Command Palette
Search for a command to run...
PE3R:感知高效三维重建
PE3R:感知高效三维重建
Jie Hu Shizun Wang Xinchao Wang
PE3R:高效感知三维重建框架
摘要
近年来,2D到3D感知技术的进展显著提升了从二维图像理解三维场景的能力。然而,现有方法仍面临诸多关键挑战,包括场景间泛化能力有限、感知精度不足以及重建速度缓慢等问题。为解决上述局限,我们提出了一种新型框架——感知高效三维重建(Perception-Efficient 3D Reconstruction, PE3R),旨在同时提升重建的准确性与效率。PE3R采用前馈式架构,实现了快速的三维语义场重建。该框架在多种场景与物体上展现出强大的零样本泛化能力,同时显著提升了重建速度。在2D到3D开放词汇语义分割与三维重建任务上的大量实验验证了PE3R的有效性与通用性。实验结果表明,PE3R在三维语义场重建方面实现了最低9倍的加速,同时在感知精度与重建精度上均取得显著提升,为该领域设立了新的性能基准。相关代码已公开,地址为:https://github.com/hujiecpp/PE3R。
一句话摘要
作者提出PE3R,一种感知高效的前馈式3D重建框架,仅依赖2D图像而无需3D数据,通过零样本泛化实现最高9倍的加速,从而为实时和大规模应用提供快速、准确且可扩展的语义场景重建。
主要贡献
- 现有的2D到3D重建方法由于依赖场景特定训练和显式的3D数据(如相机位姿或深度图),在泛化能力、精度和速度方面表现不佳,限制了其可扩展性和实时适用性。
- PE3R引入了一种前馈架构,包含三个关键模块——像素嵌入消歧、语义场重建和全局视图感知,仅使用2D图像和语言引导即可实现零样本泛化和高效的3D语义重建。
- 在Mipnerf360、Replica、ScanNet和KITTI等数据集上的实验表明,PE3R在重建速度上至少提升9倍,同时显著提高分割精度和重建准确性,树立了该领域的全新基准。
引言
作者针对从非结构化2D图像中重建语义丰富的3D场景这一挑战,提出不依赖3D标注、相机标定或深度数据的解决方案——这些是机器人、自动驾驶和增强现实等实际应用中的常见瓶颈。以往方法虽有效,但通常依赖场景特定训练,因迭代优化(如NeRF、3DGS)导致重建速度缓慢,且在不同场景间泛化能力差。为克服这些局限,作者提出PE3R,一种前馈式框架,通过整合三个核心组件实现感知高效的3D重建:像素嵌入消歧以保证跨视角语义一致性,语义场重建将语义直接嵌入3D表示,全局视图感知实现文本引导的全景场景理解。结果是一个支持零样本泛化、自然语言查询,并相比先前方法实现最低9倍加速的系统,同时提升准确性和精度,为高效2D到3D感知树立了新标杆。
数据集
- 数据集包含三个主要组成部分:Mipnerf360(通过Qu等,2024年方法扩展为开放词汇能力)、Replica(Straub等,2019)和ScanNet++(Yeshwanth等,2023),用于2D到3D的开放词汇分割。
- Mipnerf360和Replica提供多样化的室内场景,包含3D场景重建及对应的2D图像标注,而ScanNet++用于大规模泛化评估。
- 在3D重建方面,模型在多视角深度估计数据集上进行训练和评估:KITTI(室外城市场景)、ScanNet(室内环境)、DTU(结构化室内场景)、ETH3D(混合室内外场景)以及Tanks and Temples(多样化真实场景)。
- 训练集结合了Mipnerf360、Replica和ScanNet++的数据,采用混合比例以平衡场景多样性和物体覆盖度,各子集均经过筛选以确保分辨率和标注质量一致。
- 作者采用裁剪策略在训练期间聚焦于以物体为中心的区域,尤其针对分割任务,以提升定位精度。
- 通过预训练3D重建流水线将2D图像标签与3D场景坐标对齐,构建元数据,实现跨模态语义映射。
- 模型利用预训练组件:MobileSAMv2用于轻量级2D分割,SAM2用于目标跟踪,DUSt3R用于前馈深度预测,全部集成至训练与推理流程。
- 评估指标包括分割任务的mIoU、mPA和mP,以及深度估计任务的绝对相对误差(rel)和内点率(τ = 1.03),结果按数据集报告并取所有测试集的平均值。
方法
作者提出PE3R,一种高效的前馈式2D到3D语义重建框架,通过模块化流水线设计解决语义理解与空间对齐中的关键挑战。整体框架以多视角2D图像为输入,依次经过三个核心模块:像素嵌入消歧、语义场重建和全局视图感知,生成一致的3D语义场。
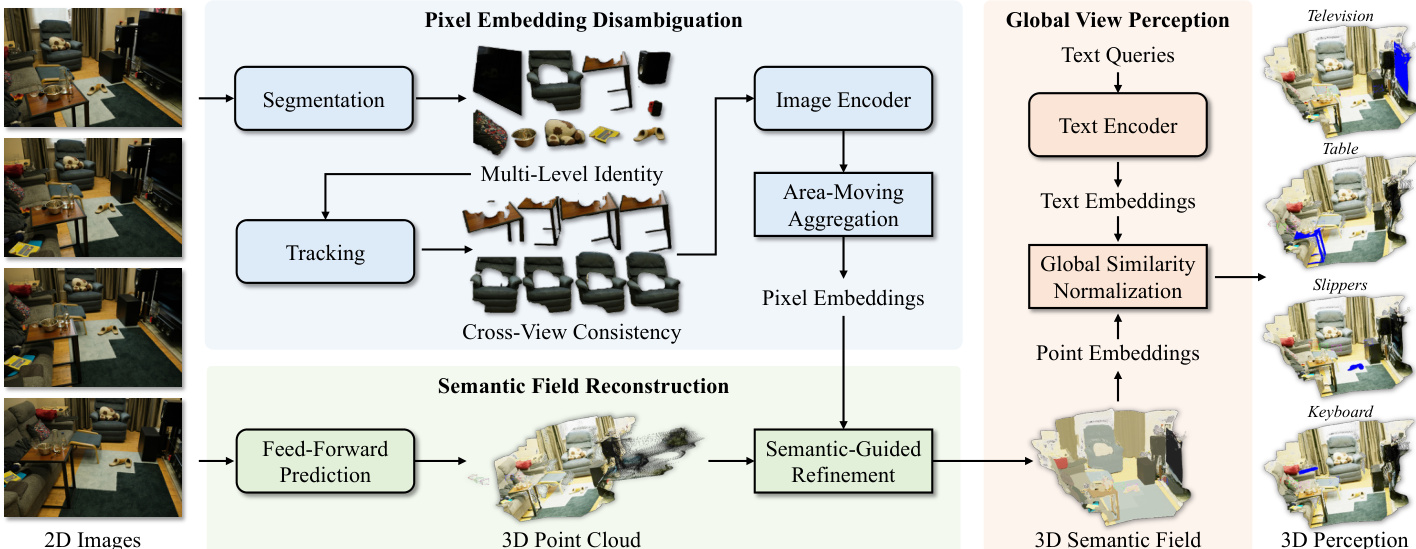
参考框架图以概览系统架构。第一模块“像素嵌入消歧”解决由物体级重叠和视角不一致引起的语义歧义。该模块首先使用基础分割模型(如SAM1和SAM2)对所有输入视角进行对象分割与跟踪,生成一致的多层级掩码。这些掩码用于通过图像编码器(如CLIP)提取图像嵌入,生成经L2归一化的嵌入。为确保跨视角一致性并消除歧义,框架采用区域移动聚合技术:该方法构建球面单位向量,融合来自不同视角的嵌入,其中插值参数由对应物体的面积比决定。该聚合过程设计为保持向量归一化,并通过数学分析证明其能有效整合语义信息。最终生成的嵌入被分配回原始图像的像素,形成既具备对象可区分性又具视角一致性的像素嵌入。
第二模块“语义场重建”利用前馈预测器(如DUST3R)估计各视角下每个像素的空间坐标,生成初始点图。然而,由于反射、遮挡等场景复杂性,这些预测常含噪声。为缓解此问题,框架引入异常检测步骤:计算每个像素与其同语义类别邻居之间的平均3D距离,距离超过预设阈值的像素被识别为异常点。随后,通过使用其语义掩码对输入图像进行平滑处理,将异常像素的RGB值替换为其对应语义区域的均值RGB,实现语义引导的精炼。该过程生成更准确的点图,再经全局对齐形成一致的3D点云。
第三模块“全局视图感知”通过处理精炼后的点嵌入与给定文本查询,实现开放词汇语义理解。文本查询通过文本编码器(如CLIP)编码为文本嵌入。计算文本嵌入与点嵌入之间的余弦相似度,结果通过最小-最大归一化进行全局归一化。随后应用相似度阈值,识别3D点云中语义匹配输入文本的点,使系统能够执行如物体定位和分割等3D感知任务。该模块化设计确保各组件协同实现高效且准确的2D到3D语义重建。
实验
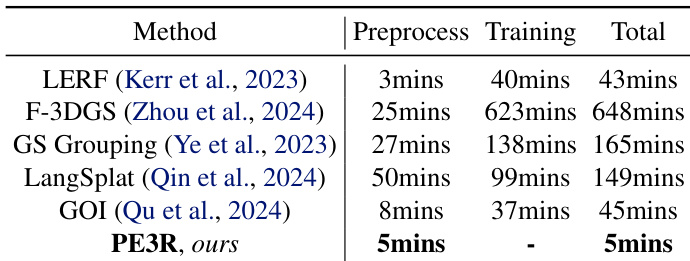
- 2D到3D开放词汇分割:PE3R在Mipnerf360和Replica上优于GOI,mIoU、mPA和mP指标均表现更优,并在语义场构建上实现9倍加速(5分钟 vs. LERF和GOI的43–45分钟)。在ScanNet++上,PE3R表现具有竞争力,展现出强泛化能力。可视化结果证实其在多样化场景和物体语义下的鲁棒性。
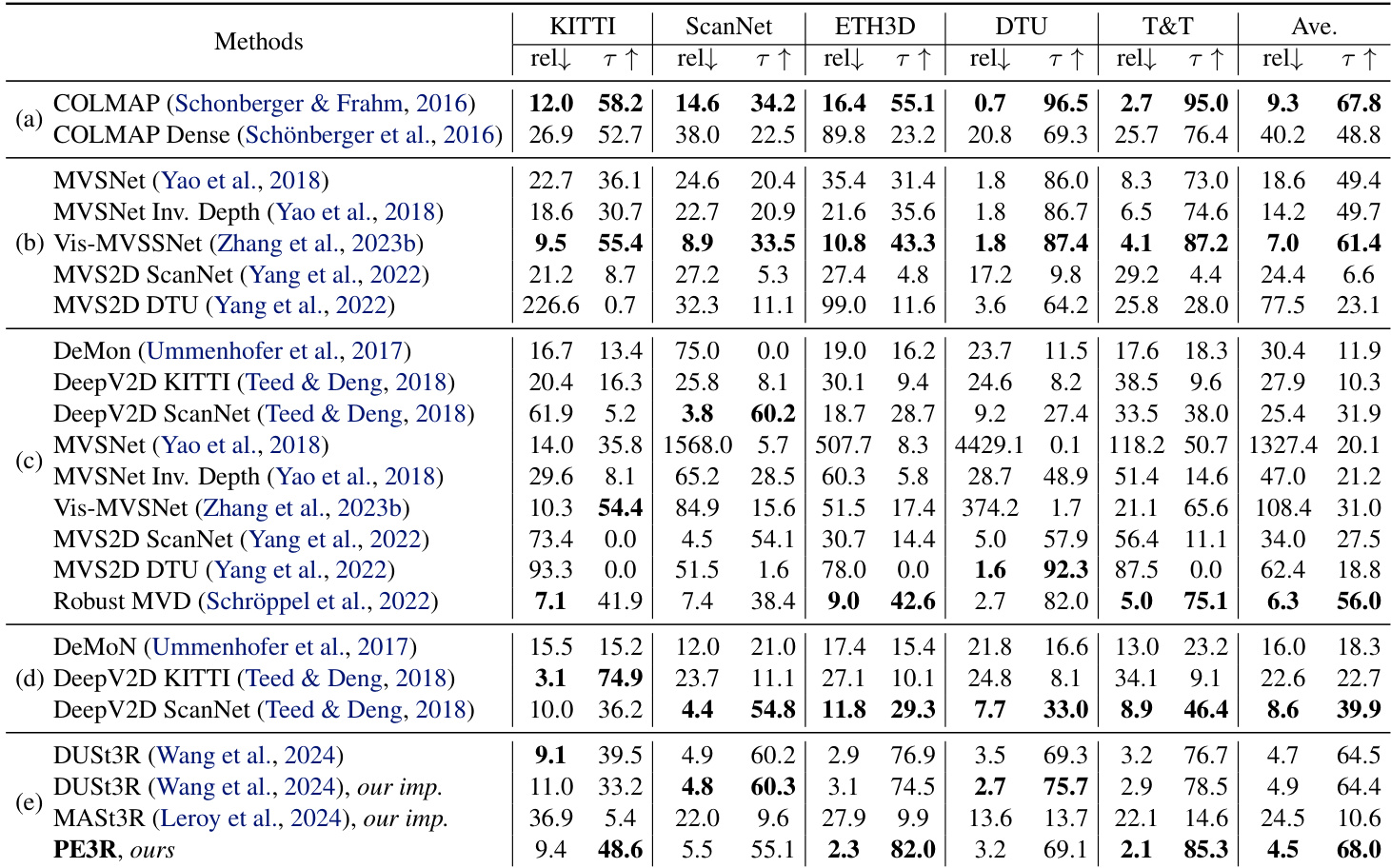
- 多视角深度估计:PE3R在多数数据集上超越DUST3R和MAS3R,达到最高平均性能,凸显其在无需3D先验条件下进行3D重建的有效性。
- 消融研究:多层级消歧保留了细粒度与复合物体语义;跨视角消歧缓解了视角与遮挡问题;全局最小-最大归一化降低噪声;语义场重建在时间开销极小的情况下显著提升复杂条件下的深度估计性能。
作者使用PE3R在Mipnerf360和Replica数据集上评估2D到3D开放词汇分割,结果表明其方法在所有指标(包括mIoU、mPA和mP)上均优于当前最先进方法。结果显示,PE3R在Mipnerf360上取得0.8951 mIoU和0.9617 mPA,在Replica上取得0.6531 mIoU和0.8377 mPA,均达到最高分。
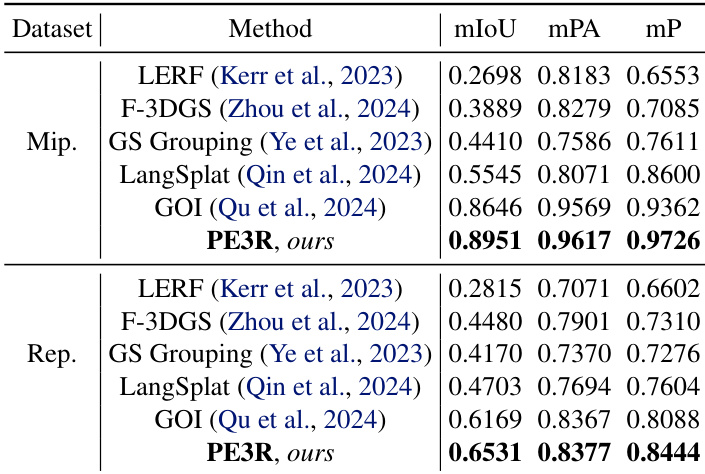
结果表明,PE3R在Mipnerf360和Replica数据集上全面超越最先进方法LERF和GOI,各项指标(mIoU、mPA、mP)均表现更优。作者通过此表证明其方法在提升分割精度的同时,显著加快了3D语义场的构建速度。

结果表明,语义场重建显著提升性能,相对误差从5.3降至4.5,τ得分从60.2提升至68.0,运行时间仅从10.4021秒略微增加至11.1934秒。作者通过该消融研究证明,引入语义场重建可增强在透明和遮挡等挑战性条件下的鲁棒性。

作者使用表2比较不同方法构建3D语义场的时间效率。结果显示,PE3R仅需5分钟完成,远快于次快方法GOI的45分钟,效率提升约9倍。
作者使用该表比较多种方法在多视角深度估计任务中的性能表现。结果显示,PE3R在多个数据集上取得最高平均性能,尤其在相对误差和绝对误差指标上优于基线方法DUST3R和MAS3R。