Command Palette
Search for a command to run...
ReaderLM-v2:面向 HTML 转 Markdown 和 JSON 的小型语言模型
ReaderLM-v2:面向 HTML 转 Markdown 和 JSON 的小型语言模型
Feng Wang Zesheng Shi Bo Wang Nan Wang Han Xiao
一键部署 Reader-LM:快速高效将 HTML 转为 MarkDown
摘要
我们提出了 ReaderLM-v2,这是一个紧凑的 15 亿参数语言模型,专为高效的网页内容提取而设计。该模型能够处理长达 512K token 的文档,以高准确率将杂乱的 HTML 转换为干净的 Markdown 或 JSON 格式,使其成为为大语言模型提供基础数据的理想工具。模型的有效性源于两项关键创新:(1) 一个三阶段数据合成管道,通过迭代起草、精炼和批评网页内容提取过程,生成高质量、多样化的训练数据;(2) 一个统一训练框架,结合了持续预训练与多目标优化。密集评估表明,在精心策划的基准测试中,ReaderLM-v2 的性能优于 GPT-4o-2024-08-06 及其他更大规模的模型 15-20%,特别是在处理超过 100K token 的文档时表现尤为出色,同时保持了显著更低的计算需求。
一句话总结
ReaderLM-v2 是一个拥有 15 亿参数的语言模型,专为为大语言模型提供 grounding 支持,能够高效地将 HTML 转换为 Markdown 或 JSON。该模型利用三阶段数据合成流水线,并结合结合持续预训练与多目标优化的统一训练框架,可处理长达 512K tokens 的内容。在精选基准测试中,其性能比 GPT-4o-2024-08-06 及更大规模的模型高出 15% 至 20%,尤其在处理超过 100K tokens 的文档时表现突出,且计算资源需求显著降低。
核心贡献
- ReaderLM-v2 是一个拥有 15 亿参数的语言模型,专为处理长达 512,000 tokens 的文档而设计,能够将非结构化 HTML 转换为干净的 Markdown 或 JSON 格式。该架构为大型语言模型在网页内容上的 grounding 提供了计算高效的解决方案。
- 该方法实现了一个三阶段数据合成流水线,通过迭代起草、优化和评估网页内容,生成高质量的训练样本。这些样本用于优化一个统一框架,该框架将持续预训练与多目标优化相结合,用于指令驱动的 Markdown 提取和基于模式的 JSON 映射。
- 基准评估表明,ReaderLM-v2 在精选基准测试中比 GPT-4o-2024-08-06 及更大模型高出 15% 至 20%,且在处理超过 100,000 tokens 的文档时具有更高的准确性。在保持显著更低计算开销的同时实现了这一性能。
引言
本文针对结构化内容提取日益增长的需求展开研究,该能力能够将杂乱的 HTML 转换为干净的 JSON 或 Markdown 格式,从而为知识检索和自动化等下游应用提供支持。以往基于 LLM 的方法在幻觉、推理瓶颈以及上下文处理能力方面存在局限,且其高昂的计算需求以及与 HTML 结构化任务的不匹配,使其难以进行大规模部署。为突破这些障碍,研究团队开发了 ReaderLM-v2。这是一个经过微调的 15 亿参数小型语言模型,在提取精度上达到或超越了更大的闭源模型。研究团队通过创新的 Draft-Refine-Critique 数据合成流水线以及将上下文窗口扩展至 512k tokens 的多阶段训练策略实现了这一目标,最终为长文档内容结构化提供了一套资源高效的开源解决方案。
数据集
-
数据集构成与来源:训练语料库由两个主要来源构建:精选的真实世界数据集与合成生成数据。基础数据集为 WebMarkdown-1M,包含从 Common Crawl URL Index 排名前 500 的域名中随机采样的 100 万网页。由于现有公开数据集未涵盖特定的 HTML 到 Markdown 转换以及基于模式的 HTML 到 JSON 映射任务,研究团队通过多步生成流水线补充了合成示例。
-
各子集关键细节:
- WebMarkdown-1M 使用 Jina Reader 转换为 Markdown 和 JSON 格式。研究团队应用语言检测功能,排除超出 Qwen2.5 支持的 29 种语言范围的文档,最终保留的语料库以英语(62.7%)和中文(20%)为主,平均长度为 56,000 tokens。
- WebData-SFT-Filtered 包含 250,000 对高质量指令对,均成功通过最终质量审查。
- WebData-SFT-Critique 包含 100,000 个训练样本,将每个输入与评估反馈及解释配对,严格保持 1:2 的负面与正面评估比例。
- WebData-DPO-Preference 包含 150,000 个偏好三元组,将每个 HTML 输入链接至已验证的预期输出与初始草稿的非预期输出。
- 评估集为独立保留的 500 份 HTML 到 Markdown 转换文档与 300 份 HTML 到 JSON 转换文档,明确排除在所有训练阶段之外。
-
论文的数据使用方式:合成子集驱动第二阶段、第三阶段和第四阶段的微调过程。研究团队通过 Draft-Refine-Critique 流水线处理所有原始 HTML,其中起草步骤生成符合格式要求的样本,优化步骤通过 LLM 审查消除冗余并强制结构一致性,评估步骤则基于提示词进行二元判断并提供解释性反馈。训练划分严格分离,评估集仅保留用于最终验证。研究团队维持特定的混合比例,例如评估数据集中 1:2 的负正平衡,以同时优化指令微调与直接偏好优化。
-
处理细节与元数据构建:研究团队通过追踪语言分布、tokens 长度统计以及二元评估结果来构建数据集元数据,从而对子集进行分类与平衡。研究团队未对文档进行截断处理,而是保留完整的平均 56,000 tokens 长度,以训练模型实现稳健的长上下文结构化提取。评估集经过严格的验证流程,包括手动将 HTML 标签映射至 Markdown 语法、确认内容完整性,以及结合自动语法检查与人工抽查来验证 JSON 结构并防止幻觉。
方法
研究团队采用了一个多阶段训练流水线,旨在迭代提升 ReaderLM-v2(一款用于网页内容提取的 15 亿参数语言模型)的性能。整体框架整合了三阶段数据合成流程与全面的训练策略,各阶段层层递进,以增强模型的准确性与鲁棒性。
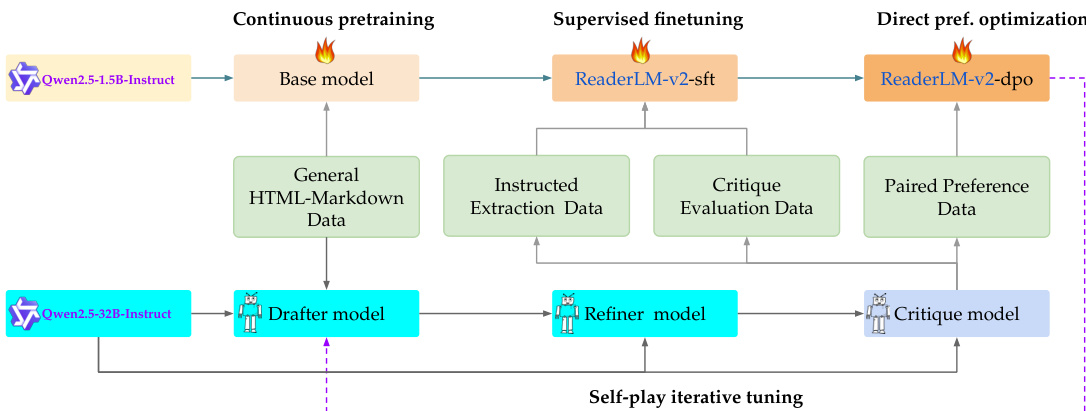
参考框架图以了解训练流程。该流水线以基础模型 Qwen2.5-1.5B-Instruct 为起点,进行持续预训练。在此初始阶段,模型在 HTML 到 Markdown 的转换数据上进行训练,以扩展其上下文长度。该阶段采用渐进式策略,通过 ring-zag attention 和 5,000,000 的 RoPE 基础频率,分三个阶段将上下文长度扩展至 32,768、125,000,最终达到 256,000 tokens。训练数据经过精心筛选,保持当前最大长度序列占比 40% 与较短序列占比 60%,确保模型能够稳定适应更长的输入。模型的泛化外推能力使其在仅接受 256,000 tokens 训练的情况下,仍可对长达 512,000 tokens 的序列进行推理。
持续预训练完成后,模型进入监督微调(SFT)阶段。该阶段利用通过 DRAFT-REFINE-CRITIQUE 流水线生成的合成数据。训练在四个专用检查点上进行,每个检查点专注于特定数据类型,即 HTML 到 Markdown 与 HTML 到 JSON 任务,使用的数据集包括 WebData-SFT-Filtered 和 WebData-SFT-Critique。为缓解 repetitive token generation 的问题,训练过程中引入了对比损失。微调结束后,研究团队通过带有权重插值的线性参数合并技术,将专用检查点整合为统一模型。
下一阶段涉及直接偏好优化(DPO),该阶段使用成对的偏好数据来精炼模型区分高质量与低质量输出的能力。此阶段沿用相同的合成数据流水线生成偏好对,使模型能够从对比反馈中学习。
最后,模型经历自博弈迭代微调,这是一个额外的训练阶段,复制了先前的 SFT 与 DPO 步骤。在此过程中,模型使用上一阶段的自身检查点生成新的草稿数据,随后经过优化与评估以生成更新后的训练数据集。这形成了一个反馈循环,模型能够自主生成改进的训练数据,并通过连续迭代不断优化自身性能。
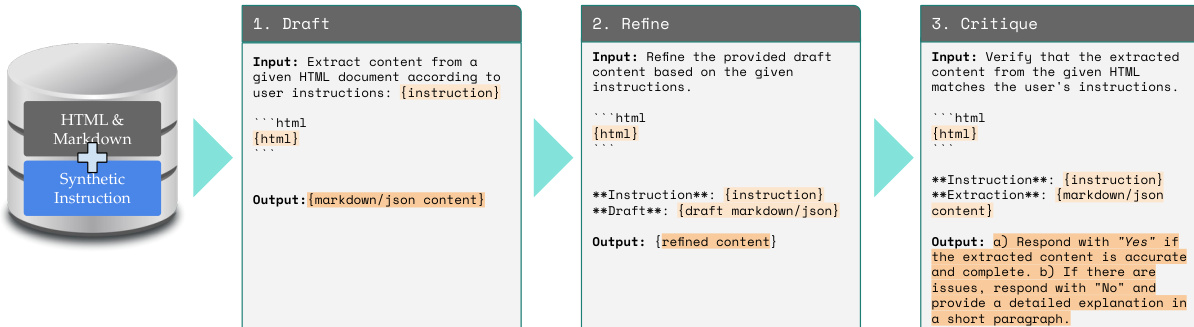
如图所示,DRAFT-REFINE-CRITIQUE 流水线在三个独立阶段中运行。第一阶段中,起草模型接收 HTML 文档与用户指令作为输入,并生成初始提取结果。第二阶段涉及优化模型,该模型接收草稿输出与原始指令,以生成内容优化版本。第三阶段采用评估模型,根据用户指令对提取内容进行评估,验证其准确性与完整性。若发现问题,评估模型将以简短段落提供详细解释。这一迭代过程确保了高质量、多样化训练数据的生成,从而提升模型在复杂提取任务上的表现。
实验
评估过程将预测结果与真实 JSON 输出转换为树状结构,以系统验证结构准确性、完整性以及对目标模式的严格遵循程度。定性分析表明,提取性能在各训练阶段保持稳定,证明初始监督微调有效内化了 JSON 格式,而偏好优化主要提升了输出可靠性。尽管模型体积紧凑,其在结构化数据提取方面仍取得了扎实的结果,不过在处理该复杂任务时,性能仍略逊于更大规模的架构。
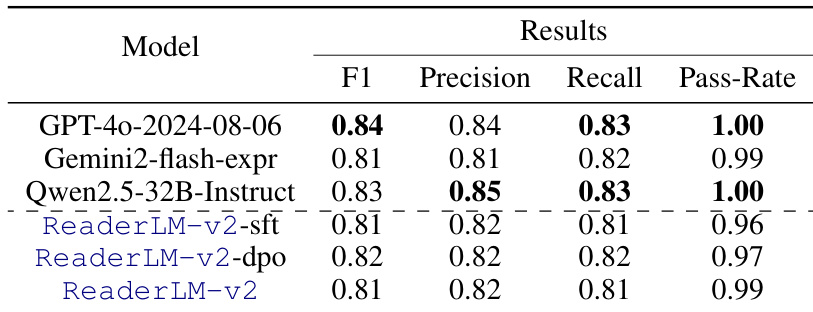
研究团队使用 F1 分数、精确率、召回率与通过率等指标评估 JSON 提取性能,并对多个模型进行了对比。结果表明,ReaderLM-v2 等小型模型取得了具有竞争力的性能,在各训练阶段结果稳定且通过率显著,尽管大型模型整体表现更优。尽管参数量较少,ReaderLM-v2 在结构化 JSON 提取方面仍表现扎实。所有模型的通过率均较高,表明输出在语法与结构遵循方面表现强劲。不同训练阶段的性能保持相对稳定,说明初始微调阶段已有效捕捉到 JSON 结构特征。
研究团队在不同任务与数据集上使用多个模型评估 JSON 提取性能,重点关注结构准确性与语法有效性。结果表明,ReaderLM-v2 表现强劲,尤其在内容提取方面,且在各训练阶段保持结果稳定,说明其有效捕捉了结构化数据模式。ReaderLM-v2 在内容提取中展现出高性能,在关键指标上优于其他模型。该模型在各训练阶段维持一致的性能,表明其对结构化数据提取的学习效果显著。ReaderLM-v2 在指令提取任务中取得优异结果,尽管数值略低于内容提取任务。
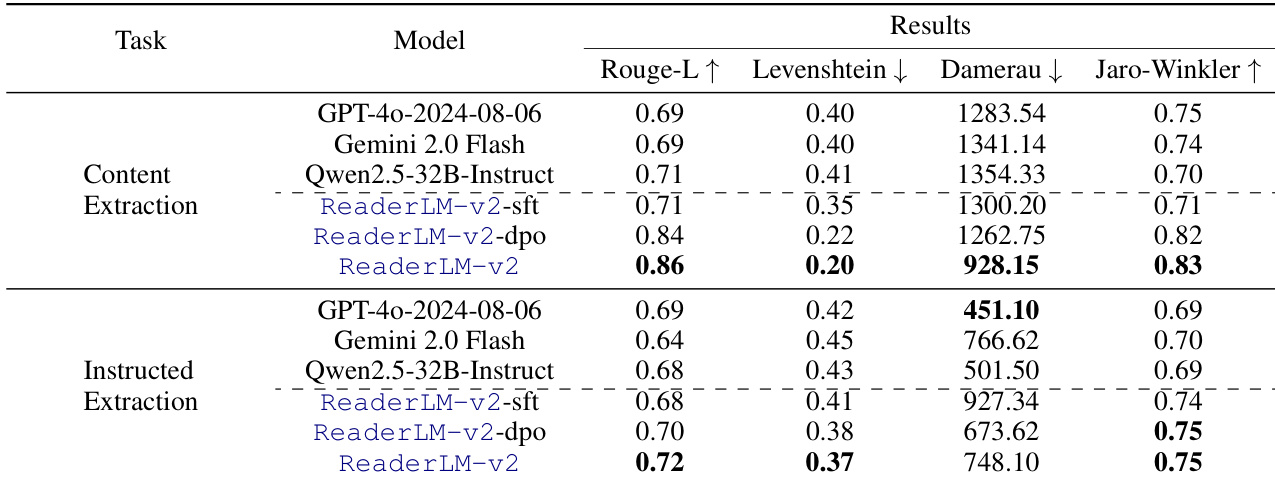
实验在多个模型与任务上评估了 JSON 提取能力,验证了结构准确性与语法遵循度。结果表明,ReaderLM-v2 等小型架构取得了极具竞争力的性能,尤其在内容提取方面,且在不同训练阶段保持结果一致。尽管大型模型整体表现更优,但小型变体在训练早期便有效捕捉了结构化数据模式,这表明高效的参数利用与定向微调足以实现稳健的提取效果。