Command Palette
Search for a command to run...
ESPnet-SDS:面向语音对话系统的统一工具包与演示平台
ESPnet-SDS:面向语音对话系统的统一工具包与演示平台
在线运行 Mistral-7B-v0.3 Demo
摘要
音频基础模型(FMs)的进步激发了对端到端(E2E)语音对话系统的兴趣,但不同系统拥有各自的 Web 界面使得有效比较和对比它们变得具有挑战性。受此启发,我们推出了一款开源、用户友好的工具包,旨在为各种级联式和端到端语音对话系统构建统一的 Web 界面。我们的演示平台进一步为用户提供即时自动评估指标的选择,包括:(1) 延迟,(2) 理解用户输入的能力,(3) 系统响应的连贯性、多样性和相关性,以及 (4) 系统输出的可懂度和音频质量。利用这些评估指标,我们以人机对话数据集作为代理,对各种级联式和端到端语音对话系统进行了比较。我们的分析表明,该工具使研究人员能够轻松地对不同技术进行比较和对比,并提供了有价值的见解,例如当前的端到端系统存在音频质量较差和响应多样性不足的问题。使用我们的工具包生成的示例演示已公开可用:https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
一句话总结
本文介绍了 ESPnet-SDS,这是一个开源工具包,将分散的 Web 界面整合为一个统一平台,并配备自动化评估指标,支持直接对比级联与端到端语音对话系统,同时证明当前端到端模型在音频质量和回答多样性方面表现较差。
核心贡献
- 本文推出了 ESPnet-SDS,这是一个基于模块化 Gradio 架构的开源工具包,将级联与端到端语音对话系统的 Web 界面统一化。通过整合多种语音识别、语言模型与语音合成模块,该框架支持四十余种流水线配置及全双工音频交互。
- 该工具包集成了标准化的评估流水线,可自动计算延迟、输入理解度、回答相关性、回答多样性及输出可懂度等实时指标。这一统一的评估框架无需自定义界面配置,即可在不同对话架构之间进行直接的技术对比。
- 与人类对话数据集的基准测试表明,当前端到端模型相比级联方案在音频质量和回答多样性上均有所欠缺。这些实证结果为评估下一代语音对话架构确立了具体的性能基线。
引言
语音对话系统通过传统级联流水线或新兴的全双工端到端音频基础模型,实现自然的人机交互,从而为语音助手和智能设备提供核心动力。为这些架构建立标准化的评估方法,对推动对话式人工智能发展及确保其在现实世界中的可靠部署至关重要。然而,现有实现方案依赖分散的 Web 界面、不一致的后端基础设施以及临时性的测试协议,严重阻碍了客观对比与结果复现。为弥补这些不足,本文推出了 ESPnet-SDS。这是一个开源工具包,将数十种级联与端到端对话模型整合至统一的 Gradio 界面中。通过将自动化对话指标与人工反馈收集功能直接嵌入工作流,该工具包使研究人员能够系统性地对系统性能进行基准测试,快速识别架构权衡,并加速更稳健语音对话技术的研发。
数据集
- 研究主要采用公开的 Switchboard 人机对话语料库作为基准,并辅以仅涉及同意参与的研究合作者的小规模试点研究。
- Switchboard 子集提供用于评估的标准对话数据,而试点子集包含在知情同意与明确隐私声明约束下自愿录制的交互数据。
- 该数据用于评估级联与端到端语音对话系统。评估指标在计算时实时生成,不持久化存储用户输入,且所有系统模块均已开源发布。
- 出于隐私优先原则,Web 界面的数据收集功能默认处于关闭状态。该流水线不执行显式裁剪或自定义元数据构建,而是依赖基准语料库的原始结构及用户自愿参与的试点录音,以确保评估的透明度。
方法
ESPnet-SDS 被设计为一个模块化框架,以支持级联与端到端(E2E)语音对话系统,从而实现各类组件的灵活集成与评估。该工具包的架构围绕各个独立模块的封装类构建,包括 VAD、ASR、LLM 和 TTS,这些模块均实现在 espnet2/sds 目录下,具体架构如图所示。这些封装类对现有开源模型及其推理代码库进行了封装,支持通过公开提供的检查点实现无缝集成。系统的核心是 ESPnet_SDS_Model_Interface 类,它为在级联与 E2E 配置下编排这些模块提供了统一接口。该接口支持实时交互,包括由 VAD 模块管理的话轮切换,并支持在不同系统变体之间动态切换。
该系统采用即插即用架构,允许用户从多种级联与 E2E 对话系统中进行选择,Web 界面共支持 41 种系统变体。为避免内存限制,模型采用动态加载方式,从而实现配置间的无缝切换,但加载新模型时会暂时隐藏输出框并可能引入短暂延迟。基于 Gradio 构建的 Web 界面将用户音频输入(A)流式传输,通过所选对话系统进行处理,并渲染输出结果,包括合成语音与文本回复(B)。该界面还会实时显示各组件的评估指标,例如 ASR 词错误率(WER)、LLM 延迟及 TTS 质量,使用户能够实时评估系统性能(D)。此外,框架还包含收集人工反馈的功能,用于评估系统回答的相关性与自然度(E),从而支持人在回路(human-in-the-loop)评估。
该工具包包含一个模板模块(TEMPLATE/sds1),展示了如何利用提供的接口封装类与评估工具构建完整的语音对话系统演示。该模块内含一个 Run.sh 脚本,使用户能够创建自定义配方,以对比包含不同 ASR、LLM 和 TTS 组件的模型组合。评估指标实现在 pyscripts/utils/dialog_eval 目录下,旨在同时评估子任务与整体对话层面的性能。该框架还支持可选地集成远程 HuggingFace 数据集以存储交互数据与人工评判,但为满足隐私要求,此功能默认处于关闭状态。
实验
本次评估利用 Switchboard 数据集,通过自动化基准测试与人回路试验,系统性地检验了模块化级联对话系统与端到端模型。实验验证了语音识别组件的转录准确率、语言模型的连贯性与上下文对齐能力,以及语音合成的可懂度与质量。消融研究证实了该流水线对识别误差的鲁棒性,并突出了经过语法优化的文本如何改善音频输出。定性分析表明,尽管专用模块表现优异,但端到端架构生成的回答更为套路化,且音频保真度有所下降。此外,人机交互测试显示,虽然系统通常能生成自然且符合上下文的输出,但在应对对话动态变化时存在不足,表现为延迟较高、语速较慢以及缺乏自然的交接班行为。
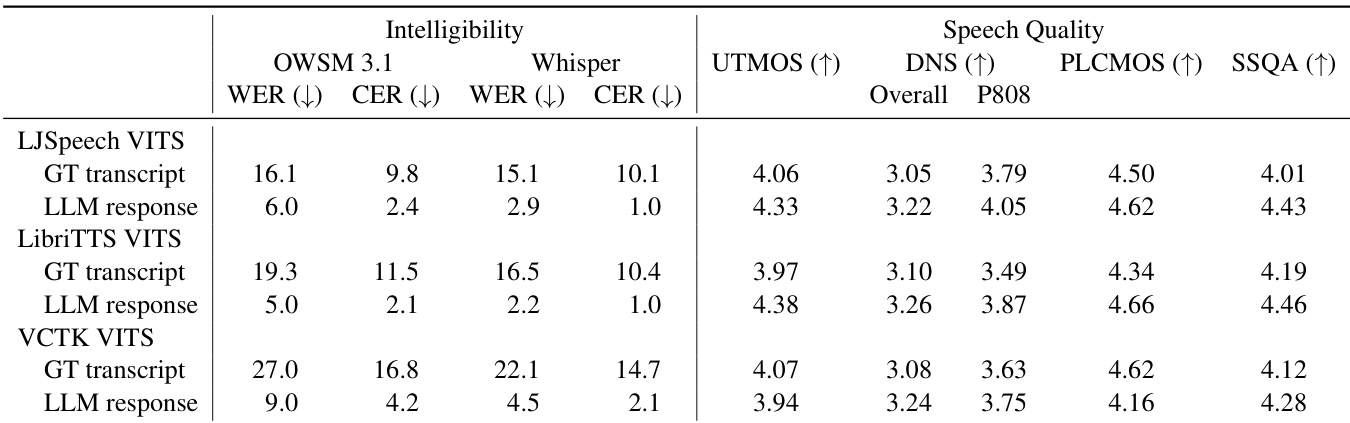
研究采用多项指标对多种语音合成模型进行评估,重点聚焦于可懂度与语音质量。表格数据显示,LJSpeech VITS 模型在可懂度与语音质量评分上均位列第一,而端到端生成回答的 Mini-Omni 系统在这两项指标上均落后于其他 TTS 模型。结果表明,Mini-Omni 系统的合成语音可懂度较低且音频质量较差。评估结果凸显了传统 TTS 模型与端到端对话系统 Mini-Omni 在语音质量方面的性能差距。
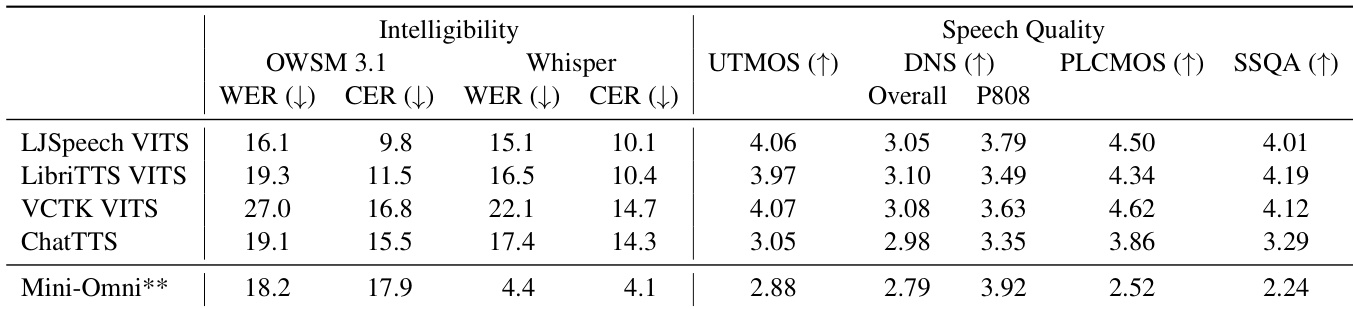
研究使用可懂度与语音质量指标,对多种 TTS 模型及 E2E 语音对话系统进行评估,对比了基于真实转录文本与 LLM 生成回答的性能差异。结果显示,LLM 生成的回答提升了各类 TTS 模型的可懂度,且 E2E 系统的合成语音在自然度上不及专用 TTS 模型。评估凸显了单说话人与多说话人模型之间的性能差异,以及使用真实输入与生成输入的系统之间的区别。与真实转录文本相比,LLM 生成的回答提高了 TTS 模型的可懂度。专用 TTS 模型产生的语音质量高于 E2E 语音对话系统。单说话人 TTS 模型在可懂度与音频质量上优于多说话人替代方案。
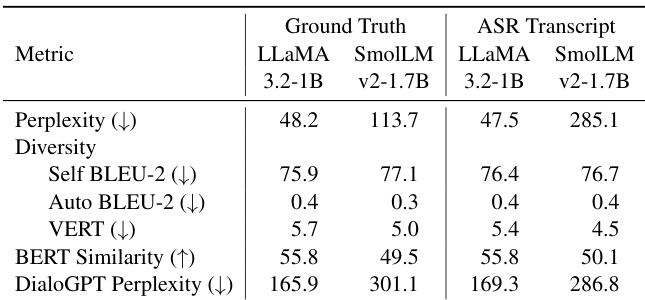
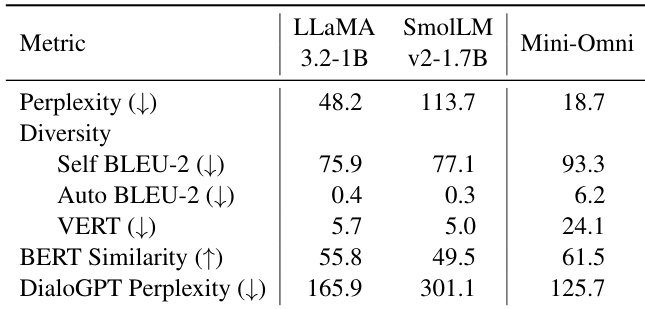
研究在级联对话系统中使用困惑度、多样性及上下文相关性等指标,对多种语言模型进行评估。结果表明,相较于 LLaMA 3.2-1B,SmolLM v2 能够生成更多样化的回答,而 LLaMA 则能产出更连贯且符合上下文的输出。评估突出了基于输入上下文的表现差异,并指出 LLM 生成的回答相较于原始语音输入,能够提升 TTS 系统的可懂度。
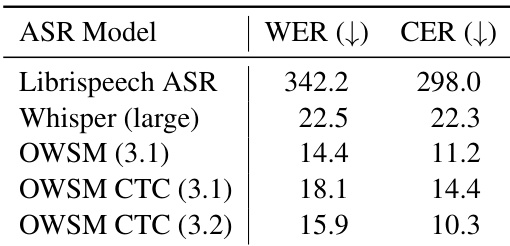
研究在 Switchboard 数据集上使用词错误率(WER)与字符错误率(CER)指标,对多种 ASR 模型进行评估并对比其误差率表现。结果显示,OWSM 3.1 模型实现了最低的误差率,OWSM CTC 3.2 模型紧随其后,而 Librispeech ASR 模型则表现出显著更高的误差率。在参评的 ASR 模型中,OWSM 3.1 性能最佳。OWSM CTC 3.2 的性能与 OWSM 3.1 非常接近,仅误差率略高。相较于 OWSM 系列模型,Librispeech ASR 的误差率大幅偏高。
研究使用文本对话模块专用指标(包括困惑度、多样性及上下文建模),对不同的语言模型与端到端对话系统进行评估。结果表明,端到端系统能够生成高度连贯且符合上下文的回答,但表现出显著的回答重叠现象,导致输出趋于模板化。在语言模型之间,某模型生成的回答多样性低于另一模型,而端到端系统在连贯性与相关性上均优于这两种模型。端到端系统相较于语言模型能生成更连贯且相关的回答。其中一种语言模型的回答多样性较低,而端到端系统则呈现高回答重叠率。端到端系统虽在连贯性与相关性上超越语言模型,但输出了模板化内容。
实验对专用语音合成与语音识别模型、大型语言模型以及端到端语音对话系统进行了评估,以验证它们在声学生成与对话推理方面的各自能力。定性分析表明,专用模块化组件在语音质量与识别准确率方面始终优于统一的端到端框架。尽管集成对话系统能够生成高度相关且具备上下文感知能力的回答,但其存在输出重复的问题;而独立运行的语言模型则在回答多样性与上下文连贯性之间呈现出明显的权衡。最终,研究结果凸显了专用架构与集成系统之间的显著性能差距,同时证实了合成文本输入能够有效提升下游语音的可懂度。