Command Palette
Search for a command to run...
Capybara-OMNI:构建 OMNI-MODAL 语言模型的高效范式
Capybara-OMNI:构建 OMNI-MODAL 语言模型的高效范式
Xingguang Ji Jiakang Wang Hongzhi Zhang Jingyuan Zhang Haonan Zhou Chenxi Sun Yahui Liu Qi Wang Fuzheng Zhang
一键部署统一视觉创作模型 Capybara
摘要
随着多模态大语言模型(Multimodal Large Language Models, MLLMs)的不断发展,开源社区涌现出众多卓越成果。然而,由于构建与训练多模态数据对的过程极为复杂,开发强大的多模态大模型(MLM)仍是一项计算密集且耗时的工作。本文提出 Capybara-OMNI,这是一款采用轻量级高效训练方式的多模态大模型,支持对文本、图像、视频及音频等多种模态的理解。我们详细阐述了其框架设计、数据构建方法以及训练策略,旨在逐步构建具备竞争力的 MLM。此外,我们还提供了实验中使用的专属基准测试(benchmark),以展示如何恰当评估模型在不同模态下的理解能力。实验结果表明,遵循本文提出的方法,可以高效地构建出在多种多模态基准测试中达到同规模模型竞争力的 MLM。为进一步增强模型的多模态指令遵循与对话能力,我们进一步探讨了如何在基础理解型 MLM 之上训练对话版本,使其更契合用户在实时人机交互等任务中的使用习惯。目前,我们已公开 Capybara-OMNI 模型及其对话版本。
一句话总结
作者介绍了 Capybara-OMNI,这是一种用于构建全模态语言模型的高效范式。该范式通过轻量级的训练配方、框架设计和数据构建,支持理解文本、图像、视频和音频模态,从而在同规模模型的各种多模态基准测试中实现具有竞争力的性能,同时公开了基础模型和基于对话的版本,以便与人类进行实时交互。
核心贡献
- 本工作介绍了 Capybara-OMNI,这是一种全模态语言模型,通过轻量级且高效的训练过程支持文本、图像、视频和音频理解。
- 论文详细阐述了框架设计和训练配方,增强了指令遵循能力,使得开发基于对话的版本以实现实时交互成为可能。
- 实验结果表明,利用提供的专属基准来验证不同模态的理解能力,该模型在各种多模态基准测试中表现出具有竞争力的性能。
引言
多模态大语言模型对于推进人机交互至关重要,它使系统能够同时处理文本、图像、视频和音频。尽管潜力巨大,但由于对齐不同数据模态的复杂性,训练这些模型的计算成本仍然很高。先前的工作通常面临相互干扰的挑战,即如果没有精心设计,添加音频能力会显著降低视觉理解能力。作者介绍了 Capybara-OMNI,通过支持全模态输入的轻量级训练范式来解决这些问题。他们的方法利用优化的数据构建和训练配方,在跨模态实现竞争力的同时,显著降低了资源需求。
方法
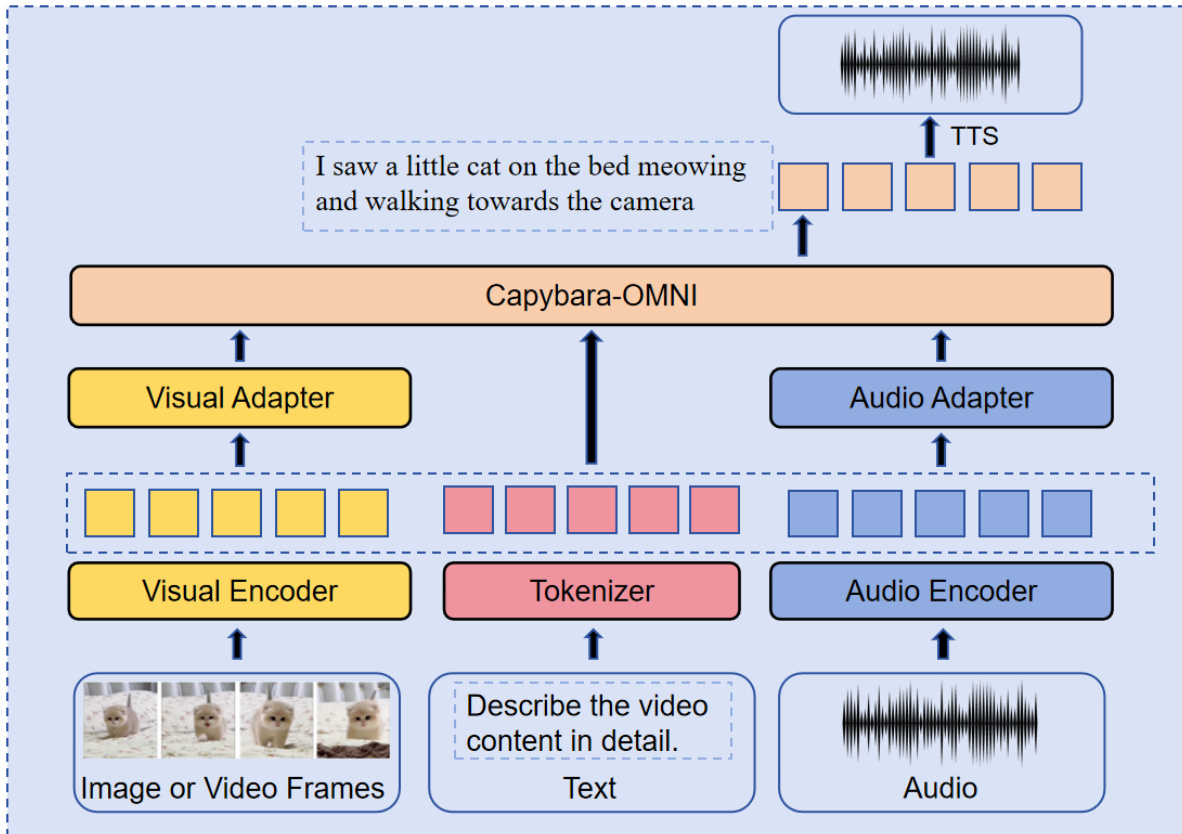
作者基于 Capybara-VL-7B 架构构建了 Capybara-OMNI 模型,将视觉、音频和文本模态集成到统一框架中。有关详细的系统结构,请参阅框架图。视觉模块采用 SigLIP 视觉编码器,通过双层 MLP 适配器连接到大型语言模型(LLM)。为了适应可变宽高比和高分辨率图像,系统对位置嵌入进行插值,并将图像分割为子图像,通过 2×2 双线性插值将视觉token从 1024 减少到 256。音频模块利用从 Whisper-large-v3 初始化的编码器,通过单层 MLP 将音频特征投影到 LLM 空间。核心 LLM 是 Qwen2.5-7B,用于处理统一的token序列。
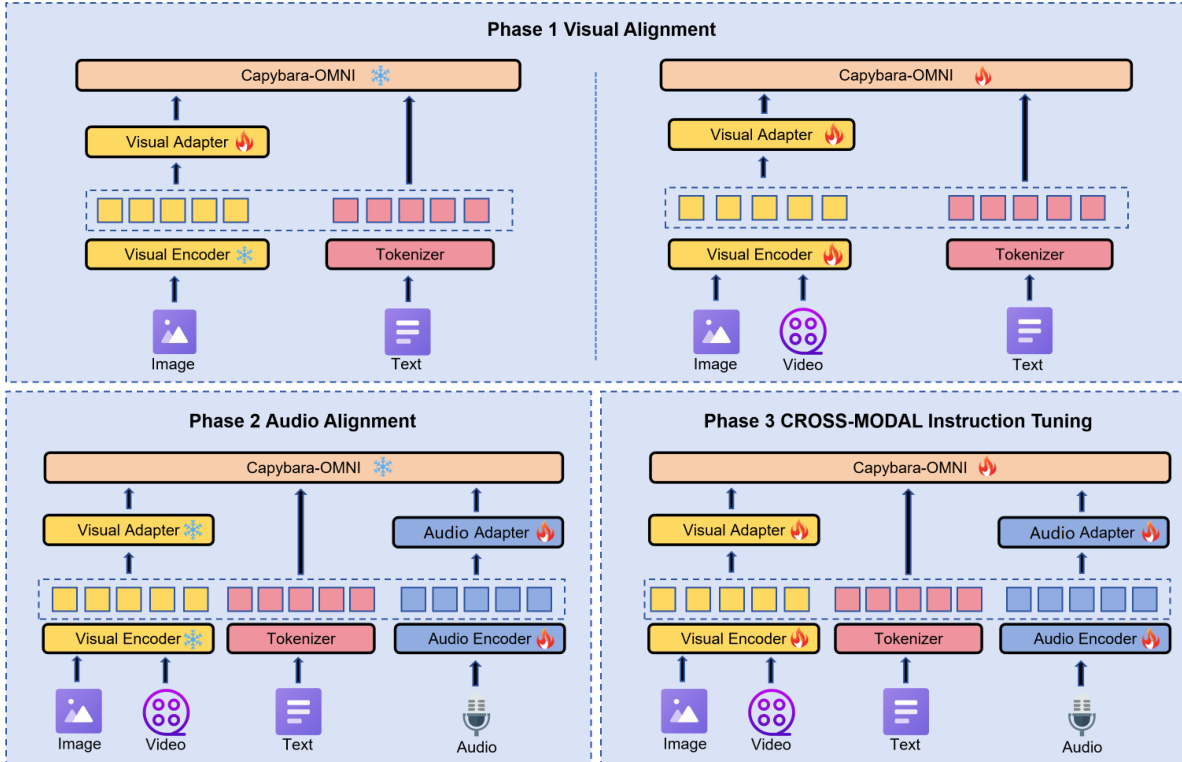
训练过程分为三个阶段:视觉对齐、音频对齐和跨模态指令微调。如下图中所示,作者在每个阶段利用特定的冻结策略来有效管理参数更新。
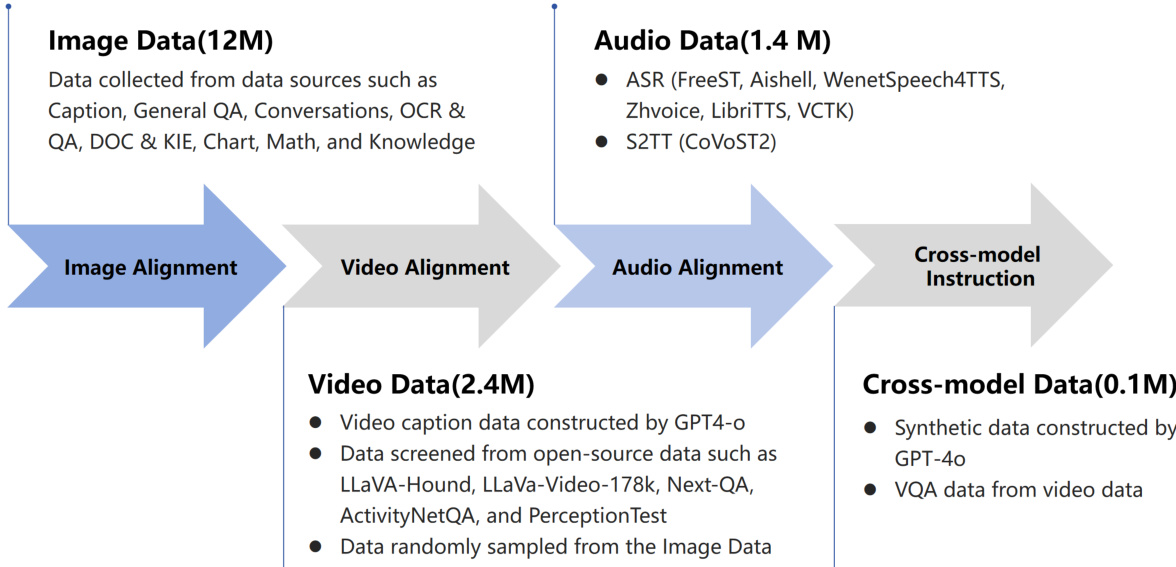
在视觉对齐阶段,模型获取图像和视频理解能力。训练数据构建过程如下图所示。作者从不同来源收集了约 1200 万图像样本和 240 万视频样本。该阶段包含三个子阶段。最初,LLM 和视觉编码器被冻结,同时训练适配器以进行粗粒度对齐。后续阶段解冻所有参数,以细化细粒度视觉概念并处理分割为最多九个子图像的高分辨率输入。
在音频对齐阶段,重点转向语音理解,同时保持视觉性能。遵循 Freeze-Omni 策略,LLM 和视觉组件保持冻结。仅音频编码器和适配器在约 140 万 ASR 和 S2TT 数据实例上进行训练。这种方法防止了对前一阶段学习到的视觉能力的灾难性遗忘。
最后,跨模态指令微调阶段整合所有模态以进行复杂交互。作者使用 GPT-4o 生成合成数据,并使用文本转语音(TTS)将基于文本的 VQA 数据转换为音频。在此最终阶段,所有模型参数都被激活并更新,以优化跨模态理解和对话能力。
实验
Capybara-OMNI 的多模态理解能力使用标准开源基准在图像、视频和音频任务中进行评估,以确保现实比较。该模型在视觉领域表现出具有竞争力的性能,经常超越更大的开源模型并与闭源系统相媲美,而视频结果强调了其训练策略在保留能力方面的有效性。此外,音频实验证实了与专用模型相比的强大性能,消融研究验证了高质量编码器初始化和数据筛选显著提高了音频理解能力。
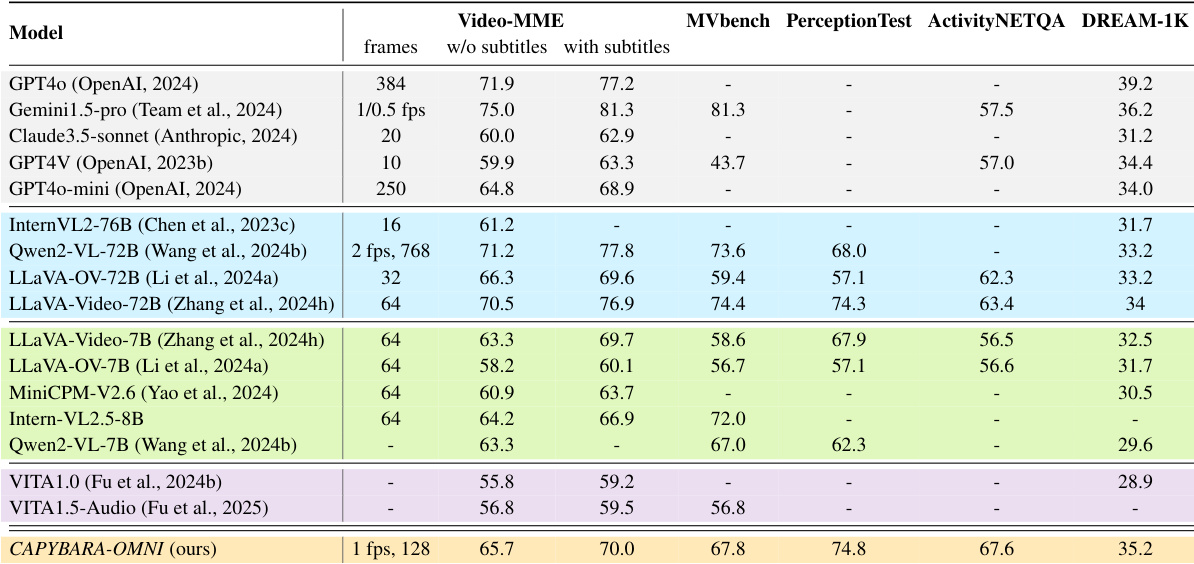
下表将 Capybara-OMNI 与各种私有和开源模型在多个视频理解基准上进行了比较。结果表明,所提出的模型实现了具有竞争力的性能,经常超越规模相似的开源模型和以前的全模态架构。Capybara-OMNI 在 Video-MME 和 MVbench 上优于可比的开源模型。与更大的 72B 模型相比,该模型在 PerceptionTest 上取得了更高的分数。在所有列出的指标上,性能均超过以前的全模态模型如 VITA1.5。
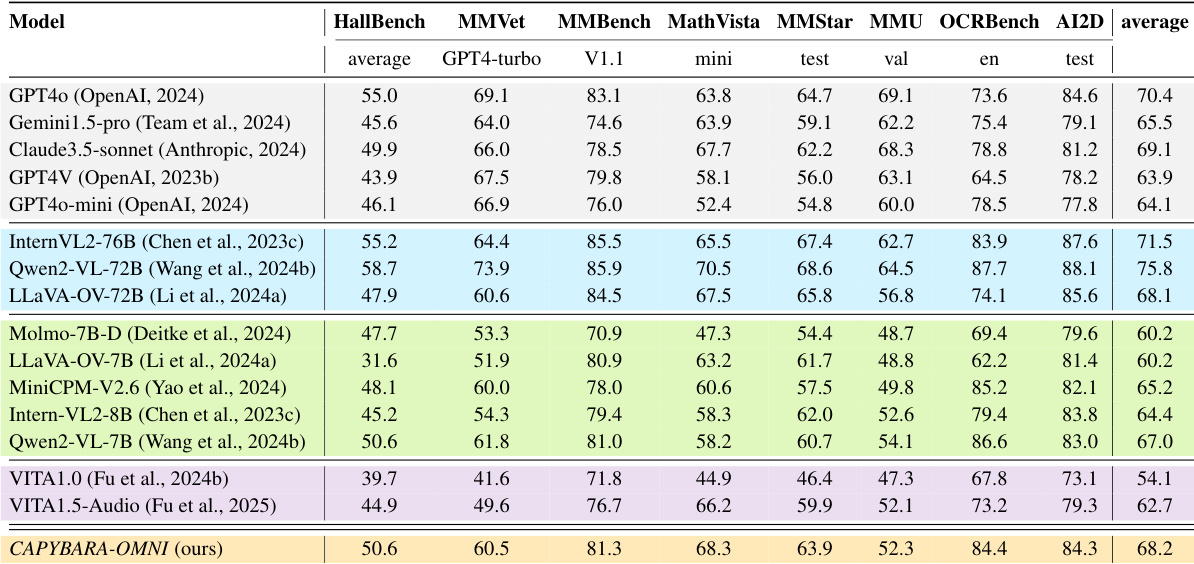
下表将 Capybara-OMNI 与各种私有和开源视觉语言模型在八个不同的基准上进行了比较。结果表明,所提出的模型实现了具有竞争力的平均性能,显著超越了几个更大的开源模型和闭源基线。它在科学图表理解和数学推理方面表现出特别的优势,经常与显著更大的参数模型性能相匹配。Capybara-OMNI 在总体平均分数上优于 GPT4o-mini 和 LLaVA-OV-72B。该模型在 AI2D 和 MathVista 基准上取得了顶级结果。与更大的 72B 和 76B 参数模型相比,性能仍然具有竞争力。
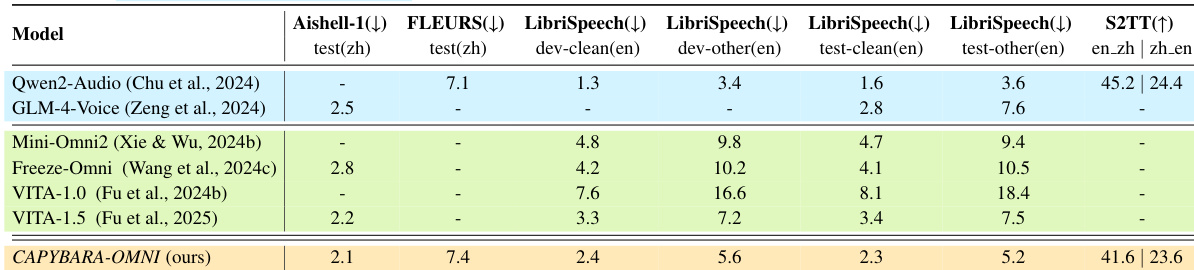
下表评估了中英文 ASR 任务和语音转文本翻译的音频理解能力。Capybara-OMNI 表现出具有竞争力的性能,特别是在中文 ASR 方面,它优于 GLM-4-Voice 等专用模型。虽然略逊于初始化模型 Qwen2-Audio,但在几个英文基准上,它超越了其他开源全模态模型。Capybara-OMNI 在 Aishell-1 中文 ASR 基准上取得了顶级性能。该模型在英文 LibriSpeech 任务上优于其他全模态竞争对手如 VITA-1.5。结果表明,与开源替代方案相比,语音转文本翻译具有很强的竞争力。
下表说明了通过特定的架构和数据修改对音频理解能力的逐步增强。使用 Qwen2-Audio 编码器初始化模型相比基线产生了显著的性能提升。应用数据增强后观察到进一步改进,降低了多个基准的错误率。使用 Qwen2-Audio 编码器初始化相比基线产生了显著改进。数据增强进一步提高了所有测试基准的音频能力。最终配置在 ASR 和翻译任务上均取得了最佳性能。

实验在视频、图像和音频理解基准上评估了 Capybara-OMNI,并与一系列私有和开源基线进行了比较。结果表明,该模型在视频和图像任务中实现了具有竞争力的性能,经常超越规模相似的开源架构,并在科学和数学推理方面与更大的模型相匹配。音频评估显示在语音识别和翻译方面具有很强的能力,而消融研究验证了使用专用编码器初始化和应用数据增强显著增强了这些功能。