Command Palette
Search for a command to run...
高级循环神经网络:双向 RNNs
摘要
一句话总结
本研究将迁移学习与长短期记忆循环神经网络应用于澳门五个监测站超过十二年的每日气象与污染物数据,构建了一个预测框架。该框架在预测未来空气污染物浓度的同时,能够弥补特定空气质量监测站的数据匮乏问题。
核心贡献
- 开发了一种基于长短期记忆(LSTM)循环神经网络的框架,通过整合历史污染物测量数据与气象变量,预测澳门未来的空气污染物浓度。
- 采用迁移学习与预训练神经网络架构,以缓解空气质量监测站的数据匮乏问题,确保在观测记录有限的情况下模型训练依然稳健。
- 利用五个监测站超过十二年的每日测量数据验证了该方法,建立了一套基于计算智能的区域空气质量预测系统。
引言
准确预测空气污染物浓度对公共卫生规划至关重要,但许多监测站的历史记录稀疏或不完整。传统的机器学习方法通常需要大量连续的数据集才能有效训练,这在数据匮乏的环境中部署时,会严重限制预测精度并增加计算开销。为解决这一问题,作者将迁移学习与长短期记忆(Long Short-Term Memory)循环神经网络相结合。他们在数据丰富的邻近监测站对模型进行预训练,并将学习到的权重迁移至数据有限的目标站点,证明该策略相比随机初始化的网络能够实现更高的预测精度与更快的收敛速度。
数据集

-
数据集构成与来源: 作者使用了源自澳门自动气象站(AWS)与多个空气质量监测站(AQMS)的每日时间序列数据集。这些记录通过向澳门气象局(SMG)提交正式申请获取,时间跨度为2001年10月1日至2014年7月1日,共计4,656天。每个时间戳包含41个特征,涵盖气象读数、观测污染物浓度及预测污染物数值。
-
子集详情与站点覆盖: 数据集聚焦于五种目标污染物:PM2.5、PM10、NO2、NO 和 CO。PM2.5 的观测数据在所有监测站点均可获取,而路环高密度住宅区的记录相对稀疏。作者提供了覆盖所有站点的 PM2.5 预训练神经网络,以及针对路边、住宅和背景(路环)站点的 PM10 模型。
-
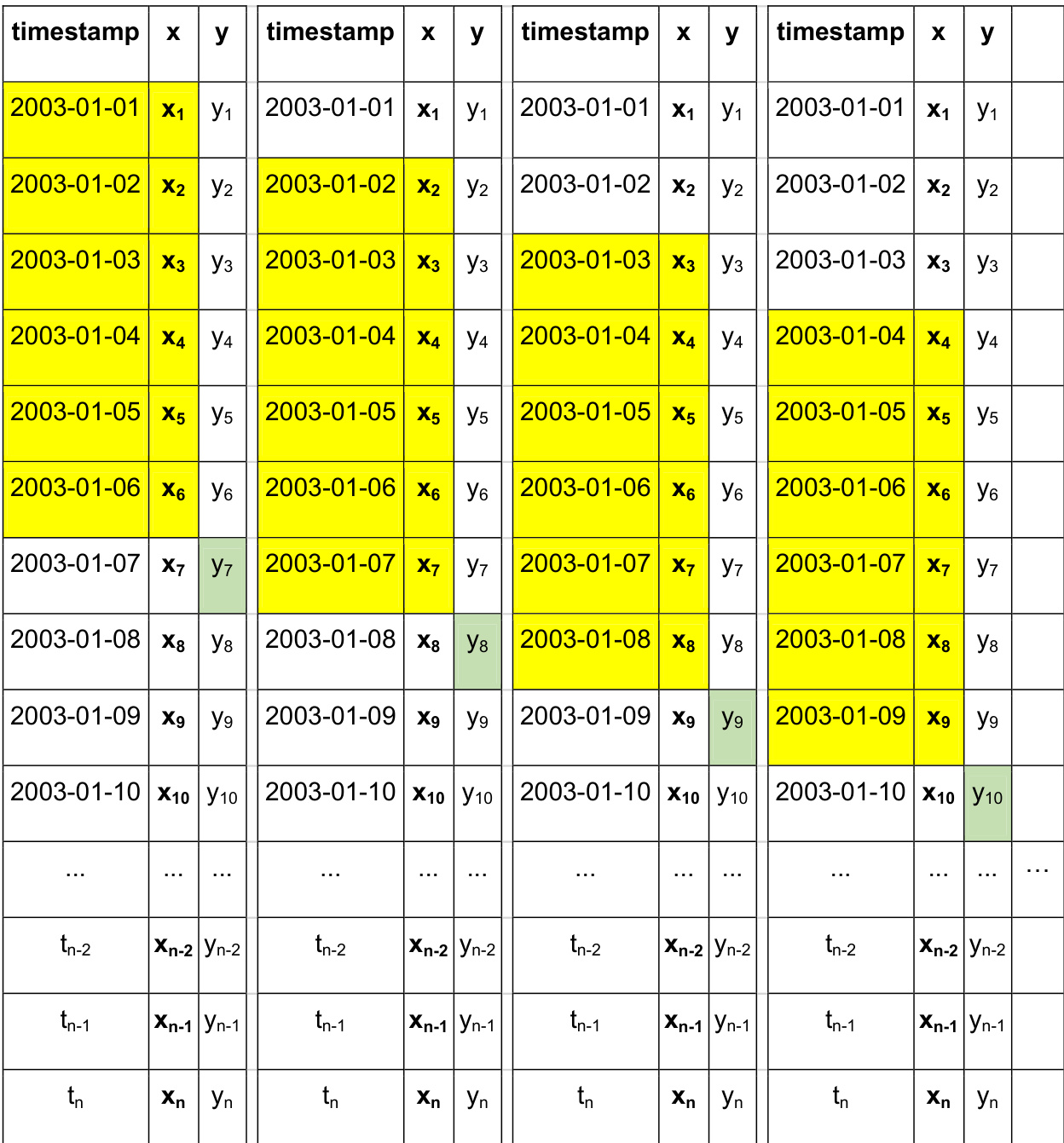
序列构建与处理: 为准备监督学习数据,作者采用固定的六天滑动窗口。每个样本利用过去六天的观测值来预测下一天的浓度值,结构表示为 (x1,x2,x3,x4,x5,x6,y7)。所有特征值在输入网络前均经过 min-max 归一化处理,严格映射至 [0, 1] 区间。
-
训练划分与模型应用: 时间线按时间顺序划分为训练集(占71%,覆盖九年)、验证集(占25%,覆盖三年)和测试集(占5%,覆盖0.75年)。每种空气污染物均分配专用的 RNN 或 LSTM 架构。作者从随机初始化开始训练这些模型,并与提供的预训练网络进行对比,以评估不同站点和污染物类型下标准训练与迁移学习的差异。
方法
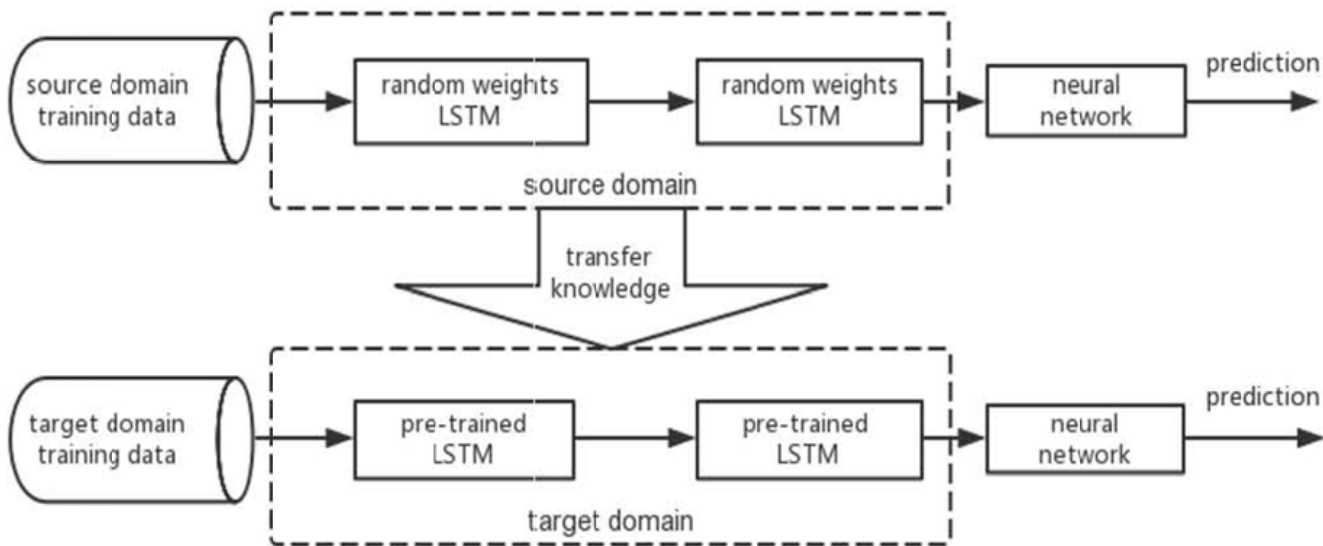
作者利用长短期记忆循环神经网络(LSTM RNN)将空气污染物(APS)浓度建模为时间序列预测问题。该框架旨在解决特定空气质量监测站(AQMS)观测数据有限、从而阻碍有效模型训练的场景。为克服此限制,所提出的方法引入了迁移学习,实现将知识从数据丰富的源域迁移至观测稀疏的目标域。整体架构包含两个主要阶段:源域训练与目标域适配。
在源域中,构建了一个权重随机初始化的标准 LSTM 网络。该网络使用澳门自动气象站与空气质量监测站的历史观测数据进行训练,目标是预测特定 AQMS 中某种空气污染物的浓度。训练过程涉及向模型输入时间序列数据,每个输入序列对应过去观测值的一个窗口,如图下所示。模型学习将这些序列映射至未来的污染物浓度。

训练完成后,生成的 LSTM 成为预训练网络,代表从源域学到的知识。该预训练模型作为目标域任务的初始化基础。目标域涉及在另一个 AQMS 预测空气污染物浓度,该站点可能与源域不同且观测数据较少。在此阶段,构建一个新的 LSTM 网络,并使用预训练模型的权重作为初始状态。随后利用目标域训练数据对网络进行微调,使其在利用源域所学通用模式的同时适应新任务。
LSTM 网络的架构经过设计,以有效处理序列数据。该模型包含多个 LSTM 层,第一层接收包含观测时间序列特征的数据。输入数据按时间步序列排列,如框架图所示,模型处理从时间 t-B 到 t-1 的数据以预测时间 t 的浓度。下图进一步详细展示了该架构及数据在层间的流动过程。
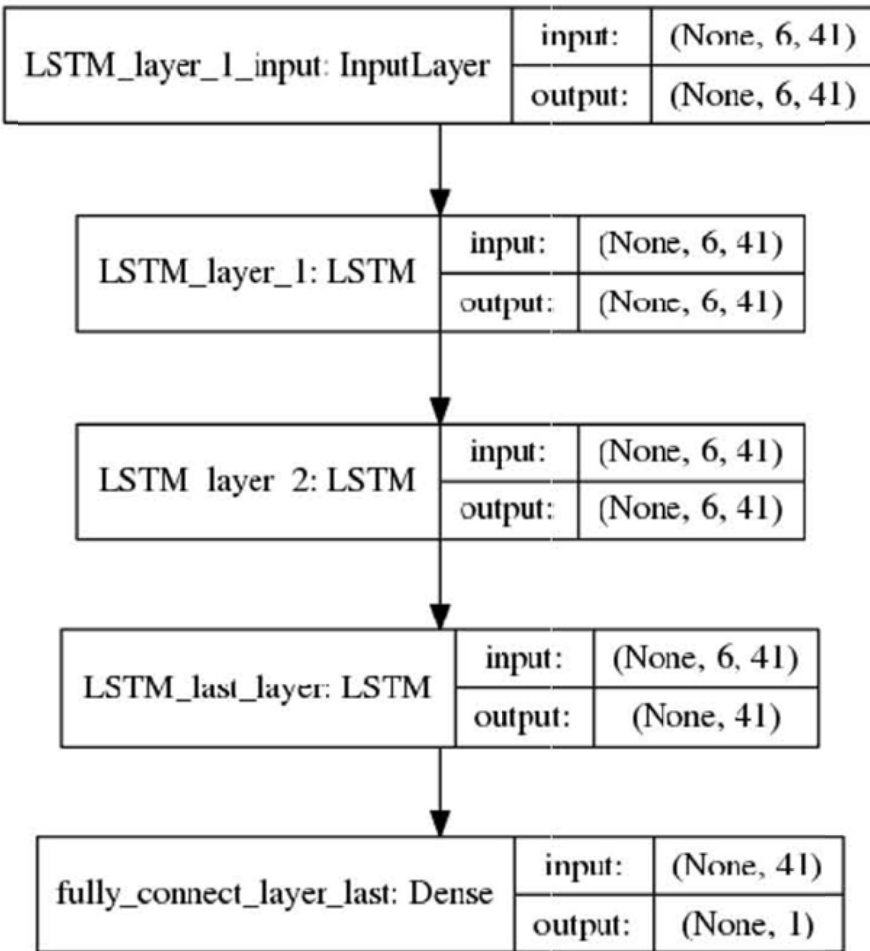
该网络由输入层、两个 LSTM 层及一个最终的全连接层组成。输入层处理时间序列数据,随后数据传入 LSTM 层以捕捉时间依赖性。最终的全连接层生成预测输出。下图展示了网络的具体配置,包括各层的输入与输出维度。输入维度为 (None, 6, 41),表示网络处理长度为 6 的序列,每个时间步包含 41 个特征。最终层的输出维度为 (None, 1),对应预测的浓度值。
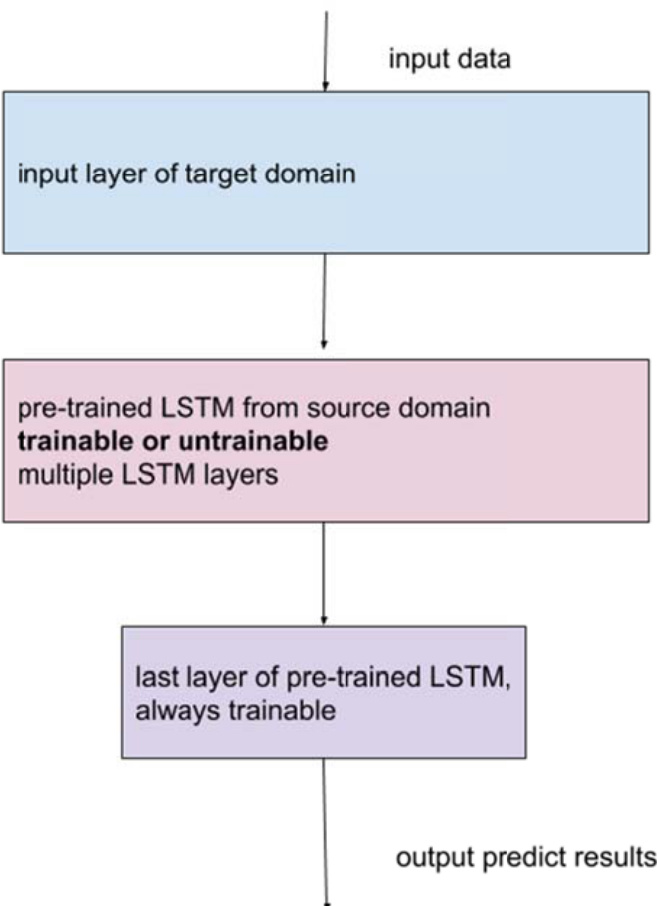
在迁移学习过程中,预训练的 LSTM 权重被迁移至目标域,模型利用目标域数据进行微调。下图展示了预训练模型适配目标域的过程。目标域的输入数据被送入预训练的 LSTM 层,这些层根据具体的迁移学习策略可设置为可训练或固定。预训练 LSTM 的最后一层始终可训练,使模型能够调整其最终输出层以适应新任务。该方法使模型获得更优的初始状态,从而加快收敛速度并提高预测精度,尤其在训练数据有限的场景中效果显著。
实验
实验通过利用邻近监测站的相关空气质量数据,评估迁移学习方法与随机初始化的神经网络及 LSTM 的对比效果。基础场景验证预训练是否能提升预测精度、收敛速度及初始学习状态,而替代场景则测试将目标域输入层设置为可训练或固定状态的影响。在两种设置下,预训练模型均表现出比随机初始化更稳定的收敛性与更高的预测精度。尽管迁移学习需要略多的计算时间,但它能可靠地提升模型整体性能,尤其在常规污染条件下。
作者对比了用于空气质量预测的预训练神经网络与随机初始化网络,结果表明预训练模型性能更优且收敛更快。结果因地点与污染物类型而异,预训练模型在精度与训练效率上普遍优于随机初始化。研究还探讨了预训练模型的两个变体,即可训练与不可训练,发现两者均优于随机初始化,但计算成本不同。预训练神经网络在预测精度与训练速度上持续优于随机初始化网络。预训练模型的性能随地点和污染物类型变化,部分配置展现出显著更优的结果。与随机初始化相比,可训练与不可训练的预训练模型均能提升预测性能,两者在计算效率上存在差异。
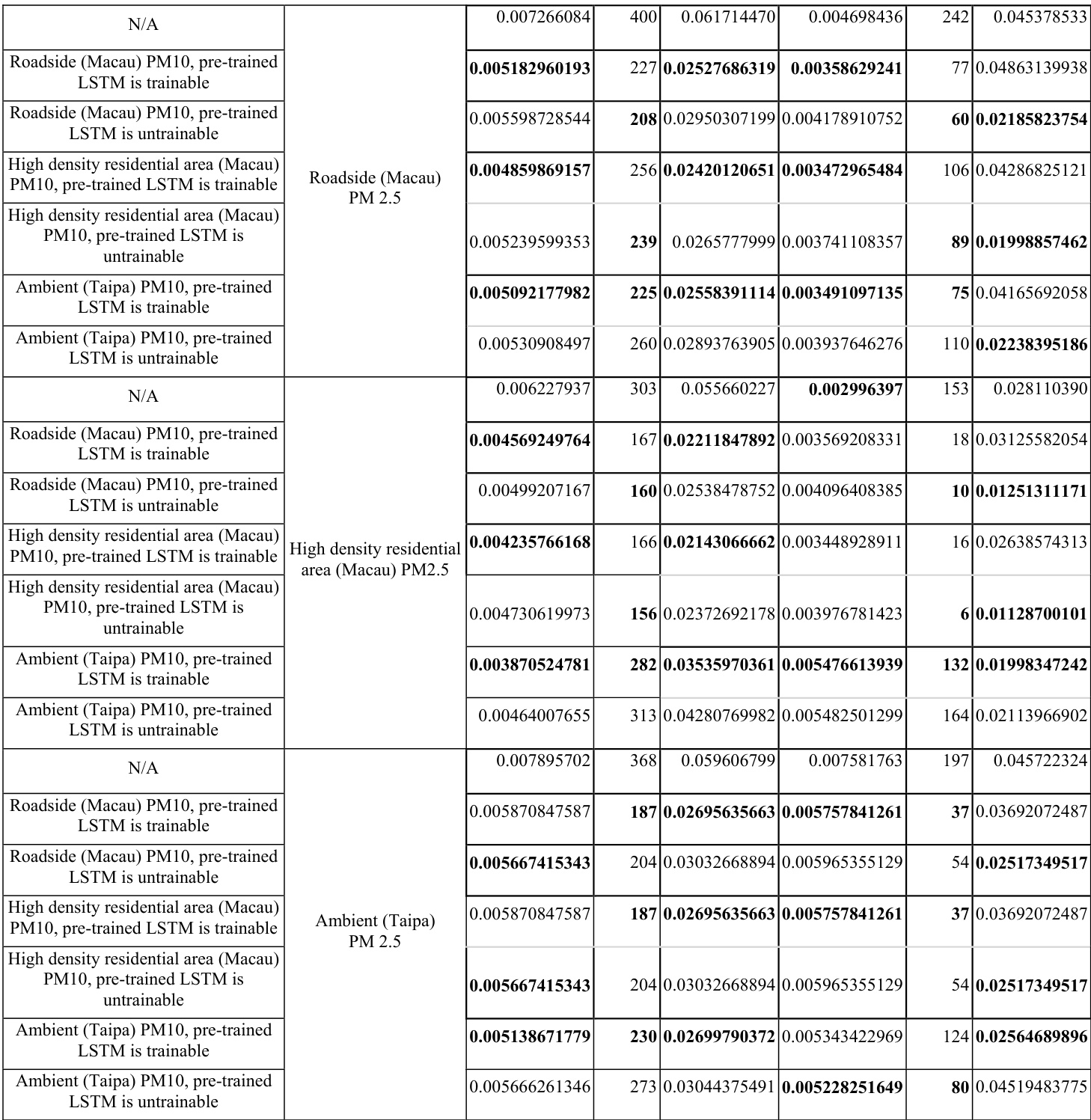
作者对比了随机初始化神经网络与采用迁移学习的预训练网络的性能,重点关注预测精度与训练效率。结果表明,与随机初始化相比,预训练网络通常具有更低的错误率且所需的训练轮次更少,不同空气质量监测站与污染物之间存在一定差异。研究还评估了预训练模型的两个配置,即可训练与不可训练,发现两者均优于随机初始化,但计算成本有所不同。在多个空气质量监测站与污染物中,预训练网络的预测误差持续低于随机初始化网络。预训练模型达到最佳性能所需的训练轮次更少,表明收敛速度更快。可训练与不可训练的预训练模型配置均优于随机初始化,两种方法在计算成本上存在差异。
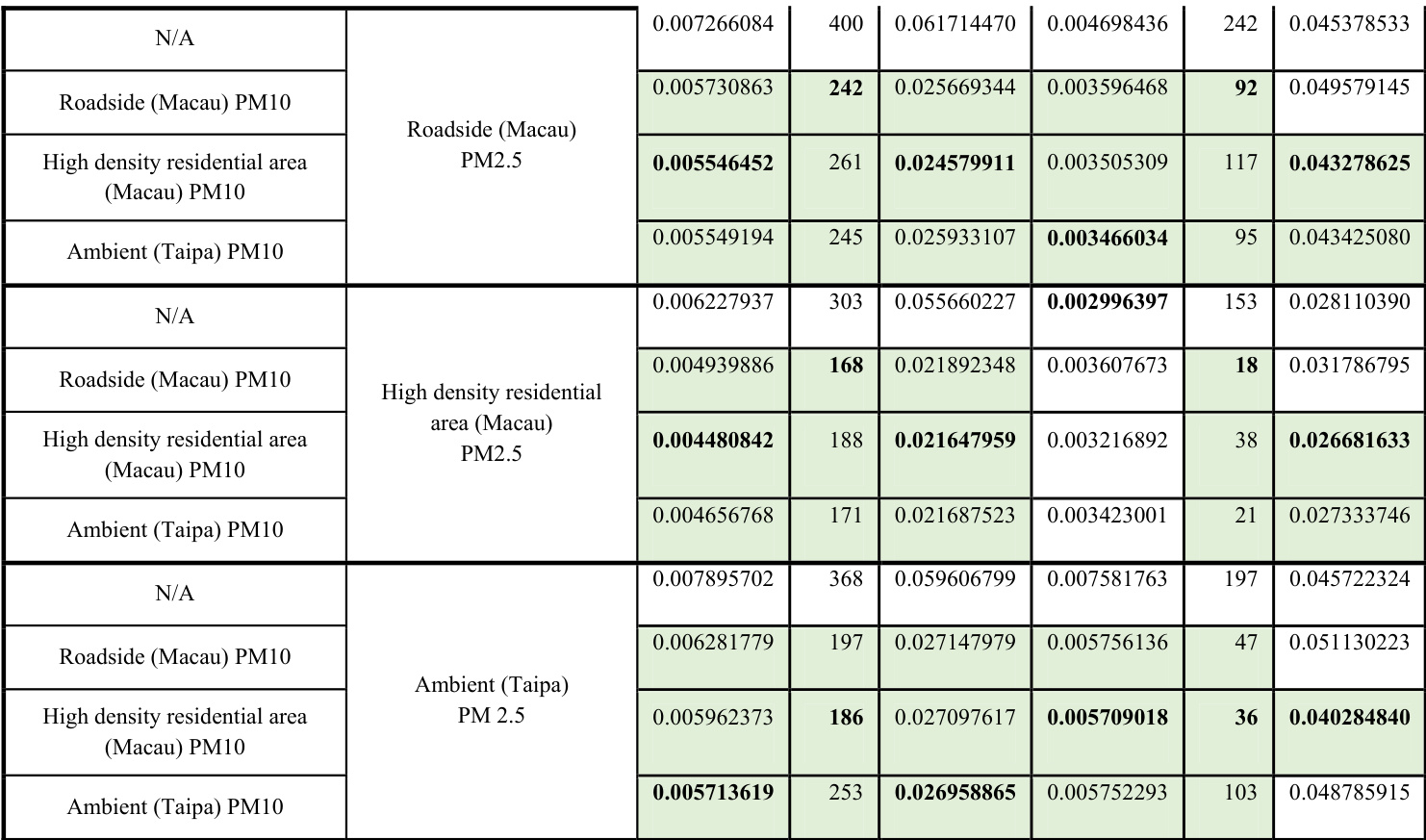
作者对比了预训练神经网络方法与随机初始化方法,利用相关领域的迁移学习来提升预测精度与训练效率。结果表明,与随机初始化相比,预训练模型性能更优且收敛更快,在不同空气质量监测站与污染物中均展现出一致的改进。预训练模型相比随机初始化网络具有更高的预测精度与更快的收敛速度。来自相关领域的迁移学习改善了初始学习状态,并减少了收敛所需的轮次。训练与验证结果均显示,预训练的优势在不同目标域与污染物中保持一致。

作者对比了预训练神经网络方法与随机初始化方法,表明预训练方法在预测精度与学习效率方面表现更佳。结果表明,利用相关站点的迁移学习改善了模型的初始状态与收敛速度,尤其对空气质量预测效果显著。预训练网络相比随机初始化网络展现出更高的预测精度与更快的收敛速度。来自相似污染物与邻近站点的迁移学习优化了初始学习状态与模型性能。预训练方法减少了收敛所需的轮次,并增强了预测能力。
作者对比了预训练神经网络方法与随机初始化方法,表明预训练能带来更优的初始性能、更快的收敛速度及更高的预测精度。结果涵盖不同空气质量监测站与污染物,预训练模型在训练与验证指标上均持续优于随机初始化。预训练神经网络相比随机初始化网络具有更好的初始性能与更快的收敛速度。所提出的利用相关领域迁移学习的方法提升了预测精度并缩短了训练时间。在不同目标域与污染物中,预训练模型均持续优于随机初始化。

实验在多个空气质量监测站与污染物上对比预训练神经网络与随机初始化模型,以验证迁移学习的有效性。结果一致表明,与标准初始化相比,利用相关领域的知识能显著提升预测精度并加速收敛。可训练与不可训练的预训练配置均被证明有效,在提供可靠性能提升的同时伴随着不同的计算权衡。最终,迁移学习优化了初始学习状态,并在多样化的环境条件下降低了整体训练需求。