Command Palette
Search for a command to run...
嵌入的简介及语义嵌入的实现
摘要
一句话总结
本文通过引入一种新颖的合成数据生成流程,推动了大语言模型语义缓存技术的发展。该流程使经过单轮训练微调的紧凑型领域特定嵌入模型,在精确率和召回率上超越当前最先进的开源与专有替代方案,同时在计算开销与检索精度之间保持最佳平衡。
核心贡献
- 本文提出了一种针对紧凑型嵌入模型(包含 ModernBERT)的微调策略,将训练限制在单个 epoch,使这些架构在精确率和召回率上超越当前最先进的开源与专有替代方案。
- 开发了一种新颖的合成数据生成流程,用于生成面向语义缓存的针对性训练样本,弥补领域标注数据的不足,并使精确率较未训练的基线模型提升 9%。
- 在医疗与 Quora 数据集上的评估表明,微调期间将梯度范数约束为 0.5 可有效缓解灾难性遗忘,在保持跨领域泛化能力的同时,于医疗数据集上实现 4% 的精确率提升。
引言
大语言模型驱动着现代应用,但需要庞大的计算资源,这使得语义缓存成为处理重复用户查询时降低延迟与成本的关键技术。选择最优嵌入模型依然具有挑战性,因为开源方案计算开销大,而闭源服务则带来费用与网络延迟。高效的小型模型提供了有前景的替代方案,但通常在不进行微调的情况下性能不佳;而微调需要稀缺的高质量数据集,且在长期训练中面临灾难性遗忘的风险。为突破这些限制,研究团队采用轻量级嵌入模型,将其限制在单个 epoch 内进行微调,并通过约束梯度范数来保留通用知识。此外,本文还引入了一种合成数据生成流程,用于生成领域特定的训练样本,使紧凑型模型在语义缓存精确率上达到或超越当前最先进的专有与开源嵌入模型。
数据集

- 数据集构成与来源: 研究团队利用来自医学等专业领域开源仓库的未标记查询日志,构建了一个合成数据集,以解决语义缓存领域高质量标注数据稀缺的问题。
- 子集详情: 该数据集包含两类由大语言模型生成的样本。正样本对由保留原始意图但表述不同的改写查询组成,标记为重复项。负样本对则包含主题相关但在临床重点或子领域上存在差异的查询,标记为不同项。
- 数据用途与训练策略: 研究团队使用合成样本对嵌入模型进行微调,以提升近重复项检测能力,同时降低误报与漏报率。训练过程被刻意限制在单个 epoch 内,并采用适度约束的梯度范数,以防止灾难性遗忘并保留跨领域泛化能力。
- 处理与流程详情: 一个双标签框架通过结构化提示词引导大语言模型,同时生成上述两类子集。该流程能够捕捉语义边界案例与领域特定术语,简化了数据准备过程,无需人工裁剪或构建外部元数据。
方法
研究团队采用一种包含三个组件的方法论,通过专用嵌入模型提升语义缓存的效能。该方法的核心在于选择并微调一款紧凑型、高效的基于 Transformer 的嵌入模型,该模型专为满足生产级缓存系统的典型计算约束而设计。研究团队选用 ModernBERT(一种仅含编码器架构、参数量为 1.49 亿的 Transformer 模型),因其在性能与效率之间取得了优于 BERT、RoBERTa 和 NomicBERT 等更大规模模型的平衡。该模型构成了领域自适应嵌入系统的基础,专门针对专业领域的语义相似度任务进行优化。

框架示意图展示了从原始输入生成改写查询的过程,这是构建领域特定微调训练数据的关键步骤。系统接收原始查询后,会生成多个语义等价但探索不同子主题、视角或临床语境的变体,在保持核心语义的同时确保多样性。例如,针对查询“减少压力的最佳方法是什么?”,模型会生成如“个人如何有效管理压力?”和“哪些策略有助于降低压力水平?”等改写版本。这些生成的查询随后被用于构建正样本对数据集(即语义相似的查询实例),这对对比学习至关重要。
微调过程采用在线对比损失函数,该函数在训练模型区分细微语义差异方面尤为有效。如图下方所示,该方法聚焦于每个训练批次中“最难”的样本,即模型当前判定为不相似的正样本对,以及判定为相似的负样本对。通过将训练目标集中在这类困难样本上,模型能够学习到更具判别性的特征,从而加快收敛速度并提升重复查询识别的精确率。这对语义缓存至关重要,因为检测语义等价查询的准确率直接决定缓存命中率。经过微调的模型(命名为 LangCache-Embed)在基线模型与当前最先进模型对比中,展现出精确率与召回率的显著提升,尤其在领域特定数据上表现突出。
实验
评估过程在通用与专业医疗数据集上对 ModernBERT 进行微调,并在真实硬件约束下将其与顶尖的开源及专有嵌入模型进行基准测试。实验验证了定向领域适配能显著增强语义匹配能力,同时合成数据生成成功弥补了标注缺口,且未牺牲准确性。最终,该方法在极高检索精确率与极低嵌入延迟之间取得了最佳平衡,被证明对实时语义缓存系统高度有效。
研究团队在两个数据集上评估了 LangCache-Embed(ModernBERT 的微调版本)的性能,证明领域特定微调能显著提升精确率、召回率与平均精度等关键指标。结果表明,LangCache-Embed 在多项评估指标上均优于开源与闭源模型,尤其在精确率与平均精度方面提升显著。此外,该模型实现了较低的嵌入生成开销,使其适用于实时语义缓存应用。在 Quora 与医疗数据集上,领域特定微调大幅增强了 LangCache-Embed 在精确率、召回率及平均精度上的表现。该模型在平均精度与精确率等关键指标上领先于主流开源与闭源嵌入模型。LangCache-Embed 的低嵌入生成开销使其成为实时语义缓存应用的最优选择。
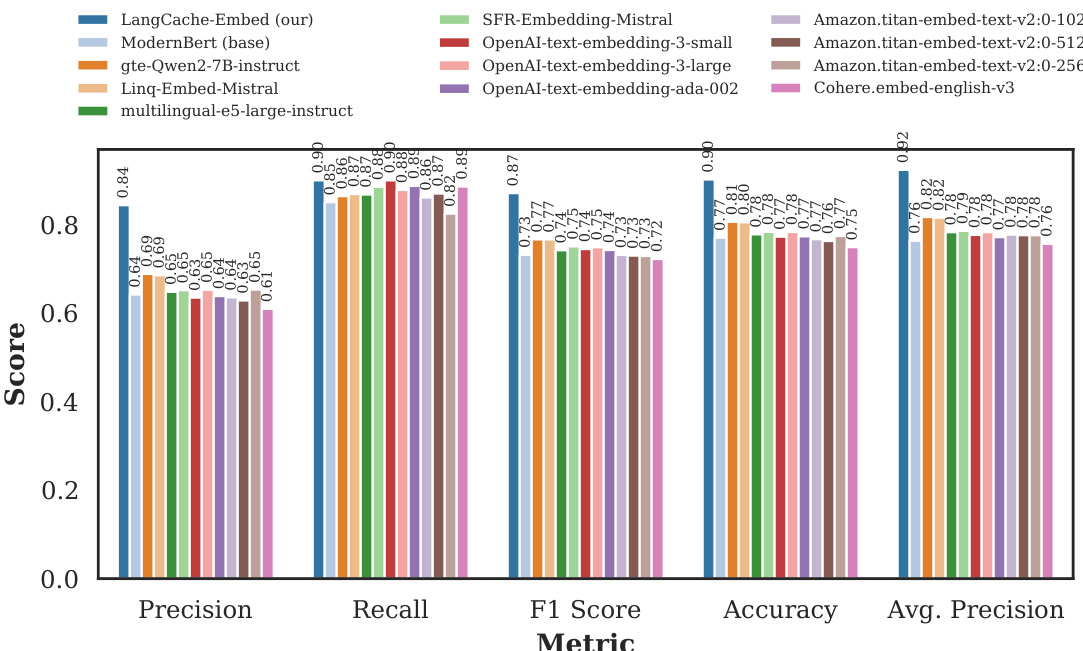
研究团队利用 Quora 与医疗领域数据集,在语义相似度任务上评估了 LangCache-Embed 的性能。结果显示,领域特定微调在多指标上显著提升了模型表现,且该模型与当前最先进的开源及闭源嵌入模型相比具备竞争力,在医疗数据集上尤为突出。合成数据生成流程进一步增强了域内性能,使模型能够达到或超越更大的专有模型。在 Quora 与医疗数据集上,领域特定微调显著提升了性能,精确率与平均精度获得大幅改善。LangCache-Embed 在医疗数据集上领先于主流闭源模型与最先进的开源模型,特别是在使用合成数据进行微调时。该模型在嵌入生成速度与精度之间取得了有利的平衡,适用于实时语义缓存应用。
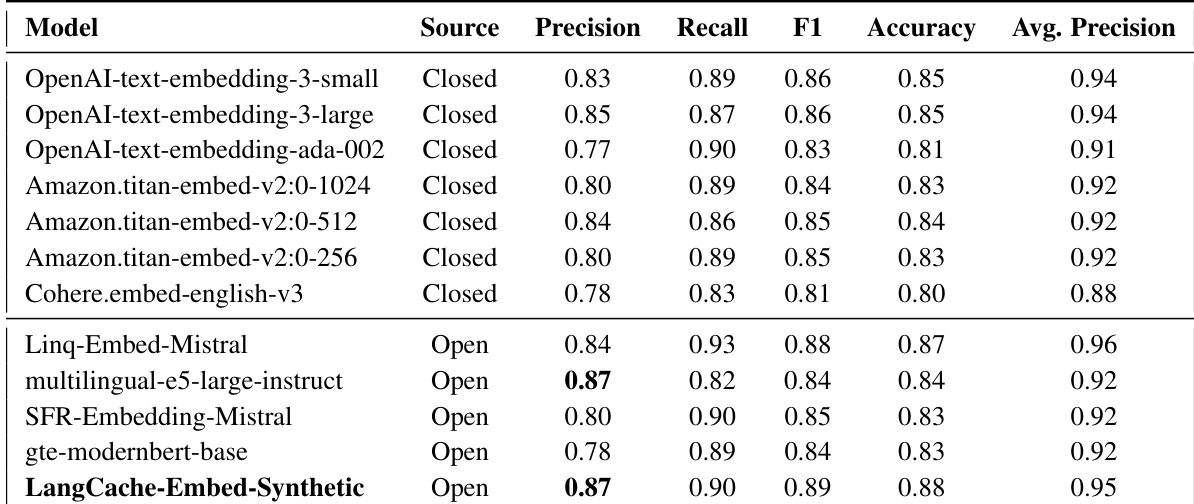
研究团队在两个数据集上评估了名为 LangCache-Embed 的 ModernBERT 微调版本,证明其在多项指标上性能显著提升。该模型取得了当前最先进的结果,性能超越开源与专有嵌入模型,并证实了领域特定微调与合成数据生成对其能力的增强作用。在 Quora 与医疗数据集上,领域特定微调显著提升了精确率、召回率、F1 分数、准确率与平均精度。LangCache-Embed 在精确率与平均精度方面领先于主流专有模型,包括 OpenAI 的最佳嵌入模型。该模型在保持高性能的同时实现了最低的嵌入生成开销,适用于实时语义缓存应用。
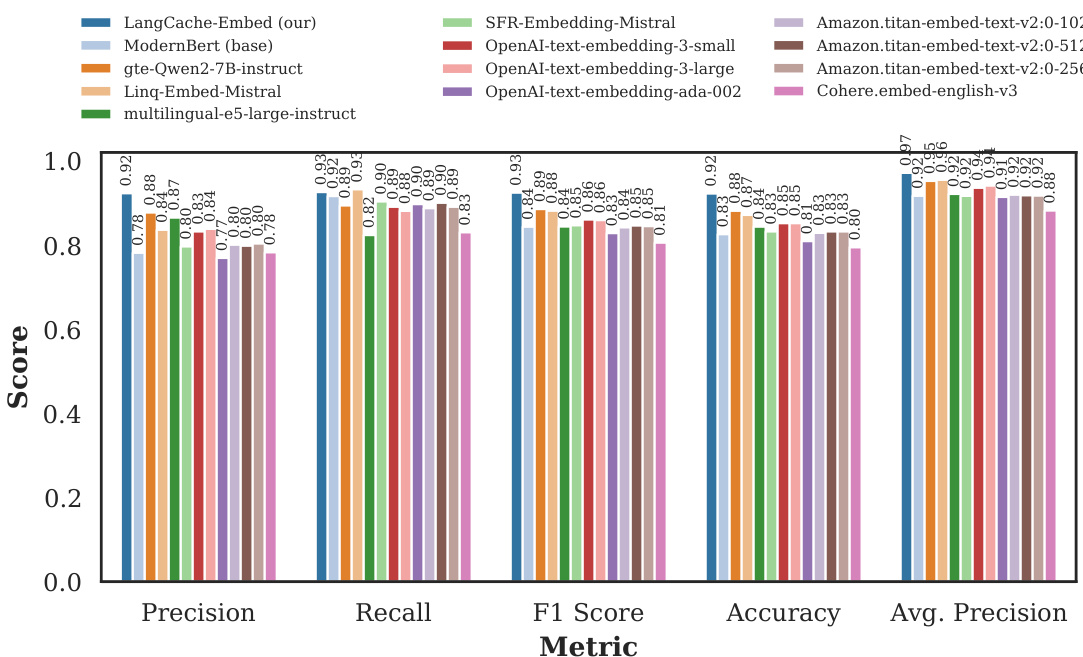
研究团队在 Quora 与医疗领域数据集上评估了 LangCache-Embed(ModernBERT 微调版本)的性能。结果表明,微调过程在多指标上显著提升了性能,且微调模型在深度与中度微调场景下均优于基础模型。微调模型实现了更高的精确率、召回率、F1 分数、准确率与平均精度,验证了领域自适应的有效性。对 ModernBERT 进行微调在 Quora 与医疗数据集上大幅提升了精确率、召回率、F1 分数、准确率与平均精度。在深度与中度微调设置中,微调模型在所有评估指标上均超越基础模型。该微调模型以较低的嵌入生成开销实现了更高性能,适用于实时语义缓存应用。
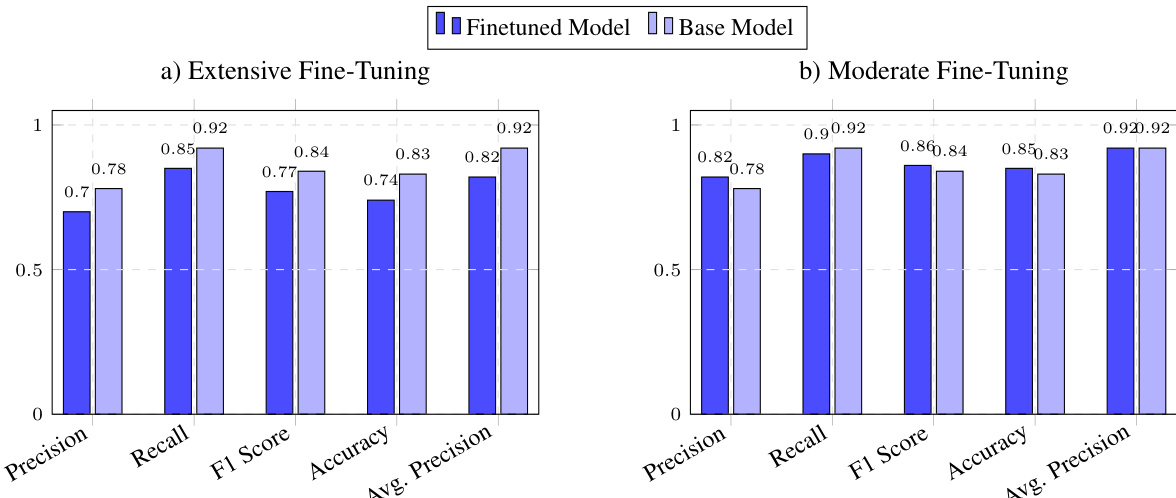
研究团队在 Quora 与医疗领域数据集上评估了 LangCache-Embed(微调版 ModernBERT),以检验其在语义相似度与缓存任务中的有效性。实验验证了相较于基础架构及现有的开源或专有替代方案,领域特定微调与合成数据增强能大幅增强模型能力。定性分析表明,该方法具备更高的精度与效率,在性能与计算开销之间取得了极为有利的平衡。最终结果证实,LangCache-Embed 为实时语义缓存应用提供了一种稳健且实用的解决方案。