Command Palette
Search for a command to run...
ReFreeKV:迈向无阈值KV缓存压缩
ReFreeKV:迈向无阈值KV缓存压缩
Xuanfan Ni Liyan Xu Chenyang Lyu Longyue Wang Mo Yu Lemao Liu Fandong Meng Jie Zhou Piji Li
摘要
为降低大语言模型推理时的内存消耗,已有多种KV缓存剪枝方法被提出。尽管这些技术能在许多数据集上实现无损内存压缩,但它们往往依赖于一个被低估的条件:需预先确定一个针对输入或领域的KV缓存预算阈值,才能达到最优性能。然而,这种输入敏感的设计在实际场景中可能受到很大限制,因为开放域输入涵盖多样的领域、长度和难度,缺乏明确的阈值选择边界。因此,这种对输入敏感阈值的依赖可能成为根本性局限,导致在任意输入上性能大幅下降。在本工作中,我们提出一种新目标,旨在解除阈值约束以实现鲁棒的KV压缩,倡导“无阈值”方法,使其能自适应调整预算分配,同时保持全缓存性能。我们进而提出一种新方法ReFreeKV,作为该目标的首个实例。在涵盖不同上下文长度、任务类型和模型规模的13个数据集上的广泛实验,验证了其有效性和高效性。代码已公开发布于https://github.com/Patrick-Ni/ReFreeKV。
一句话总结
由南京航空航天大学、微信AI、腾讯和复旦大学组成的团队提出了ReFreeKV,一种无阈值KV缓存压缩方法,能自适应分配预算,消除对输入敏感的阈值调优,并保持全缓存性能,在13个数据集的广泛开放域输入上实现了稳健的无损内存减少,涵盖不同上下文长度、任务类型和模型规模。
核心贡献
- 论文提出了一种无阈值的KV缓存压缩目标,能够自适应分配缓存而不依赖输入特定的预算阈值,在各类开放域输入中保持全缓存性能。
- ReFreeKV使用一种对输入域和序列长度不敏感的通用停止度量(Uni-Metric)来实现这一目标,使压缩率能根据任务复杂度自我调整,无需手动校准。
- 在涵盖推理、阅读理解和代码任务的13个数据集上,针对多种LLM规模的实验表明,ReFreeKV平均略微超过全缓存性能,在Llama3-8B上自动使用63.7%的KV预算比例,且是唯一能在不进行逐输入阈值调优的情况下,在不同数据集上保持稳健压缩的同时保留全缓存性能的方法。
引言
基于Transformer的大语言模型(LLMs)通过KV缓存进行自回归生成,该缓存存储所有先前token的中间键值状态。此缓存消耗大量GPU内存并增加推理延迟,尤其当模型规模和序列长度增长时——例如,Llama3-70B在20K token时可能需要50 GB内存。先前的研究通过剪枝或压缩次要条目来减少缓存占用空间,但几乎所有现有方法都依赖于在特定基准上调优的数据依赖预算阈值(例如,固定比例或token数量)。这类阈值无法在现实世界中具有不同域、难度和长度的混合输入中泛化,当固定预算不足或浪费时,会导致严重的性能下降。作者通过提出ReFreeKV来解决这种脆弱性,这是一种无阈值KV缓存剪枝方法,消除了对每个数据集阈值校准的需求。它根据重要性对KV位置进行排序,并应用一个对输入变化不敏感的通用停止标准,动态调整缓存预算,从而无需手动调优即可在不同任务中保持全缓存级别的性能。
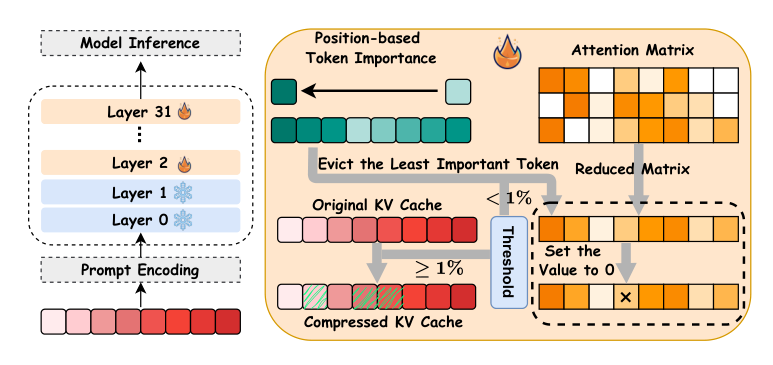
方法
作者提出了ReFreeKV,一种无阈值KV缓存压缩方法,旨在无论输入如何,都能保持与全缓存相当的一致性能,且无需输入特定的阈值调优。该方法由两个阶段组成,使用高效的并行运算符实现:初始排序阶段和基于一种称为Uni-Metric的输入不敏感阈值度量的驱逐阶段。
初始排序 第一阶段对每个层和每个注意力头的所有KV缓存位置进行排序。基于输入开头和最新位置通常起更关键作用的观察,作者根据token位置对KV缓存进行排序。对于输入序列X={x1,x2,...,xn},初始排序取前m个位置并逆序取剩余的n−m个位置,表示为X={x1,x2,...,xm,xn,xn−1,...,xm+1}。这种基于位置的排序作为归纳偏置,使后续的子集选择变得可行。
通过Uni-Metric进行驱逐 在初始排序之后,ReFreeKV顺序保留KV向量,直到满足停止条件。作者利用注意力矩阵A∈Rn×n的Frobenius范数作为Uni-Metric,记作∥A∥F=∑i=1n∑j=1n∣Ai,j∣2。对于排序序列中的每个位置i,他们比较原始注意力矩阵的Frobenius范数与一个精心选择的注意力矩阵的∥Ai∥F,其中超出i的所有位置的分数被屏蔽。当范数差达到阈值T时,确定剪枝位置iprune: iprune=argminj=1n(1−∥A∥F∥Aj∥F<T)
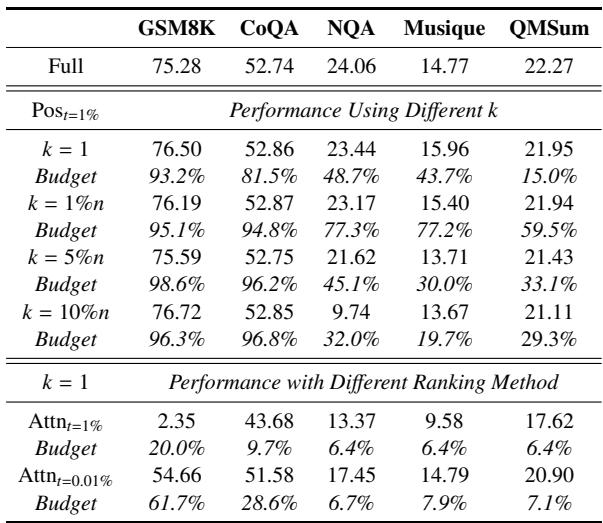
通用阈值 为了满足无阈值目标,阈值T必须确保对输入不变的近乎无损剪枝。通过实证搜索,确定T=1%是一个稳健的选择,能在最小性能退化和最大缓存驱逐之间取得平衡。如下图所示:
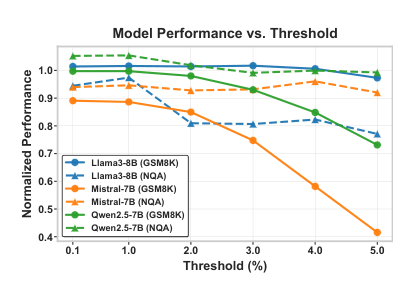
当T≤1%时,性能始终能与全缓存版本相比。
减少开销并实现 由于计算完整注意力矩阵上的范数以O(n2)增长,作者通过O(n)来近似范数计算。他们通过取A的最后k行的平均值将其缩减为单个注意力向量A′∈R1×n。位置i的分数为: A′[i]=∑j=kn1{Ai,j=0}∑j=knAi,j 这允许直接使用PyTorch的累积求和和where运算符并行确定剪枝位置,避免了显式循环。此外,与先前工作一致,作者始终保留前两层的完整KV缓存,因为早期层对语义理解至关重要。对于批量处理,较短的缓存段会进行填充,并相应更新注意力掩码。性能与效率的权衡如下图所示:
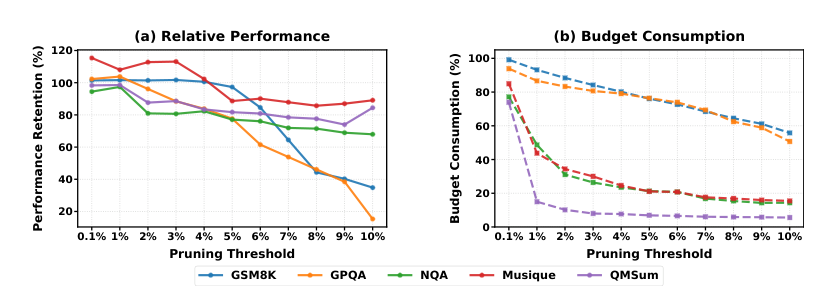
将通用阈值设置为1%能在维持稳健的全缓存性能的同时,大幅减少KV缓存预算。
实验
实验在多个LLM家族(Llama3、Mistral、Qwen2.5)以及多样的短文本和长文本推理、问答和摘要任务上评估Re-FreeKV,将其与固定预算基线(H2O、StreamingLLM、SnapKV、PyramidKV、CAKE)和自适应方法Twilight进行对比。Re-FreeKV自动调整压缩以保持近乎无损的性能,通常在使用更少内存的情况下超越全缓存分数,并避免了因较低比例下性能下降而导致固定预算方法所需的输入特定预算调优。效率分析显示极小的剪枝开销和提升的端到端生成速度,消融研究证实,依赖最后一个token的注意力、基于位置的排序以及1%的通用阈值即使在不改变超参数的情况下,也能对更大模型产生稳健的泛化能力。
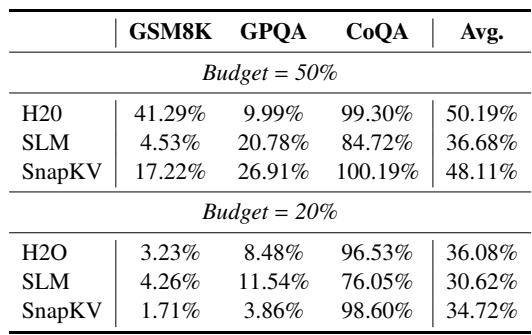
具有预设预算阈值的KV剪枝方法在不同域中表现出高度不一致的性能。像CoQA这样的任务即使在激进剪枝下也保持稳健,而GSM8K和GPQA则遭受灾难性下降,使得对于这些任务,进行逐任务预算调优以实现可接受的准确度是不可避免的。在50%预算下,SnapKV保留了几乎全部的CoQA性能,但在GSM8K上暴跌至全缓存分数的17%。当预算从50%收紧到20%时,SLM在CoQA上的相对分数从85%下降到76%。GSM8K对KV剪枝极其敏感:H2O在20%预算下仅达到全缓存性能的3%。
ReFreeKV为每个输入动态调整KV缓存的保留量,在各类任务上达到全缓存级别的性能,同时平均仅使用63.7%的缓存。相比之下,像H2O、SLM和SnapKV这样的固定预算方法需要90%的高预算且仍表现不佳。该方法的预算分配自然地反映任务难度,为数学和科学问题预留更多缓存,为摘要任务则少得多。ReFreeKV以63.68%的缓存预算平均超过全缓存性能0.12%,而H2O、SLM和SnapKV在90%预算下均导致性能下降。缓存预算自动范围从摘要数据集上的仅15%到数学和科学数据集上的超过90%,反映了问题的复杂度。
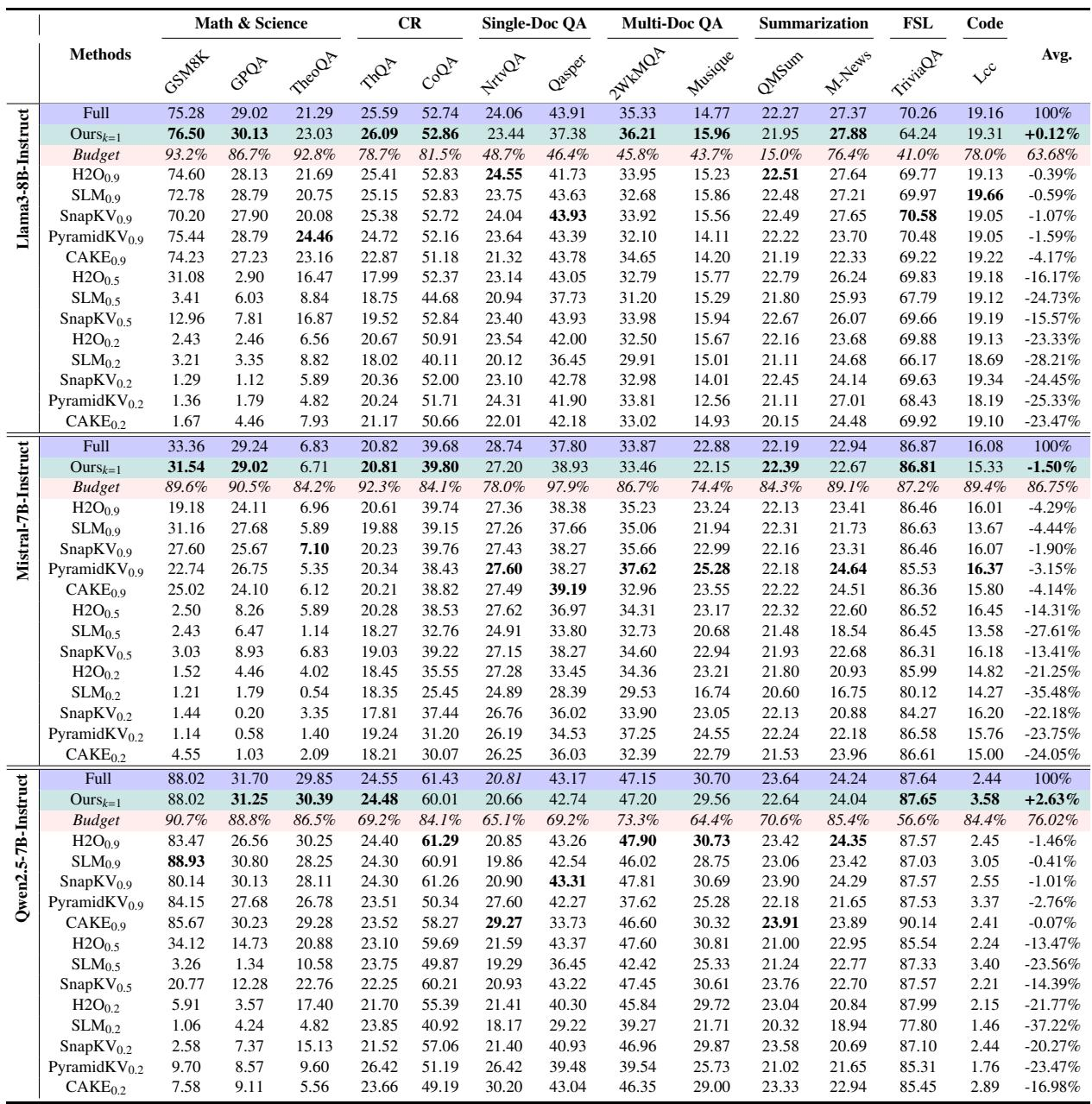
在两种模型和数据集上,ReFreeKV通常取得比Twilight更高的任务性能,经常超越全缓存基线。在Llama3-8B上,ReFreeKV在GSM8K、2WQA和Musique上优于全缓存,而Twilight在除Qasper之外的大多数任务上落后。对于Mistral-7B,ReFreeKV在Qasper上超越了未压缩模型,并在除Musique之外的所有数据集上始终击败Twilight。与Twilight相比,ReFreeKV在Llama3-8B和Mistral-7B的5个数据集中的4个上取得了除全缓存以外的最佳性能。在Llama3-8B上,ReFreeKV在GSM8K(76.50 vs 75.28)、2WQA(36.21 vs 35.33)和Musique(15.96 vs 14.77)上超过全缓存基线。在Mistral-7B上,ReFreeKV在Qasper(38.93 vs 37.80)上略微超过全缓存性能,而Twilight仅在Musique(22.92 vs 22.88)上显示出对全缓存的边际改进。Twilight仅在Llama3-8B的Qasper(43.08,对比ReFreeKV为37.38)和Mistral-7B的Musique(22.92 vs 22.15)上保持了明显优势。
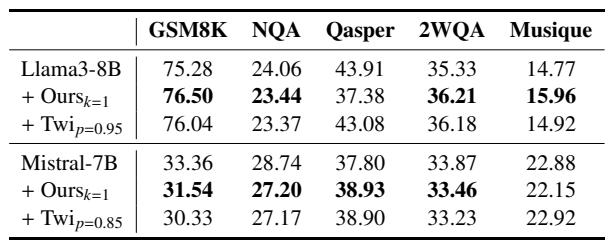
在Llama3-8B上的六个不同数据集上,与全缓存推理和50%预算下的其他token驱逐方法相比,ReFreeKV实现了最低的平均总体生成时间。其剪枝延迟与基线相当,并在大多数评估设置中取得了最佳的端到端生成速度,证实该方法减少了推理延迟而没有显著开销。ReFreeKV的平均总体生成时间比全缓存基线及所有其他剪枝方法更快。ReFreeKV的剪枝延迟极小,与H2O、SnapKV和SLM相似,因此轻量级的剪枝步骤不会抵消速度增益。在不同模型规模上,ReFreeKV在12个比较中的8个中拥有最佳的总体生成时间,在端到端延迟上始终优于先前的方法。
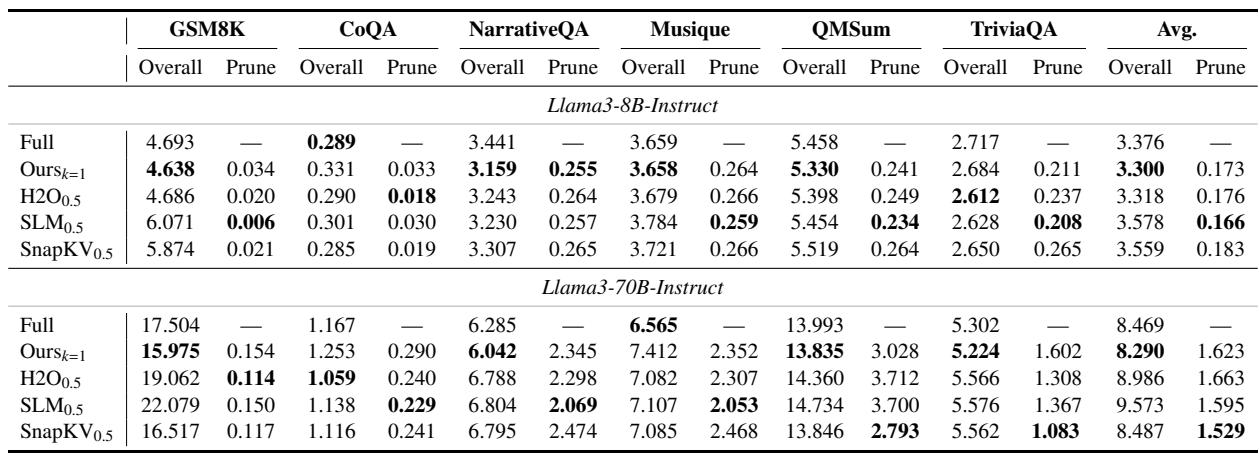
关于注意力矩阵降维的消融实验表明,仅使用最后一行(k=1)在实现与较大窗口几乎相同性能的同时,大大降低了KV缓存预算,而聚合更多行会损害准确度。用基于注意力分数的策略替换基于位置的初始排序无法产生跨任务稳健的权衡,证实了原始注意力分数对于重要性估计是不可靠的。使用k=1时,模型保持近乎完整的性能(例如,在NarrativeQA上以48.7%的预算达到23.44,在QMSum上以15.0%的预算达到21.95),同时与k=1%n或k=5%n相比大幅减少内存使用,而k=10%n导致严重下降(例如,在NarrativeQA上降至9.74)。按注意力分数进行初始排序产生了不稳定的结果;在NarrativeQA上,一个阈值仅使用32%的预算得到9.74,另一个阈值使用48.7%的预算得到21.44,两者均不如基于位置的排序在48.7%预算下达到的23.44的表现。
本研究在不同任务和模型上评估了KV缓存剪枝方法,将固定预算基线如H2O、SnapKV和SLM与提出的ReFreeKV进行比较,后者为每个输入动态调整其缓存预算。固定预算剪枝导致高度不一致的准确度,需要任务特定的调优,而ReFreeKV平均仅使用63.7%的缓存即达到与全缓存相匹配的性能,并自动为数学和科学等更难的问题预留更多内存。ReFreeKV也超越了竞争方法Twilight,经常超过未压缩基线,并在没有显著开销的情况下在不同模型规模上实现了最低的端到端生成延迟。消融研究表明,仅依赖最后一行注意力和基于位置的初始排序至关重要,因为聚合更多行或使用原始注意力分数对效率和准确度均有负面影响。