Command Palette
Search for a command to run...
大语言模型中的医学推理:对DeepSeek R1的深入分析
大语言模型中的医学推理:对DeepSeek R1的深入分析
Birger Moëll Fredrik Sand Aronsson Sanian Akbar
使用 vLLM 部署 DeepSeek R1 7B
摘要
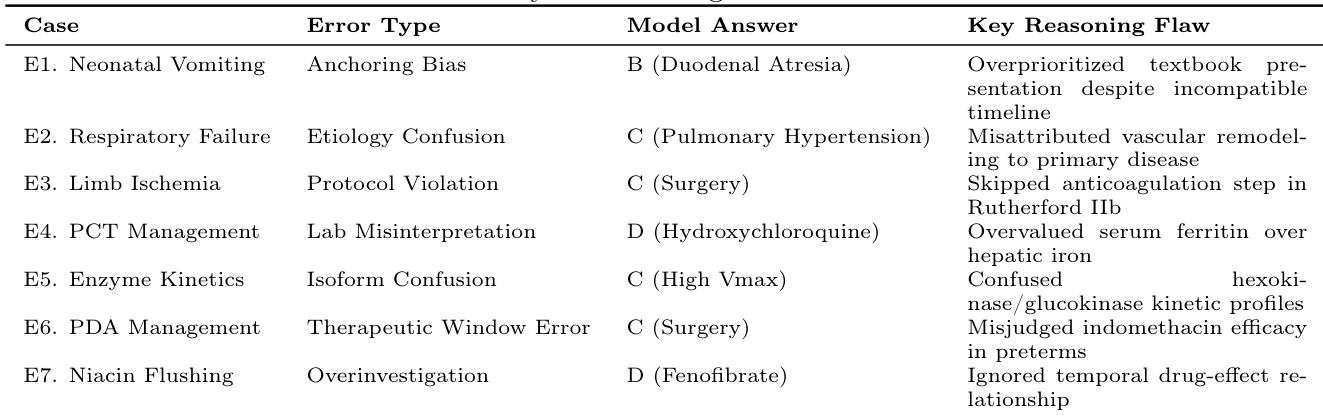
将大型语言模型(LLM)整合到医疗保健领域具有巨大潜力,但也带来了严峻挑战,尤其是其推理过程的可解释性和可靠性问题。尽管像DeepSeek R1这样包含显式推理步骤的模型在提升性能和可解释性方面展现出前景,但其与领域专家推理模式的对齐情况仍缺乏深入研究。本文评估了DeepSeek R1的医学推理能力,并将其输出结果与医学领域专家的推理模式进行比较。通过对MedQA数据集中100个多样化临床案例进行定性和定量分析,我们证明DeepSeek R1的诊断准确率达到93%,并表现出医学推理的模式。对7个错误案例的分析揭示了若干反复出现的错误:锚定偏差、整合冲突数据的困难、对替代诊断考虑不足、过度思考、知识不完整以及优先关注确定性治疗而忽视关键中间步骤。这些发现突显了医疗应用中LLM推理能力的改进空间。值得注意的是,推理长度至关重要,更长的回答往往具有更高的出错概率。
一句话总结
通过对100个MedQA临床案例进行定性与定量分析,并将其与医学专家推理模式进行对比,本研究对DeepSeek R1进行了评估。结果显示,该模型的诊断准确率达93%,同时在7个案例中识别出反复出现的错误,并证明更长的推理响应会显著增加出错概率。
核心贡献
- 本文提出了一种系统性的评估框架,将DeepSeek R1的显式推理步骤与成熟的医学领域专家模式进行对齐。
- 对MedQA数据集中100个多样化临床案例的定性与定量分析表明,该模型在展现连贯医学推理的同时,达到了93%的诊断准确率。评估进一步揭示,推理长度延长与更高的出错概率相关。
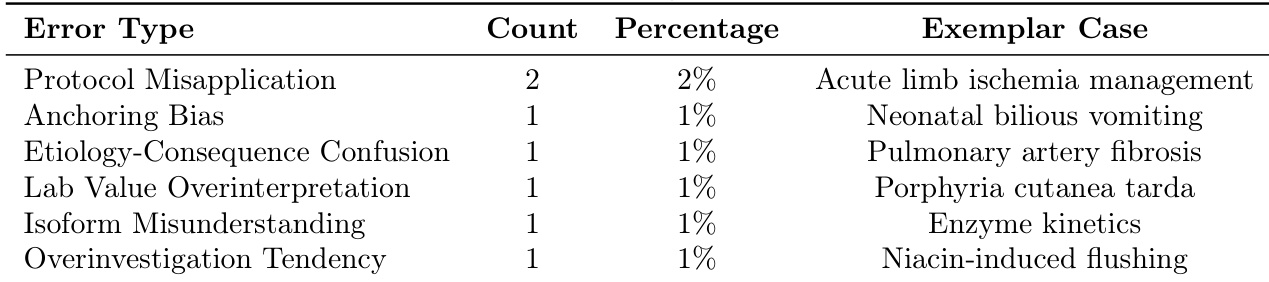
- 本研究识别出七种反复出现的临床推理失败模式,包括锚定偏差、整合冲突数据的困难,以及优先选择确定性治疗而忽略关键中间步骤的倾向。这些发现划定了当前模型推理的具体局限性,并突出了医疗大语言模型应用中需要针对性改进的领域。
引言
大型语言模型在医疗领域的加速部署旨在减少诊断错误并缓解临床人力紧张,但安全整合需要能够复现专家从业者细腻认知过程的系统。以往的模型通常作为黑盒运行,优先进行事实检索而非透明的多步推理,导致临床医生无法验证推理路径或识别危险认知偏差。作者利用开源的DeepSeek R1架构,将其显式思维链输出与成熟的临床推理框架进行比对审查。通过评估该模型如何处理双过程认知并隔离特定错误模式,他们引入了一种以保真度为核心的评估方法,将评估重心从单纯的答案准确率扩展开来,为临床对齐的AI开发奠定基础。
数据集
-
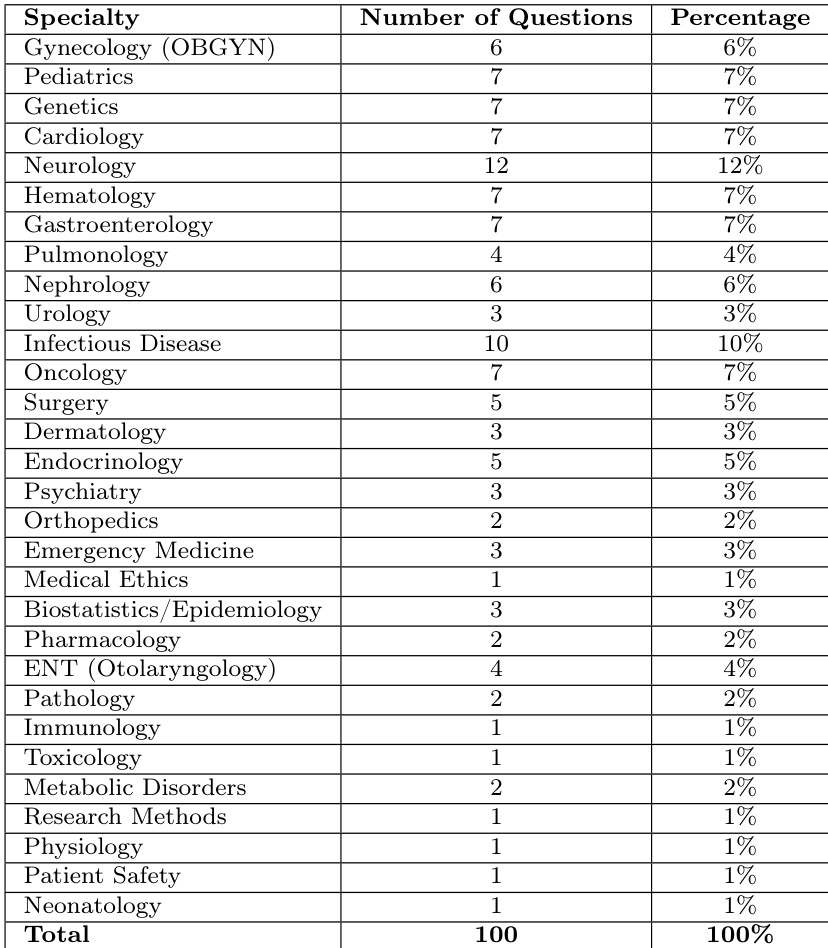
数据集构成与来源: 作者使用从MedQA基准中精选的100道题目子集来评估模型。MedQA是一个经过严格验证的题库,源自多个国家的专业医学执照考试,并按照美国医学执照考试标准进行格式化。
-
子集详情: 评估语料库包含一个由100道单项选择题组成的子集。题目经过随机抽样,以确保覆盖广泛的医学专科。每个题目均提供一段临床情景描述,用于测试诊断推理能力,涵盖患者病史解读、诊断检查选择、治疗指南应用及病理生理学整合。答案以单个字母选项的形式呈现。
-
使用与处理: 作者未将数据用于训练或混合拼接,而是仅将其作为预留的评估基准。模型使用标准化的系统提示词处理每道题目,指示其仔细分析临床情景,应用相关医学知识与逻辑推理,并仅输出所选字母。
-
评估与错误分析流程: 生成后,输出结果需经过结构化的三步分类协议。首先,将模型的最终答案与MedQA官方参考答案进行比对以验证事实对齐情况。其次,将推理链分解为具体的诊断与治疗决策节点,并映射至临床推理分类体系。最后,由临床医生审查所有已识别的错误,以对照成熟的医学推理最佳实践进行验证。
方法
作者借鉴了临床医学中常用的假设演绎模型,构建了一套结构化推理框架,以指导模型的诊断与治疗决策过程。该方法从信息收集开始,系统性地整合患者人口统计学特征、症状、生命体征及体格检查发现。随后,模型以简洁的假设驱动格式表述临床问题,例如“伴有排尿困难且无全身症状的孕妇,可能为膀胱炎”,从而聚焦于鉴别诊断。鉴别诊断清单根据临床可能性进行优先级排序,例如因缺乏肋脊角压痛等关键体征而排除肾盂肾炎。
在完成鉴别诊断优先级排序后,模型通过严格的排除与比较流程评估治疗方案。针对每种候选干预措施,模型会评估其疗效、耐药模式及安全性特征,特别是在妊娠等特定情境下。例如,在妊娠合并单纯性膀胱炎病例中,模型因耐药性排除氨苄西林,因抗菌谱过广排除头孢曲松,并因妊娠禁忌排除多西环素。经过严格的批判性评估,模型最终选择呋喃妥因作为最佳方案,因其在孕中期具有确切的疗效与安全性。
模型的推理基于基于指南的决策机制,整合临床实践标准中的证据,以确保与最佳实践保持一致。安全性、疗效与指南依从性的结合,使模型能够生成符合临床规范的建议。结构化的工作流确保了从数据整合到最终决策的每一步都逻辑连贯且透明,从而在医学推理中实现一致性与可解释性。
[[IMG:]]
实验
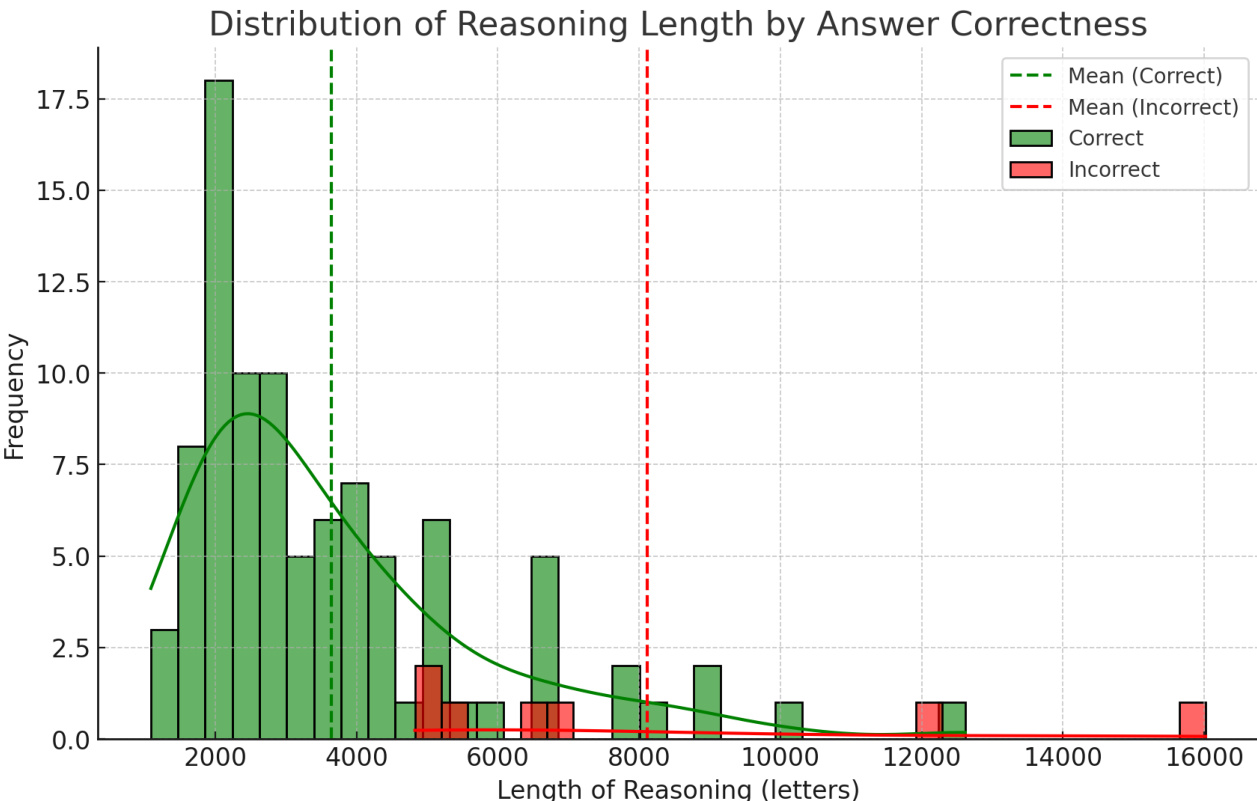
本研究在精选的临床案例集上对DeepSeek R1进行了评估,以验证其具备类专家医学推理能力及与人类专业人士的诊断对齐水平。定性分析表明,该模型始终应用结构化的临床判断并系统评估患者数据,高度契合成熟的医学思维模式。然而,错误调查揭示了反复出现的认知偏差、对推理路径理解的缺失,以及长推理轨迹与错误结论之间的强相关性。最终,研究结果证实,只要对推理长度与认知对齐进行严格监控以确保安全整合,该模型在辅助临床决策方面具有巨大潜力。
{"summary": "The authors evaluated the medical reasoning capabilities of DeepSeek R1 using 100 clinical cases from the MedQA dataset, achieving high diagnostic accuracy. The analysis revealed recurring reasoning errors such as anchoring bias, incomplete consideration of alternative diagnoses, and misattribution of symptoms, with longer reasoning responses being associated with incorrect answers.", "highlights": ["The model achieved high diagnostic accuracy with 93% on 100 clinical cases from diverse medical specialties.", "Recurring reasoning errors included anchoring bias, misattribution of symptoms, and skipping crucial diagnostic steps.", "Longer reasoning responses were significantly associated with incorrect answers, suggesting a potential indicator of unreliability."]
作者利用MedQA数据集中的100个临床案例分析了DeepSeek R1的医学推理能力,在取得高诊断准确率的同时识别出反复出现的推理错误。模型在正确案例中展现出合理的临床推理,但在错误案例中暴露出特定的认知缺陷,且推理长度与错误答案呈正相关。研究结果表明,推理长度可作为临床应用中可靠性的实用指标。该模型虽具备高诊断准确率,但在错误案例中仍表现出反复出现的认知偏差与推理缺陷。较长的推理响应与错误答案显著相关,提示其可能作为不可靠性的潜在指标。尽管模型在路径理解上存在特定错误,但其推理模式仍反映了包含鉴别诊断与治疗选择在内的临床决策过程。
{"summary": "The authors analyze the medical reasoning capabilities of DeepSeek R1, achieving high diagnostic accuracy while identifying recurring patterns of reasoning errors in a subset of cases. The analysis reveals that longer reasoning responses are associated with a higher likelihood of errors, suggesting that response length may serve as an indicator of model uncertainty.", "highlights": ["The model exhibits high diagnostic accuracy but shows recurring reasoning errors such as anchoring bias and protocol misapplication.", "Longer reasoning responses are statistically linked to incorrect answers, indicating potential uncertainty in extended explanations.", "The model's reasoning demonstrates medical logic in both correct and incorrect cases, highlighting its ability to perform structured clinical reasoning."]
作者通过分析模型对MedQA数据集中100个临床案例的诊断响应,评估了DeepSeek R1的医学推理能力。评估结果显示,尽管模型展现出较强的诊断准确率与结构化临床逻辑,但在出错时频繁表现出锚定偏差与症状归因错误等认知偏差。长推理链始终与错误答案相关联,表明冗长的解释可能反映的是底层的不确定性,而非分析的透彻性。这些定性模式表明,在将模型部署于临床决策场景时,推理长度可作为可靠性的实用指标。