Command Palette
Search for a command to run...
Speech-FT:合并预训练与微调语音表示模型以实现跨任务泛化
Speech-FT:合并预训练与微调语音表示模型以实现跨任务泛化
Tzu-Quan Lin Wei-Ping Huang Hao Tang Hung-yi Lee
一键部署产品级方言语音生成模型 Step-Audio-TTS-3B
摘要
对语音表示模型进行微调可以提升其在特定任务上的性能,但往往会损害其跨任务泛化能力。这种退化通常是由表示的过度变化引起的,使得难以保留预训练期间学到的信息。现有的方法(如在微调过程中对权重变化进行正则化)可能无法保持与预训练模型足够高的特征相似度,从而可能丧失跨任务泛化能力。为解决这一问题,我们提出了 Speech-FT,这是一种新颖的两阶段微调框架,旨在在享受微调带来的好处的同时维持跨任务泛化能力。Speech-FT 首先应用专门设计的微调以减少表示漂移,随后与预训练模型进行权重重空间插值以恢复跨任务泛化能力。在 HuBERT、wav2vec 2.0、DeCoAR 2.0 和 WavLM Base+ 上进行的广泛实验表明,Speech-FT 在广泛的监督、无监督和 multitask 微调场景中均能一致地提升性能。此外,与显式约束权重变化的微调基线(如权重重空间正则化和 LoRA 微调)相比,Speech-FT 实现了更优的跨任务泛化能力。我们的分析揭示,尽管允许更大的权重重空间更新,Speech-FT 仍能保持比替代策略更高的与预训练模型的 feature 相似度。值得注意的是,Speech-FT 在 SUPERB 基准测试中取得了显著改进。例如,在对 HuBERT 进行自动语音识别微调时,Speech-FT 能够将音素错误率从 5.17% 降低至 3.94%,将词错误率从 6.38% 降低至 5.75%,并将说话人识别准确率从 81.86% 提升至 84.11%。Speech-FT 为在预训练后进一步精炼语音表示模型提供了一种简单而强大的解决方案。
一句话总结
Speech-FT 是一种两阶段微调框架,通过减少表征漂移并与预训练模型进行权重插值来保持跨任务泛化能力。在 SUPERB 基准测试中,该框架在 HuBERT、wav2vec 2.0、DeCoAR 2.0 和 WavLM Base+ 上持续优于权重正则化和 LoRA 基线方法,同时显著提升了自动语音识别和说话人识别的指标。
核心贡献
- Speech-FT 是一种两阶段微调框架,通过初始的漂移减少阶段及随后与预训练模型进行的权重空间插值来缓解表征漂移,从而保持跨任务泛化能力。
- 在 HuBERT、wav2vec 2.0、DeCoAR 2.0 和 WavLM Base+ 上的广泛评估表明,该方法在监督、无监督和多重任务场景中均带来一致的性能提升。SUPERB 基准测试结果显示,音素错误率从 5.17% 降至 3.94%,说话人识别准确率提升至 84.11%。
- 分析表明,尽管允许进行较大的权重更新,该框架仍能保持与预训练表征更高的特征相似度。与标准微调相比,该方法在带来性能提升的同时未引入额外的计算开销。
引言
预训练语音表征模型构成了现代语音处理的基础,能够在自动语音识别和说话人识别等多样化应用中实现稳健的性能。在特定目标上微调这些架构可显著提升任务准确率,但经常引发表征漂移,严重削弱跨任务泛化能力。现有的缓解策略(包括权重空间正则化和 LoRA 等参数高效方法)试图限制参数偏差,但往往无法保持广泛迁移所需的高特征相似度。为了解决这一权衡问题,研究提出 Speech-FT,这是一种两阶段微调框架。该框架首先应用以稳定性为核心的优化以最小化表征漂移,随后通过微调模型与预训练模型之间的权重空间插值来恢复泛化能力。该策略在策略上允许更大的参数更新,同时主动维持特征对齐,在多种语音架构和基准测试中持续带来性能提升,且未引入额外的计算开销。
数据集
- 数据集构成与来源: 研究采用 AISHELL-3 语料库(由北京贝壳科技有限公司发布标准普通话语音数据集)作为无监督微调的唯一数据源。
- 子集规格: 该数据集包含约 63.17 小时的音频,原始采样率为 44.1 kHz。研究直接使用完整数据集,未应用额外的过滤规则,也未将其划分为独立的训练集和验证集。
- 数据处理与目标生成: 为适配 HuBERT 架构,所有音频均重采样至 16 kHz。由于原始 k-means 目标模型不可用,研究通过计算 HuBERT Base 码字 logit 的 argmax 生成伪目标,从而将流程转化为自训练循环。
- 训练用法与流程细节: 研究使用有效批次大小 32 和学习率 1e-5 进行 100,000 步的持续预训练。该流程通过对掩码时间步进行交叉熵优化简化的 HuBERT 损失,无需可学习码本即可确保稳定收敛。该方法在保留英语能力的同时使模型适配普通话,无需进行音频裁剪或构建外部元数据。
方法
研究提出 Speech-FT,该框架旨在提升微调期间预训练语音表征模型的跨任务泛化能力。整体流程包含三个主要步骤:在目标任务上进行稳定微调、通过权重空间插值合并预训练模型与微调模型,以及在 SUPERB 基准上评估合并后的模型。该框架旨在缓解由微调引起的表征漂移,防止模型在下游任务上的泛化能力下降。
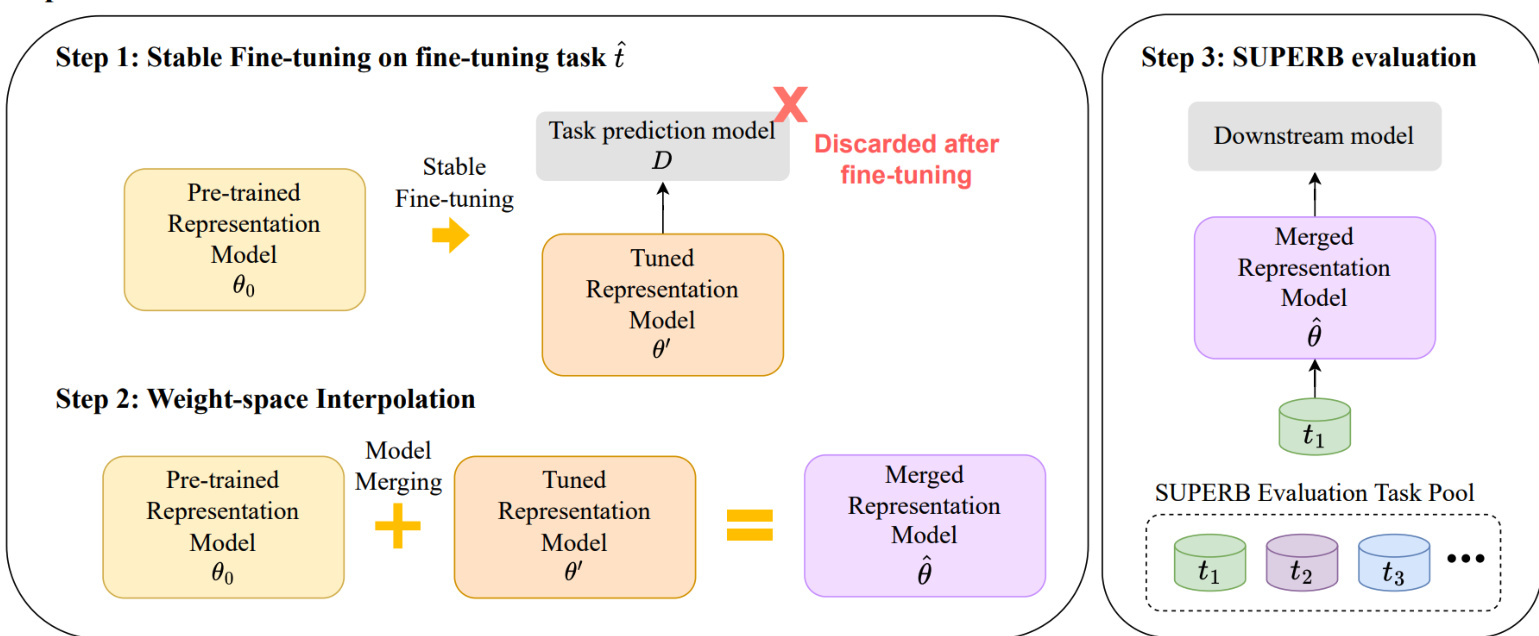
如图 1 所示,第一步涉及在特定微调任务 t^ 上进行稳定微调。该流程始于预训练表征模型 θ0,并附加任务预测模型 D。在此阶段,表征模型的下采样模块被冻结,以保留对各类应用至关重要的底层特征。微调分为两个阶段进行:最初,仅在总微调步数的前 β% 阶段更新任务预测模型 D,使模型在不立即改变表征权重的情况下进行适应。完成初始阶段后,除冻结的下采样模块外,整个模型与 D 将在剩余步数中联合更新。这种两阶段策略稳定了微调过程,并降低了灾难性遗忘或表征漂移的风险。
完成稳定微调后,第二步采用权重空间插值法合并预训练模型 θ0 与微调模型 θ′。合并模型 θ^ 计算为两组权重的线性插值,公式定义为 θ^=(1−α)⋅θ0+α⋅θ′,其中 α 为介于 0 到 1 之间的缩放因子。该合并过程在利用预训练模型强大跨任务泛化能力的同时,融入了微调模型带来的任务特定改进。与可能无法保持特征相似性的权重空间正则化不同,插值法有助于维持与原始预训练模型的表征一致性。
最后一步在 SUPERB 基准上评估合并后的表征模型 θ^。该评估涉及在合并表征上重新训练任务特定的下游模型,确保跨任务泛化性能是基于表征模型本身进行评估,而非微调过程中使用的已弃用任务预测模型 D。该评估策略为模型在多样化语音任务中的泛化能力提供了公正的衡量标准。
实验
实验在监督、无监督和多重任务微调场景中评估所提出的 Speech-FT 方法,并使用 SUPERB 基准测试来衡量跨任务泛化能力。监督评估验证了该方法在保持与预训练模型特征相似性的同时,持续提升表征质量并优于其他权重约束策略。无监督和多重任务实验证实,权重空间插值在跨语言适应期间有效缓解了表征遗忘,同时无缝整合了多样化的任务目标且未产生显著干扰。综合结果表明,所提出的插值框架为平衡特定领域学习与广泛泛化能力提供了一种稳健机制,适用于多种语音表征架构。
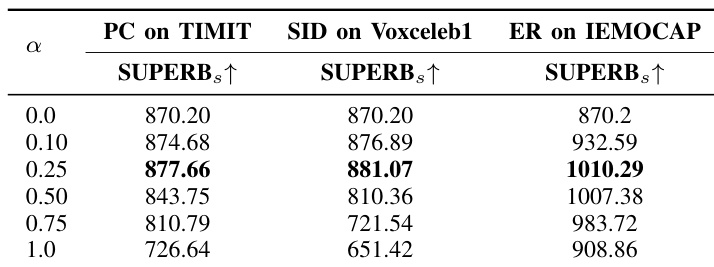
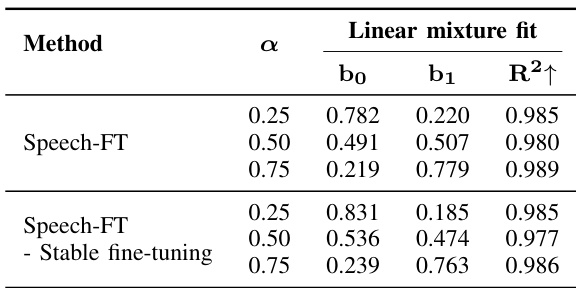
研究探讨了插值超参数 alpha 对不同微调任务模型性能的影响。结果表明,特定的 alpha 值可实现最佳整体性能,相较于全量微调和预训练模型,其跨任务泛化能力得到提升。最优 alpha 值在多项评估任务中取得最高得分,表明其在任务特定学习与通用表征能力保持之间取得了平衡。特定的 alpha 值在所有评估任务中均实现最高性能,优于预训练模型与全量微调模型。最优 alpha 值显著改善了跨任务泛化能力,这在无关任务上的优异得分中得以体现。结果证明,插值法有效平衡了任务特定学习与通用表征能力的保持。
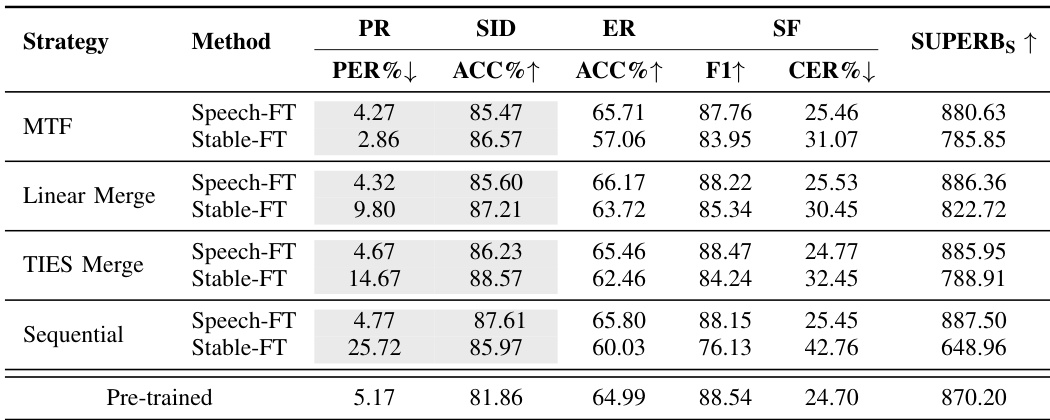
研究在音素识别、说话人识别、情感识别和槽位填充等多种语音任务上评估了包括 Speech-FT 和 Stable-FT 在内的多种微调策略。结果显示,Speech-FT 持续优于 Stable-FT 并取得更高的 SUPERB 得分,表明其更好地保持了跨任务泛化能力。Speech-FT 的有效性在多重任务设置中尤为明显,其在多样化任务中均保持强劲性能。在所有评估任务中,Speech-FT 的 SUPERB 得分均持续高于 Stable-FT。Speech-FT 在多重任务微调场景中维持了更优的跨任务泛化能力。在相关与不相关任务上,Speech-FT 均优于 Stable-FT,从而提升了整体表征质量。
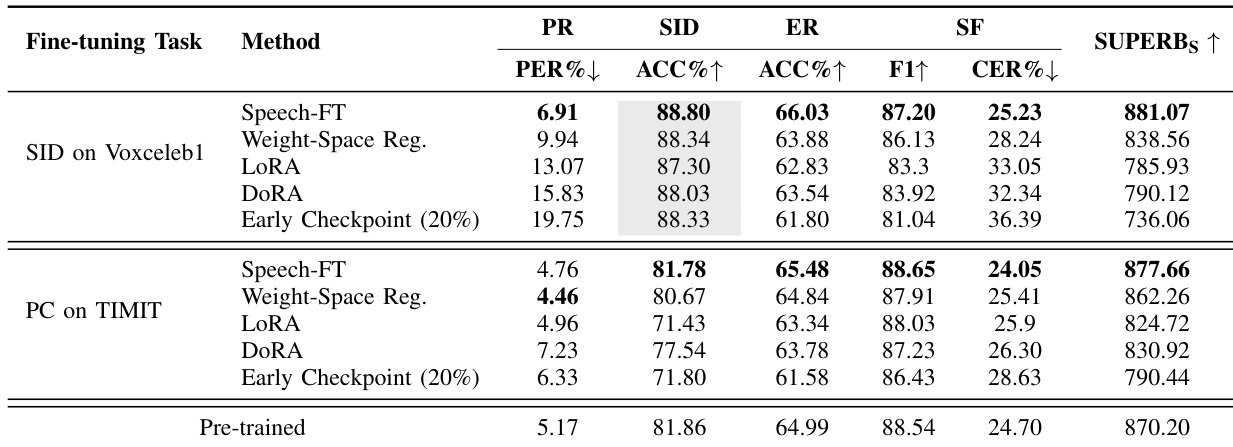
研究在不同微调任务和方法上评估了 Speech-FT 的有效性,并将其与权重空间正则化、LoRA 及早期检查点等多种基线方法进行比较。结果表明,Speech-FT 在保持跨任务泛化能力方面持续优于这些替代方案,尤其是在与微调目标无关的任务上,更高的 SUPERB 得分及与预训练模型更高的特征相似度证实了这一点。该方法在不同任务中展现出稳健的性能,在说话人识别和情感识别方面取得显著改善,同时在相关任务上保持强劲表现。与权重空间正则化和 LoRA 等基线相比,Speech-FT 取得了更高的 SUPERB 得分,特别是在与微调目标无关的任务上。相较于其他替代方案,Speech-FT 保持了与预训练模型更好的特征相似度,从而促进了跨任务泛化能力的提升。Speech-FT 在说话人识别和情感识别方面展现出持续改善,同时保留了相关任务上的性能。
研究在不同语言的无监督微调场景中评估了 Speech-FT 的有效性,并将其与 Stable-FT 及预训练模型进行比较。结果表明,Speech-FT 在保持英语下游任务强劲性能的同时,提升了对新语言的适应能力,而 Stable-FT 则导致跨语言泛化能力显著下降。与导致严重性能退化的 Stable-FT 不同,Speech-FT 在适配新语言的同时保留了英语任务性能。在跨语言和单语言设置中,Speech-FT 在英语任务上的 SUPERB 得分均高于 Stable-FT。Stable-FT 显著降低了跨语言泛化能力,这体现在中文和西班牙语语音识别任务中较低的 SUPERB 得分和上升的错误率上。
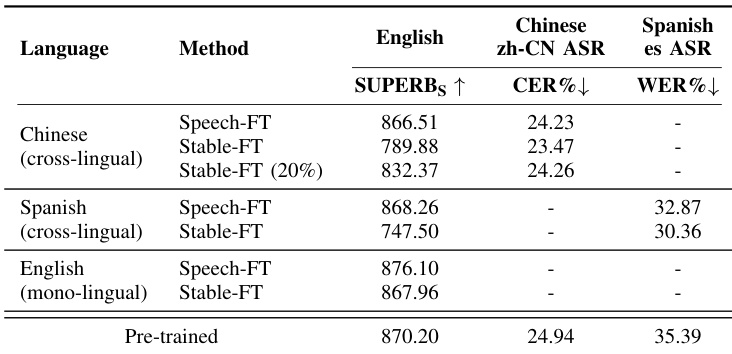
下表展示了评估 Speech-FT 方法中不同插值参数影响的实验结果。该表比较了不同缩放因子 α 值下 Speech-FT 的性能与采用稳定微调的基线方法。结果表明,在不同 α 设置下,Speech-FT 均能持续保持与预训练模型的高特征相似度,R² 值对此予以证实。Speech-FT 在测试的 α 值范围内性能稳定,其中 0.25 设置显示出略高的相似度,表明其具备持续保持特征表征的能力。Speech-FT 在不同插值参数下均能保持与预训练模型的高特征相似度。该方法在缩放因子 α 变化时表现出稳定的性能,证明了其鲁棒性。在保持特征相似度和维持跨任务泛化能力方面,Speech-FT 优于稳定微调基线。
实验在多样化的语音任务和语言中,将 Speech-FT 与 Stable-FT 及既定基线方法进行对比,并在不同插值参数下系统测试该方法,以验证其平衡任务特定适应与表征保持的能力。这些评估表明,Speech-FT 在有效适配新目标的同时保持与预训练模型的高特征相似度,从而持续优于替代方案。研究结果凸显了该方法稳健的跨任务与跨语言泛化能力,证明其成功防止了多重任务和無监督场景中的性能退化。总体而言,该研究确立了 Speech-FT 作为一种稳定的微调方法,能够在不牺牲任务特定学习的前提下可靠地保留通用能力。