Command Palette
Search for a command to run...
使用 SWE-Gym 训练软件工程智能体与验证器
使用 SWE-Gym 训练软件工程智能体与验证器
Jiayi Pan Xingyao Wang Graham Neubig Navdeep Jaitly Heng Ji Alane Suhr Yizhe Zhang
摘要
我们发布了 SWE-Gym,这是首个用于训练软件工程(SWE)Agent 的环境。SWE-Gym 包含 2,438 个真实世界任务实例,每个实例均由一个 Python 代码库、可执行运行时环境、单元测试以及用自然语言描述的任务说明组成。我们利用 SWE-Gym 训练基于大语言模型(LLM)的 SWE Agent,在流行的 SWE-Bench Verified 和 Lite 测试集上,解决率(resolution rate)绝对提升了高达 19%。此外,我们还尝试通过在从 SWE-Gym 采样的 Agent 轨迹上训练的验证器(verifiers)进行推理时扩展(inference-time scaling)实验。结合我们微调后的 SWE Agent,我们在 SWE-Bench Verified 和 Lite 上的得分分别达到 32.0% 和 26.0%,反映了开放权重(open-weight)SWE Agent 的新最先进(state-of-the-art)水平。为促进进一步研究,我们公开发布了 SWE-Gym、模型及 Agent 轨迹。
一句话总结
SWE-Gym 是首个用于训练软件工程 agent 的环境,包含 2,438 个真实世界 Python 任务,并提供可执行的运行时、单元测试和自然语言规范;微调后的 agent 在 SWE-Bench Verified 和 Lite 上的解决率绝对提升最高达 19%,再结合基于验证器的推理时扩展,在 SWE-Bench Verified 和 Lite 上分别取得 32.0% 和 26.0% 的新开源权重最优结果。
核心贡献
- SWE-Gym 被引入为第一个用于训练软件工程 agent 的训练环境,提供 2,438 个真实世界 Python 任务,并配有可执行运行时、单元测试和自然语言描述。
- 在 SWE-Gym 上微调语言模型 agent 可在 SWE-Bench Verified 和 Lite 基准上带来最高 19% 的绝对解决率提升。
- 利用 SWE-Gym 中 agent 轨迹训练验证器,可实现推理时扩展,将其与微调后的 agent 结合,在 SWE-Bench Verified 上达到 32.0%,在 Lite 上达到 26.0%,创下新的开源权重最优水平。
引言
作者针对训练用于软件工程的语言模型 agent 所面临的挑战:尽管 SWE‑Bench 等评估基准存在,但它们仅衡量性能,并不提供通过训练改进 agent 所需的可执行环境、仓库级上下文和测试套件。他们引入了 SWE‑Gym,这是第一个训练环境,提供 2,438 个真实世界 Python 任务,并配有预配置的运行时、单元测试和自然语言指令。通过在这些任务上微调 agent,并在收集的 agent 轨迹上训练验证器以实现推理时扩展,他们在 SWE-Bench Verified 和 Lite 上取得了新的开源权重最优结果,解决率分别达到 32.0% 和 26.0%。
数据集
SWE-Gym:一个面向软件工程 agent 的训练环境
作者引入 SWE-Gym,一个从真实世界 GitHub pull request 和 issue 构建的数据集和训练环境。它提供可执行的任务以及经过验证的测试套件,用于训练和评估基于 LLM 的软件工程 agent。
-
主 SWE-Gym
- 包含从 11 个流行 Python 仓库(与 SWE-Bench 无重叠)的合并 pull request 中收集的 2,438 个任务。
- 每个任务将自然语言 issue 描述与预配置的可执行环境及专家验证过的单元测试配对,用于验证。
- 仓库包含如 pandas 和 MONAI 等复杂项目;分布呈长尾状。
-
SWE-Gym Lite
- 一个精心挑选的 230 个较简单、自包含任务的子集。
- 遵循 SWE-Bench Lite 的流程从主集筛选:排除编辑多个文件、问题描述质量差、涉及过于复杂的地面真相补丁或测试仅检查错误消息的任务。
-
SWE-Gym Raw
- 一个更大的集合,包含来自 358 个仓库的 64,689 个 Python GitHub issue。
- 这些实例缺少预安装的可执行环境,旨在用于自动数据集合成的研究。
-
本文如何使用这些数据
- 作者通过在可执行环境中运行强前沿模型(GPT-4o、Claude 3.5 Sonnet)来采样交互轨迹。
- 他们改变解码温度和最大交互轮数,只保留通过单元测试的轨迹。
- 从 SWE-Gym Lite 和完整的 SWE-Gym 集合中,他们收集了 491 条成功轨迹(记为 D₂)。
- 这些轨迹作为软件工程 agent 的监督微调数据,并且测试结果为训练验证器提供奖励信号。
-
处理和构建细节
- 未对任务进行额外的裁剪或预处理;任务直接使用 SWE-Gym 环境提供的原样。
- 每个实例包含一个仓库快照、issue 文本,以及一个自动验证生成的 git patch 的可执行测试套件。
- 在轨迹收集期间,agent 的最大交互轮数根据实验限制为 30 或 50。
- 该环境紧密模仿 SWE-Bench 的格式,确保兼容性,同时使用无重叠的仓库以避免污染。
方法
作者利用 SWE-Gym 环境来扩展 agent 性能,主要通过使用习得的验证器进行推理时扩展。从环境中采样的轨迹不仅用于训练策略,还用于训练结果监督的奖励模型。这个验证器模型将任务执行的相关上下文作为输入,包含问题说明、agent 轨迹和当前 git diff。然后它生成一个分数,估计 agent 成功解决问题的概率。在推理时,作者尝试使用该模型对从 agent 策略采样的候选轨迹进行重排序,证明此类习得验证器能够有效扩展,实现进一步的性能提升。
对于 MoatlessTools 验证器的具体实现,作者设计了一种专门的提示生成过程。与依赖于专有模型提取上下文的方法不同,该方法直接从被评估的 agent 轨迹中获取上下文。系统提示将该模型设定为擅长 Python 的软件工程和代码审查专家,要求其审查补丁并就代码质量提供反馈。用户提示指示该模型评估一个旨在解决特定 issue 的候选补丁。为辅助此评估,提示提供了来自 GitHub 仓库的 issue 文本,以及与该 issue 相关的代码片段。这些代码片段包括文件路径、唯一的片段标识符和行号,以提供足够的上下文。此外,提示包含候选补丁本身,使用不同的标签展示原始代码和打补丁后的代码块。然后要求验证器输出一个二值结果,指示补丁是否成功解决了该 issue。
实验
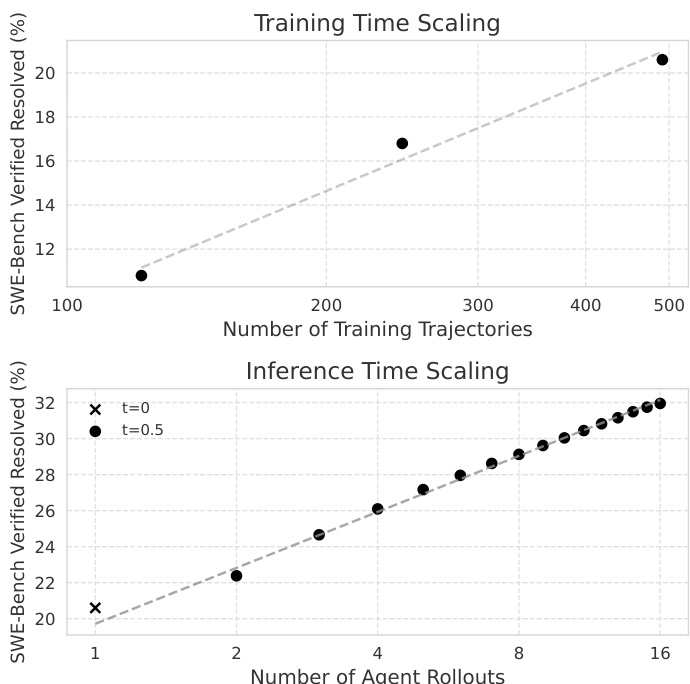
SWE-Gym 提供基于 GitHub issue 的真实世界 Python 任务的可执行训练环境,从而可以微调语言模型 agent 和验证器。仅在 491 条采样轨迹上训练 agent 就在 SWE-Bench 上带来可观的解决率提升,大幅减少陷入循环行为,并随模型规模和数据集大小良好扩展。训练后的验证器从多个候选解中选择最佳方案,为开源权重系统设立了新标杆,并证明了推理计算带来的对数线性增益。这些发现表明,当前性能的限制在于采样计算而非环境多样性,并且专门的工作流可实现有效的自我改进,同时通过每个实例的上限来缓解简单任务偏差。
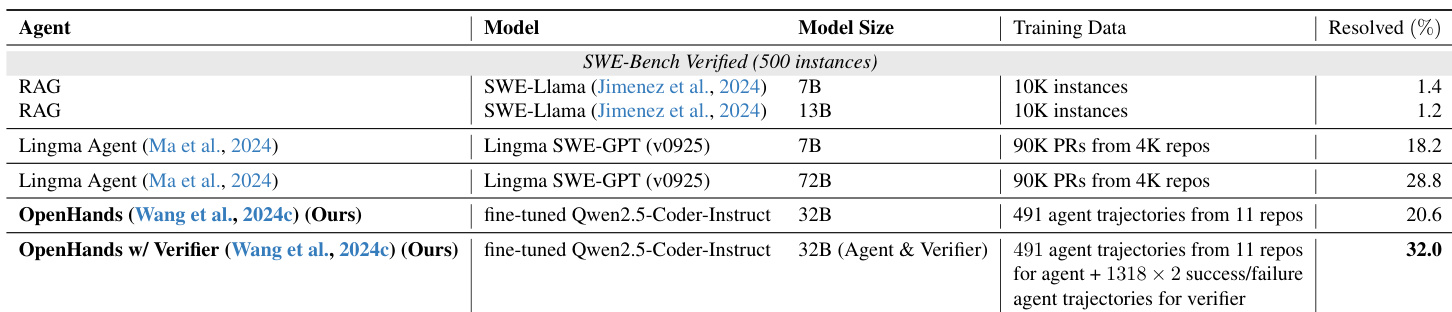
作者将他们的 SWE-Gym agent 和验证器系统与同期工作进行比较,证明其方法尽管模型规模明显较小,仍在 SWE-Bench 基准上取得有竞争力的性能。同期工作 Golubev 等人虽然在 Verified 拆分上取得了最高性能,但依赖大得多的模型,且未发布模型权重。相比之下,作者的系统完全开源了模型权重和环境,提供了更完整的解决方案。作者的 32B 模型在 SWE-Bench Lite 和 Verified 两个拆分上均优于 Ma 等人的 72B 模型。作者的方法是所列方法中唯一同时发布模型权重和执行环境从而实现完全开放的方法。Golubev 等人在 SWE-Bench Verified 上取得了最高性能,但未发布其模型权重。

所提供的表格比较了不同软件工程 agent 在 SWE-Bench Verified 基准上的解决率。作者提出的系统将验证器与 OpenHands agent 集成,在所列方法中实现了最高性能。这一结果表明,他们的方法在使用明显更少的训练数据的情况下,能够超越同期工作中规模更大的模型。结合验证器的作者 OpenHands agent 达到了最高解决率,超过了 RAG 基线和如 Lingma SWE-GPT 等更大模型。所提方法表现出强大的数据效率,使用在小规模轨迹集上训练的 32B 模型,超过了在大数据集上训练的 72B 模型。加入验证器模型大幅提升了基础 agent 的性能,在比较中取得了最佳总体结果。
作者研究了在使用专门工作流框架进行自我改进训练时,通过每个实例的上限策略来减轻数据偏差。结果表明,限制每个任务实例的成功轨迹数量可提高性能,某个特定阈值实现了最佳解决率和最低的空补丁率。该方法优于在完整未设上限的数据集上训练,提示未过滤数据会引入对较简单任务的偏差。与更高的上限和未设上限的数据集相比,应用适度的每个实例上限可产生最高的解决率和最低的空补丁率。在未设上限的完整数据集上训练,其解决率略低于最佳上限,可能由于偏向较简单任务。与零样本基线相比,微调显著降低了空补丁率,表明模型学习更有效地生成代码编辑。

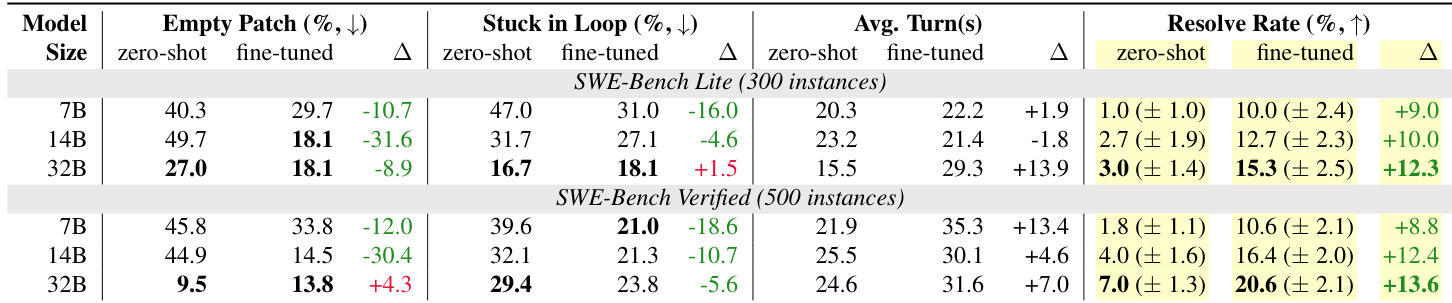
作者使用 SWE-Gym 中的 agent-环境交互轨迹微调不同规模的 Qwen-2.5-Coder 模型,以提高软件工程能力。结果显示,微调大幅提高了 SWE-Bench 基准上的解决率,同时普遍降低了空补丁率和陷入循环率。此外,更大的基础模型持续取得更高的解决率,表明在微调前后,模型规模都能带动性能扩展。在 SWE-Gym 轨迹上微调显著提升了所有评估模型大小的任务解决率。训练过程有效降低了大多数模型的空补丁和陷入循环行为的频率。在零样本和微调设置下,更大的模型始终取得更好的解决率和更低的错误率。
该表格展示了 agent 轨迹长度的统计信息,区分了已解决和未解决的尝试。虽然平均消息数和 token 数相当,但不成功轨迹的方差和最大 token 限制要高得多。这暗示失败的尝试往往比更加一致的成功轨迹更不稳定和冗长。收集到的数据集中,不成功轨迹的数量远多于成功轨迹。成功轨迹在消息数和 token 数上都表现出更低的标准差,表明行为更为一致。不成功轨迹达到了更高的最大 token 数,说明失败的 agent 经常产生过长的响应。

作者在 SWE-Bench 基准上评估了他们的 SWE-Gym agent 系统,证明一个开源的 32B 模型结合验证器可在 Verified 拆分上取得最优性能,超越更大的同期模型和 RAG 基线,且使用的训练数据显著更少。自我改进训练期间的每个实例上限缓解了数据偏差,与使用完整未过滤的数据集相比,带来了更高的解决率和更少的空补丁。在 SWE-Gym 的 agent 轨迹上微调持续提高解决率,并降低不同模型规模的空补丁和陷入循环错误,更大模型扩展效果更好;轨迹分析显示,成功尝试更为一致,而不成功尝试往往更不稳定和冗长。