Command Palette
Search for a command to run...
一键部署 Qwen2.5-Omni:看听说写全模态打通
摘要
一句话总结
Qwen2.5-Omni 是一款端到端的多模态模型,通过结合分块编码器、用于时间戳对齐的 TMRoPE、将语言建模与音频生成解耦的 Thinker-Talker 架构,以及用于低延迟解码的滑动窗口 DiT,处理文本、图像、音频和视频,以生成流式文本与语音。该模型在 Omni-Bench 上实现了最先进的性能,在 MMLU 和 GSM8K 上与 Qwen2.5-VL 持平,并在鲁棒性流式语音生成方面超越 Qwen2-Audio。
核心贡献
- Qwen2.5-Omni 引入了 Thinker-Talker 架构,将大语言模型内的文本生成与双轨自回归模型中的流式语音合成解耦,实现了端到端的联合训练,且无跨模态干扰。
- 音频与视觉编码器采用分块流式方法处理长序列,同时新型 TMRoPE 位置嵌入同步了交错的视频与音频输入。滑动窗口 DiT 进一步限制感受野,以最小化流式音频解码期间的初始包延迟。
- 在 OmniBench、AV-Odyssey Bench、MMLU 和 GSM8K 上的评估结果表明,该模型具备最先进的多模态理解能力,且语音与文本的指令遵循能力保持一致。流式语音生成器在 seed-tts-eval 上的词错误率低至 1.42%,在鲁棒性与自然度方面优于现有替代方案。
引言
提供的输入为空,因此无法生成摘要。一旦提供论文节选,将概述技术背景及其实际意义,详述现有方法的局限性,并说明作者如何利用新技术推动该领域发展。最终回复将保持简洁,兼顾技术性与可读性,并严格遵循格式规范。
数据集

- 数据集构成与来源: 作者编译了一份采用 ChatML 格式的后训练语料库,整合了纯文本对话、视觉对话、音频对话以及多模态交互数据。
- 子集详情: 该集合分为四个特定模态类别:仅文本、仅视觉、仅音频以及组合多模态对话。提供的节选未明确说明各子集的具体样本数量、外部存储库或明确的过滤规则。
- 训练用途与处理: 该指令遵循集合专用于后训练阶段,以微调 Thinker 模块。作者将所有对话轮次标准化为 ChatML 架构,以促进端到端联合训练,并确保文本、视觉与音频流之间的正确对齐。
- 其他处理细节: 提供的部分未记录任何裁剪策略、元数据构建流程或特定混合比例。预处理工作流优先保证格式一致性与模态同步,以支持实时流式生成。
方法
作者提出了 Qwen2.5-Omni,这是一款统一的端到端多模态模型,旨在感知文本、图像、音频和视频,同时以流式方式生成文本与自然语音响应。如框架图所示,整体架构围绕名为 Thinker-Talker 架构的双组件设计构建。该框架划分了模型职责:Thinker 充当大语言模型,负责处理多模态输入并生成高层表示与文本;Talker 则作为双轨自回归模型,直接从 Thinker 的隐藏表示中生成流式语音 tokens。这种分离实现了文本与语音的同步生成,且无模态干扰,两个组件均采用端到端方式进行训练与推理。
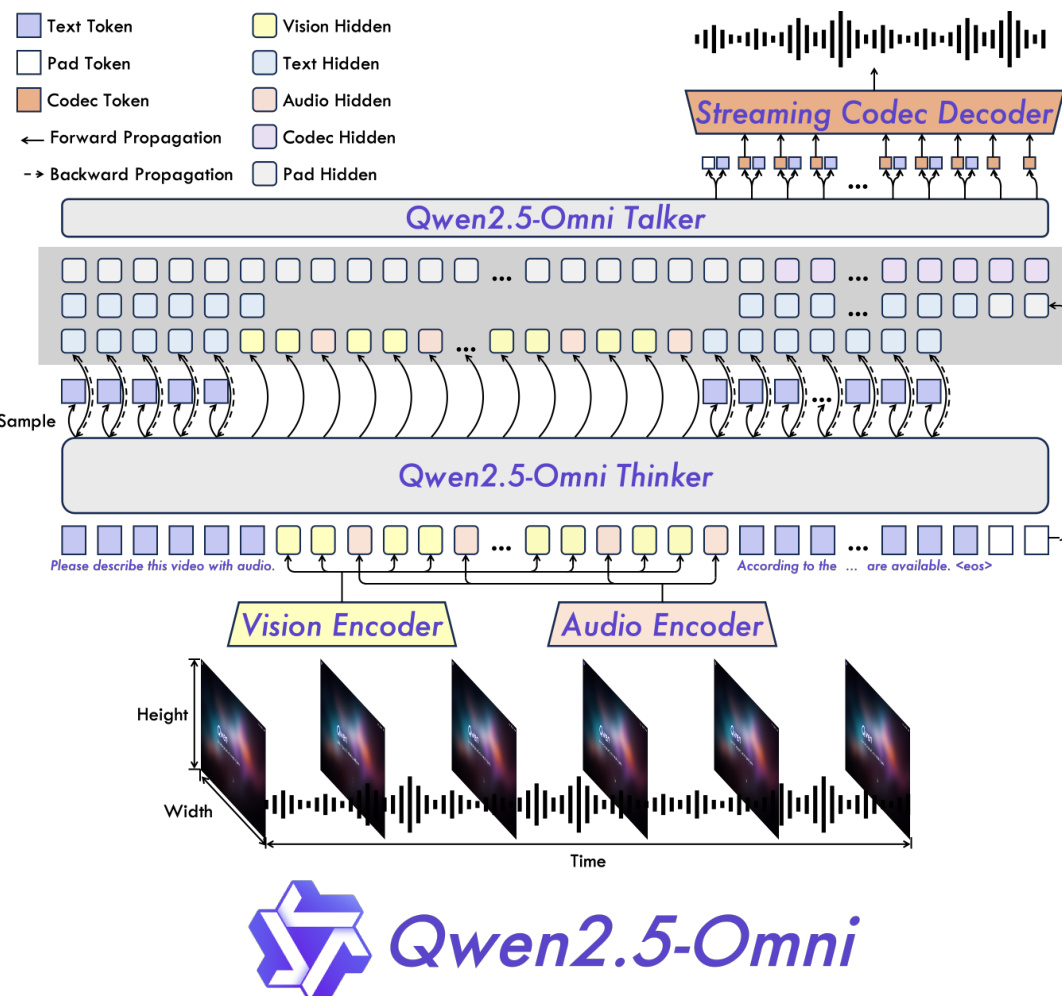
Thinker 组件是一个 Transformer 解码器,用于处理文本、音频与视觉输入。文本采用 Qwen 的字节级字节对编码进行分词,音频则转换为 16kHz 采样率下的 128 通道梅尔频谱图,每帧代表 40ms 的片段。视觉编码器源自 Qwen2.5-VL,是一种 Vision Transformer,可同时处理图像与视频。为确保音频与视频输入的同步,模型采用时间交错策略,视觉与音频表示按两秒块排列,且视觉数据位于音频数据之前。该同步由一种名为 TMRoPE(时间对齐多模态 RoPE)的新型位置嵌入方法实现,该方法显式编码多模态输入的三维位置信息。TMRoPE 将旋转嵌入分解为时间、高度和宽度分量,为每种模态分配唯一的位置 ID,同时保持序列内的一致性。对于文本和音频,使用相同的位置 ID;对于视频,时间 ID 根据实际帧时间递增,确保每个时间 ID 对应 40ms,从而维持时间对齐。
语音生成过程由 Talker 负责,该模块接收来自 Thinker 的高层表示与离散文本 tokens。这种集成使 Talker 能够在完整文本生成前预判语音的语调与态度,从而提升自然度。Talker 使用高效的语音编解码器 qwen-tts-tokenizer 表示语音信息,随后将其解码为语音流。Talker 以自回归方式生成音频 tokens,无需与文本进行词级或时间戳级对齐,从而简化了训练与推理过程。
为实现高效的流式推理,模型引入了多项架构改进。在输入处理方面,音频与视觉编码器经过修改,支持沿时间维度的分块注意力机制,使其能够以两秒为单位处理数据。这实现了分块预填充支持,降低了初始处理延迟。在音频生成方面,DiT(扩散 Transformer)模型采用了滑动窗口分块注意力机制。该机制将模型的感受野限制在有限的上下文中,具体为四个块(两个回溯块,一个前瞻块),从而实现梅尔频谱图的分块实时生成。生成的梅尔频谱图随后通过修改版的 BigVGAN 重建为波形,确保整个过程保持因果性并适用于流式传输。

Qwen2.5-Omni 的训练过程分为三个阶段。第一阶段锁定大语言模型参数,仅使用图像-文本与音频-文本对训练视觉与音频编码器。第二阶段解冻所有参数,并在更广泛的多模态数据上训练模型。最终阶段将训练序列延长至最高 32k tokens,以增强长序列理解能力。Talker 组件经历三阶段训练流程:首先学习上下文延续;其次采用 DPO(直接偏好优化)提升稳定性;最后进行多说话人指令微调,以改善自然度与可控性。这一综合训练策略使 Qwen2.5-Omni 能够在包括端到端语音指令遵循与鲁棒语音生成在内的多种多模态任务中取得优异表现。
实验
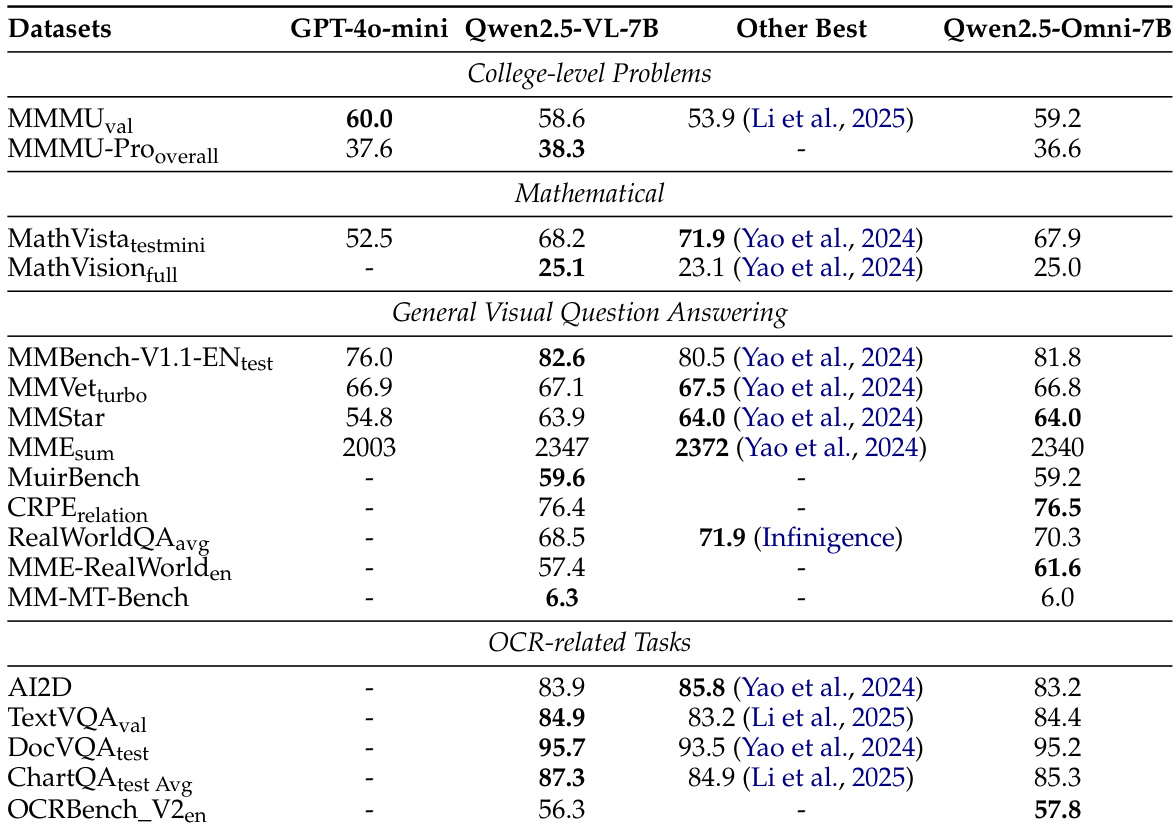
评估全面检验了 Qwen2.5-Omni 在文本、音频、图像、视频及混合模态输入上的表现,并结合其语音生成能力,利用一系列成熟基准进行测试。定性分析表明,该模型展现出最先进的跨模态理解能力,在通用推理、视觉分析与时间理解方面持续匹配或超越领先的专业架构。其音频处理与对话模块表现出卓越的流畅度与准确性,而语音生成在微调与强化学习后达到了接近人类的自然度与稳定性。综合而言,这些实验验证了 Qwen2.5-Omni 是一款高度鲁棒的全模态系统,能够无缝处理多样化输入并提供高质量的文本与语音输出。
作者从通用、数学与科学以及编程任务方面评估了 Qwen2.5-Omni 的文本到文本能力,并将其与其他 7B 参数规模的模型进行对比。结果表明,Qwen2.5-Omni 在大多数基准上取得了与现有模型相当或更优的性能,尤其在编程与数学及科学类别中表现突出,显示出强大的整体文本理解与生成能力。在大多数编程与数学及科学基准测试中,Qwen2.5-Omni 优于其他 7B 模型。该模型在通用评估任务中取得了具有竞争力的结果,排名通常介于 Qwen2-7B 与 Qwen2.5-7B 之间。Qwen2.5-Omni 在编程任务中表现强劲,在关键基准上超越了多个其他模型。
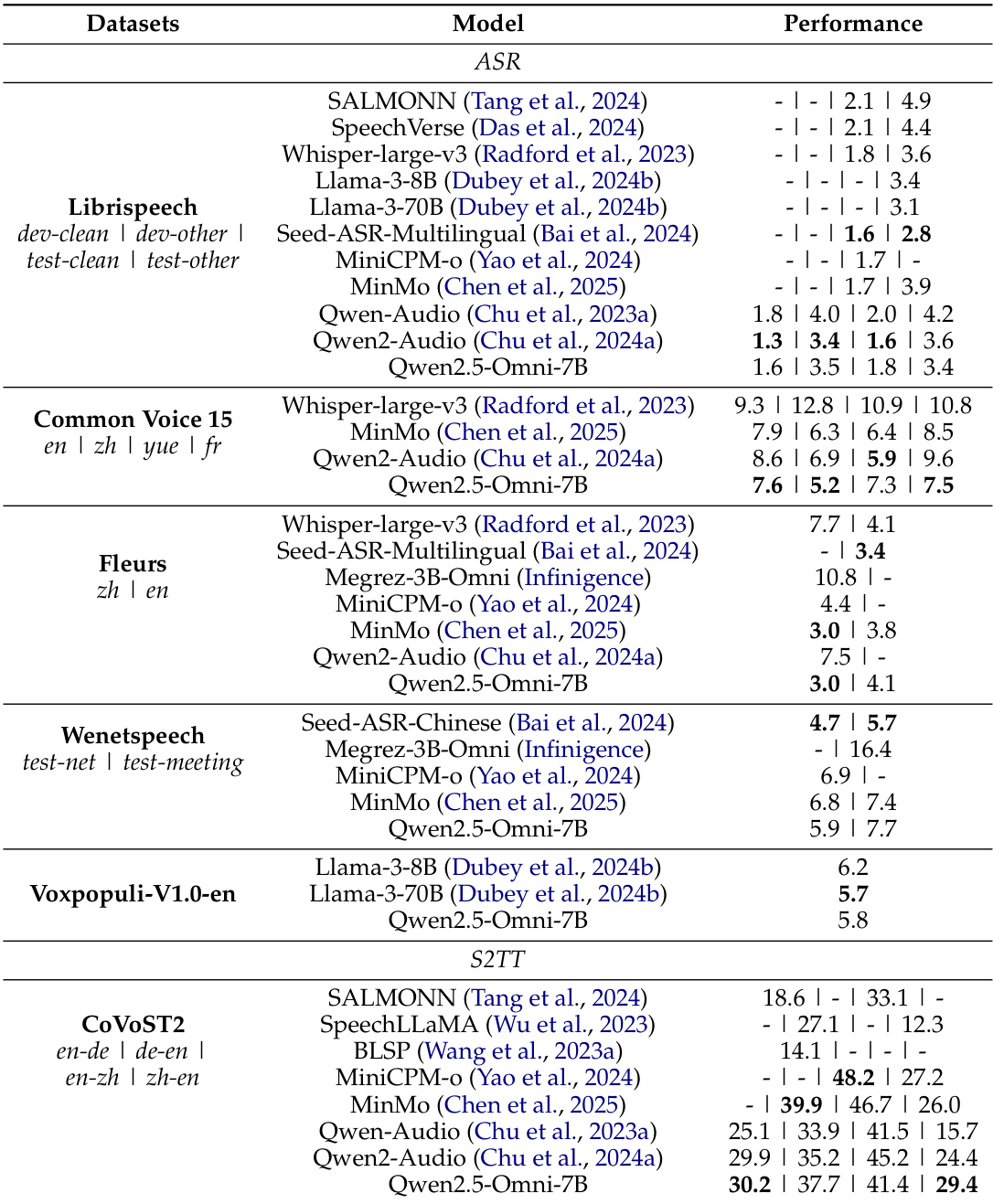
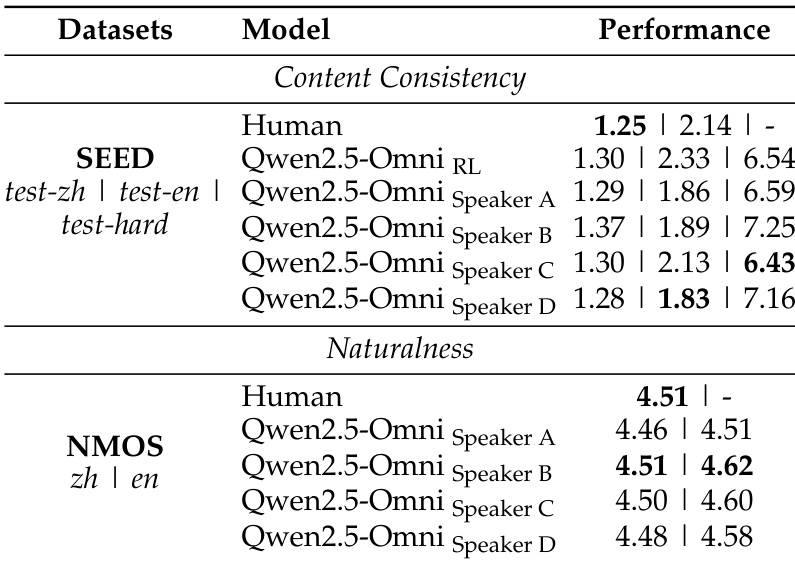
作者评估了 Qwen2.5-Omni 在音频到文本任务上的表现,并将其与多种先进模型在多个数据集上进行对比。结果表明,Qwen2.5-Omni 在自动语音识别与语音转文本翻译任务中取得了具有竞争力或更优的性能,特别是在 Librispeech 和 CoVoST2 等数据集上。该模型在零样本与单说话人语音生成方面展现出强大能力,并在强化学习与微调后获得进一步提升。与其他模型在多个数据集上的对比显示,Qwen2.5-Omni 在自动语音识别与语音转文本翻译任务中表现优异。该模型展现出强大的零样本语音生成能力,在内容一致性与说话人相似度方面结果极具竞争力。经过强化学习与说话人微调后,Qwen2.5-Omni 在单说话人语音生成任务中达到了接近人类水平的质量。
作者从多个基准测试中评估了 Qwen2.5-Omni 的视觉定位能力,并将其与 Gemini 1.5 Pro 和 Grounding DINO 进行对比。该模型在多项定位任务中表现出强劲性能,尤其在点定位与开放词汇目标检测方面,取得了与领先模型相匹敌的结果。在大多数基准测试中,其性能持续优于其他模型,凸显了稳健的视觉定位能力。Qwen2.5-Omni 在多项视觉定位基准测试(包括点定位与开放词汇目标检测)中表现优异。该模型在大多数定位任务中超越其他模型,尤其在点定位与开放词汇检测方面。在各种定位基准测试中,Qwen2.5-Omni 与 Gemini 1.5 Pro 和 Grounding DINO 等先进模型相比,展现了具有竞争力的结果。
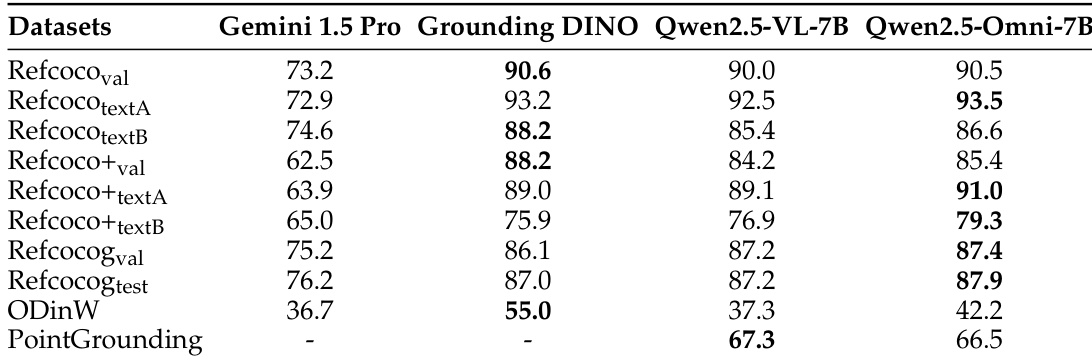
作者评估了 Qwen2.5-Omni 在多种多模态任务上的表现,重点涵盖文本、音频、图像与视频理解,以及语音生成。结果表明,与其他模型相比,Qwen2.5-Omni 取得了具有竞争力或更优的性能,尤其在图像与视频理解方面,并在多模态推理与语音生成上展现出强大能力。Qwen2.5-Omni 在图像与视频理解方面表现强劲,超越其他开源模型并与先进模型展开竞争。该模型展现出卓越的多模态推理能力,在多模态基准测试中取得最先进的结果。Qwen2.5-Omni 具备高质量的语音生成能力,在说话人微调后性能接近人类水平。
作者评估了 Qwen2.5-Omni 的语音生成能力,重点聚焦零样本与单说话人场景。结果表明,该模型在零样本语音生成中取得了具有竞争力的性能,并在强化学习后获得提升。经过说话人微调后,该模型生成的语音在客观与主观指标上均高度匹配类人自然度与韵律风格。Qwen2.5-Omni 在零样本语音生成中取得具有竞争力的性能,强化学习后效果进一步提升。该模型在零样本语音生成中展现出极强的说话人相似度与内容一致性。经过说话人微调后,Qwen2.5-Omni 实现了接近人类水平的自然度与韵律风格。
评估将 Qwen2.5-Omni 与其他 7B 参数规模模型及先进模型在涵盖文本、音频、视觉与多模态任务的标准化基准上进行对比。实验验证了其稳健的文本理解与生成能力,尤其在编程与科学推理方面表现卓越,同时具备具有竞争力的通用能力。音频与视觉评估确认了其强大的自动语音识别、翻译与定位能力,而更广泛的多模态测试则揭示了超越领先系统的推理与图像理解优势。总体而言,该模型在所有评估领域中持续交付具有竞争力或更优的结果,强化学习与说话人微调使其在单说话人语音合成中达到了人类水平质量。