而实现并行运行。计算部分复用了 Triton 的 GEMM 实现,并添加了 wait 和 consume_token 原语以建立数据依赖,实现通信与计算的重叠。主机端代码负责分配对称内存,并在不同的 stream 上启动通信与计算部分,确保两项任务可并发执行。如图 3 所示的执行时间线展示了计算任务如何与跨 rank 的通信任务并行运行。
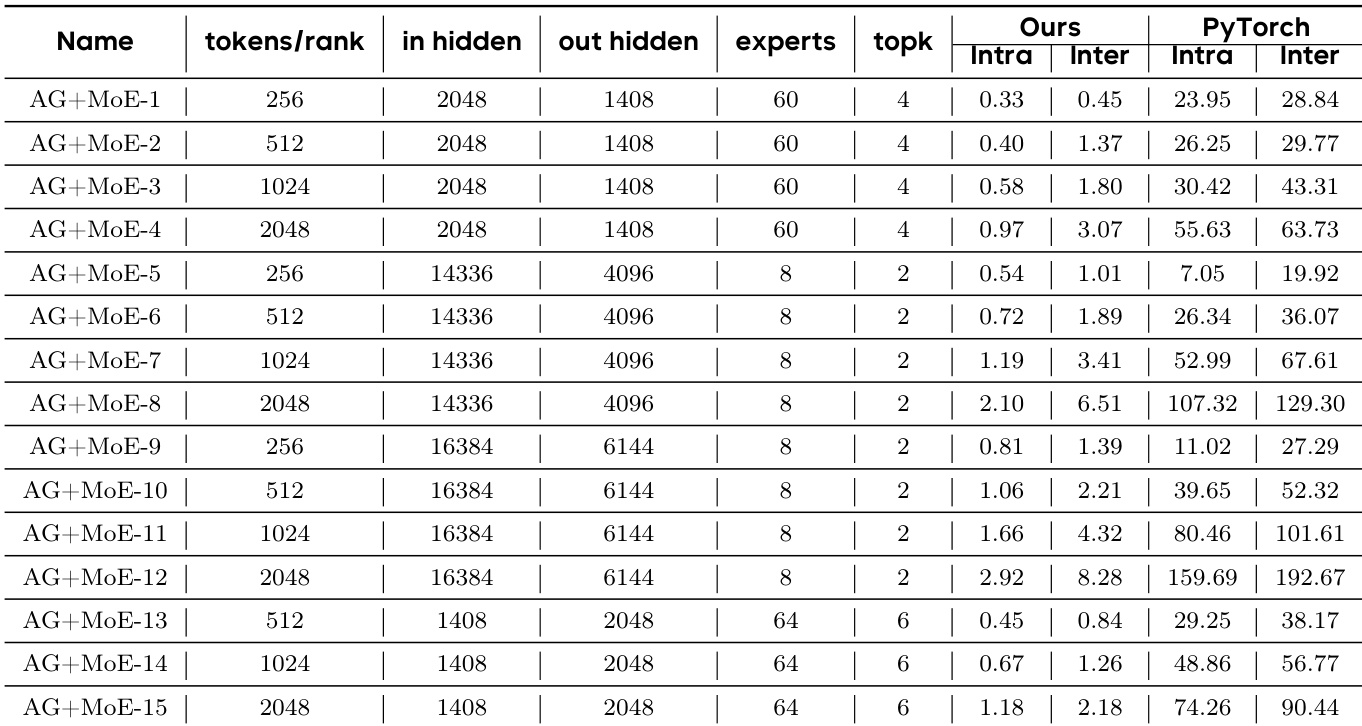
该框架实现细粒度重叠的能力通过针对不同优化目的的内核实现得到进一步验证。对于节点内 AllGather,编译器利用拷贝引擎进行数据传输,可根据是否需要控制数据到达顺序选择 push 或 pull 模式。类似地,节点内 ReduceScatter 采用 push 模式实现,在生成 tile 后将本地数据分片推送至其他 rank,归约操作并行运行并通过信号同步。对于节点间 AllGather,编译器在短消息场景下采用低延迟协议(LL),将数据与标志位共同存储在 8 字节块中,并使用自旋锁检查到达状态。该方法避免了每次传输的信号操作开销,从而降低延迟。编译器还支持具有异构通信特性的节点间 ReduceScatter,其中节点内 scatter 调度在一个 stream 上,而本地归约与节点间 P2P 通信分配至另一个 stream,以最大化带宽并最小化资源争用。
编译器通过 tile swizzling 和代码生成技术进一步提升了性能。Swizzling 控制 tile 的处理顺序,以最大化重叠并最小化延迟。对于使用 NVSwitch 的 Nvidia GPU,swizzle 顺序确保每个 rank 每次仅从另一个 rank 收集数据,从而充分利用 NVLink 带宽。对于采用全互联拓扑的 AMD GPU,swizzle 顺序允许每个 rank 同时从所有其他 rank 收集数据,以最大化可用带宽。资源划分确保计算和通信任务映射到不同的处理单元(例如计算使用 SM,通信使用拷贝引擎),以避免争用并实现完美重叠。编译器的自动调优器专为分布式内核设计,同时考虑内核启动的同步需求和设备间调优结果的同步,从而能够发现全局最优配置。
实验
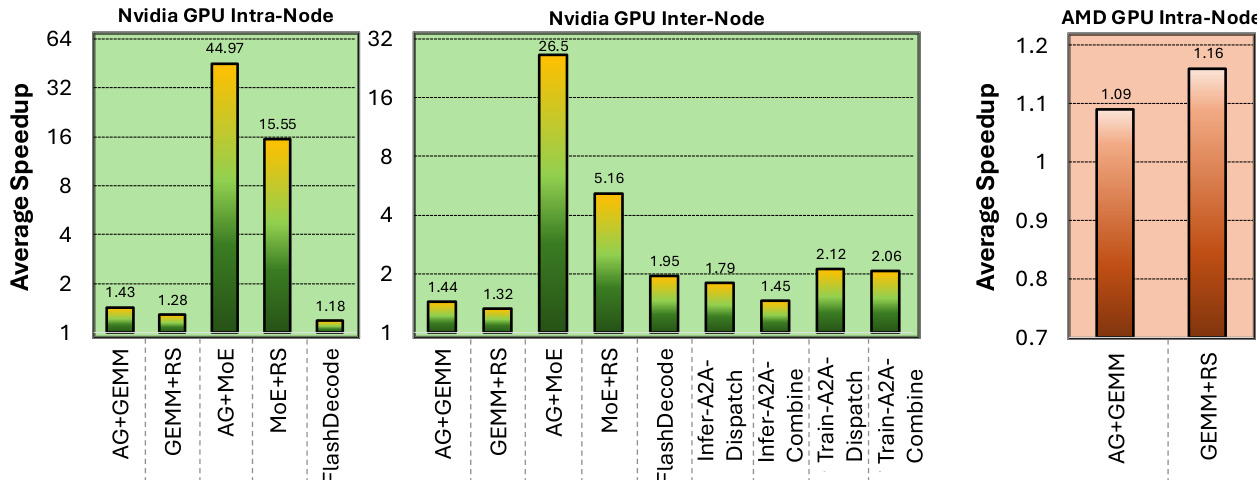
评估测试在规模从 8 到 64 个设备的 Nvidia 和 AMD GPU 集群上,对节点内和节点间配置下的优化型通信-计算重叠内核进行了测试。实验针对标准基线验证了 GEMM、ReduceScatter、AllGather 和 MoE 路由操作的效率,同时分布式 flash decoding 基准测试验证了扩展硬件上的持续高带宽利用率。编译器生成的实现在需要大幅减少代码量的情况下,始终匹配或超越手动调优的库,展现了在不同加速器和互连技术上的强通用性。最终,研究证实这些重叠策略与分布式内核能有效加速大规模模型训练与长上下文推理。
研究团队在多种硬件与通信框架上评估了优化内核,并将性能与 PyTorch、NCCL、FLUX 和 DeepEP 等多个基线进行比较。结果表明,该方法在节点内和节点间通信场景中相较于基线实现实现了显著加速,同时展现了对不同 GPU 架构和通信协议的兼容性。研究团队强调,即使采用更简单的实现方式,其编译器生成的代码仍能取得与最先进方案相媲美的性能。所提方法在节点内和节点间通信内核中相较于 PyTorch+NCCL 和 FLUX 基线实现了大幅加速。该系统在不同 GPU 架构(包括 Nvidia 和 AMD GPU)及通信后端(包括 NVLink 和 PCIe 网络)上表现出强兼容性。编译器生成的代码在简化内存管理并降低代码复杂度的情况下,仍能达到与手动优化实现相当的性能。
研究团队在不同 GPU 架构与通信场景下评估了优化内核的性能,并将该方法与多种基线进行比较。结果表明,Nvidia GPU 上的节点内和节点间操作获得了显著加速,而 AMD GPU 上的提升相对温和,特别是在 AllGather 和 ReduceScatter 内核上。性能因内核类型和扩展策略而异,部分操作展现出强扩展性,而其他操作则受限于通信开销。该方法在 Nvidia GPU 的节点内操作中实现了大幅加速,其中 AllGather GEMM 和 MoE ReduceScatter 的改进尤为明显。节点间性能相较于基线保持稳定增长,在 Nvidia 硬件上与最先进实现相比接近峰值效率。在 AMD GPU 上,性能具有竞争力但略低于优化的原生库,关键通信内核观察到适度的加速。
研究团队展示了不同配置与硬件平台(包括 Nvidia 和 AMD GPU)上各种内核优化的性能结果。实验评估了节点内和节点间操作,重点比较了相较于 PyTorch+NCCL 和 FLUX 等基线实现的加速效果,以及不同通信策略与架构之间的差异。所提出的优化方法在多种内核类型和硬件平台上相较于 PyTorch+NCCL 等基线方法实现了显著加速。性能提升在节点内和节点间操作中有所不同,部分内核在跨节点扩展时展现出比其他内核更好的可扩展性。该方法在 Nvidia 和 AMD GPU 上均表现出强劲性能,表明其在不同硬件架构上具有通用性与有效性。
研究团队在 Nvidia 和 AMD GPU 集群的节点内与节点间配置上评估了优化型重叠内核的性能。结果显示,相较于基线实现始终保持加速,尤其在节点内场景中表现突出,而在扩展至多节点时可扩展性存在差异。所提内核在节点内设置下相较于 PyTorch+NCCL 和 FLUX 实现了显著加速,性能提升幅度在 1.28 倍至 44 倍以上。节点间扩展显示基于 AllGather 的内核具有良好的弱扩展性,但基于 ReduceScatter 的内核性能未达最优,表明需要专门的优化。该方法在 AMD GPU 上取得了具有竞争力的性能,即使与厂商提供的优化库相比也实现了加速,展现了其通用性。
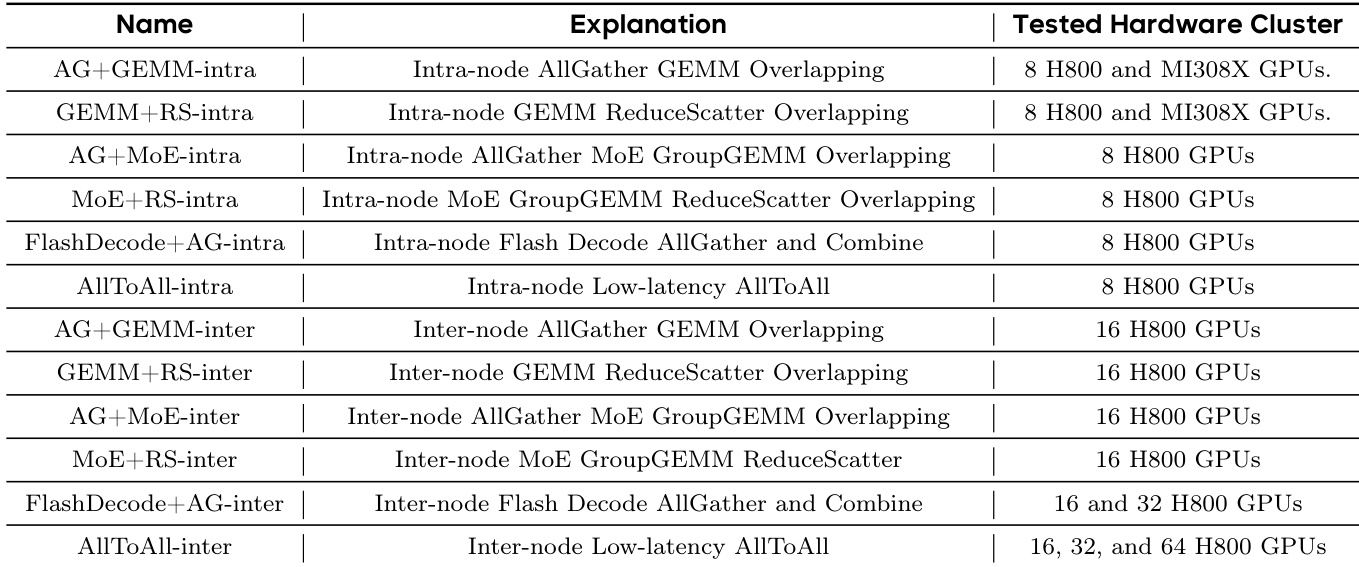
研究团队在不同数量的 GPU 上比较了其分布式 AllToAll 内核与 DeepEP 的性能。结果表明,Triton-distributed 实现在大多数情况下优于 DeepEP,特别是在 AllToAll Combine 操作上,而在 GPU 数量较多时,AllToAll Dispatch 操作的性能略低。该性能优势在 8 卡和 16 卡配置中保持一致,且在 32 卡和 64 卡配置下差距进一步扩大。在所有 GPU 数量下,Triton-distributed 实现在 AllToAll Combine 操作上的性能均高于 DeepEP。对于 AllToAll Dispatch 操作,Triton-distributed 方法在 64 卡时表现劣于 DeepEP。随着 GPU 数量从 8 扩展至 64,两种实现之间的性能差距逐渐增大。
实验在 Nvidia 和 AMD GPU 上评估了编译器生成的通信内核,并将其与 PyTorch+NCCL、FLUX 和 DeepEP 等成熟基线进行基准测试,以验证其在节点内和节点间配置下的性能。结果表明,优化方法相较于现有实现始终提供显著加速,特别是在 AllGather 和 AllToAll Combine 等集合通信操作中,同时在不同硬件架构和网络协议上保持了强兼容性。由于固有的通信开销,不同内核类型的扩展效率存在差异,但该系统证明,简化的编译器驱动代码生成能够匹配甚至超越手动优化的厂商库。最终,该研究证实所提方法为高性能分布式通信提供了一种高效且广泛兼容的替代方案。