Command Palette
Search for a command to run...
一键部署遗传算法教程
摘要
一句话总结
GAPA 是一个分布式并行框架,通过重构遗传操作并提供可扩展的库,加速用于扰动子结构优化的遗传算法,在涵盖四个图挖掘任务和十种算法的 18 个数据集上,相比 Evox 实现了平均四倍的速度提升。
核心贡献
- GAPA 是一个基于 PyTorch 的加速框架,专为遗传算法驱动的扰动子结构优化设计。该框架重构了核心遗传操作,并实现了四种并行计算模式,以实现高效分布式执行。
- 该框架提供了一个包含十种基于 GA 的算法的可扩展库,覆盖四个图挖掘任务,并提供简化的函数式编程接口以实现算法的快速部署。
- 在 18 个数据集上的评估表明,该框架在保持解的质量的同时,相比 Evox 基线实现了平均四倍的加速。
引言
遗传算法正日益应用于扰动子结构优化,这是一项图挖掘任务,通过修改网络拓扑来解决社区发现、链接预测和节点分类等关键应用。尽管这些算法在全局搜索方面表现优异,但在扩展到复杂真实网络时会面临严重的计算瓶颈。现有的加速框架难以处理领域特定的遗传操作,且强制使用限制性编程范式,阻碍了图扰动所需的迭代状态修改。为突破这些限制,本文提出 GAPA,这是一个基于 PyTorch 的框架,通过重构遗传操作并实现四种并行计算模式,专门针对扰动子结构优化进行设计。通过将上述创新封装为可扩展库,该框架能够加速四个主要任务中的十种图挖掘算法,在保持解质量的前提下,执行速度相比主流基线最高提升四倍。
方法
研究团队采用了一种专为扰动子结构优化(PSSO)问题设计的遗传算法(GA)并行加速框架,即 GAPA。该框架的核心旨在通过批处理矩阵方法优化遗传操作,包括种群初始化、交叉、变异、适应度计算和精英保留,从而实现高效的硬件加速。整体工作流程始于种群初始化,其中每个个体表示为一个扰动向量。随后,这些个体被转换为种群矩阵 POP,以促进遗传操作的并行执行。该框架通过将传统的扰动评估迭代过程分解为一系列矩阵操作,实现在单个计算步骤中同时处理多个个体。
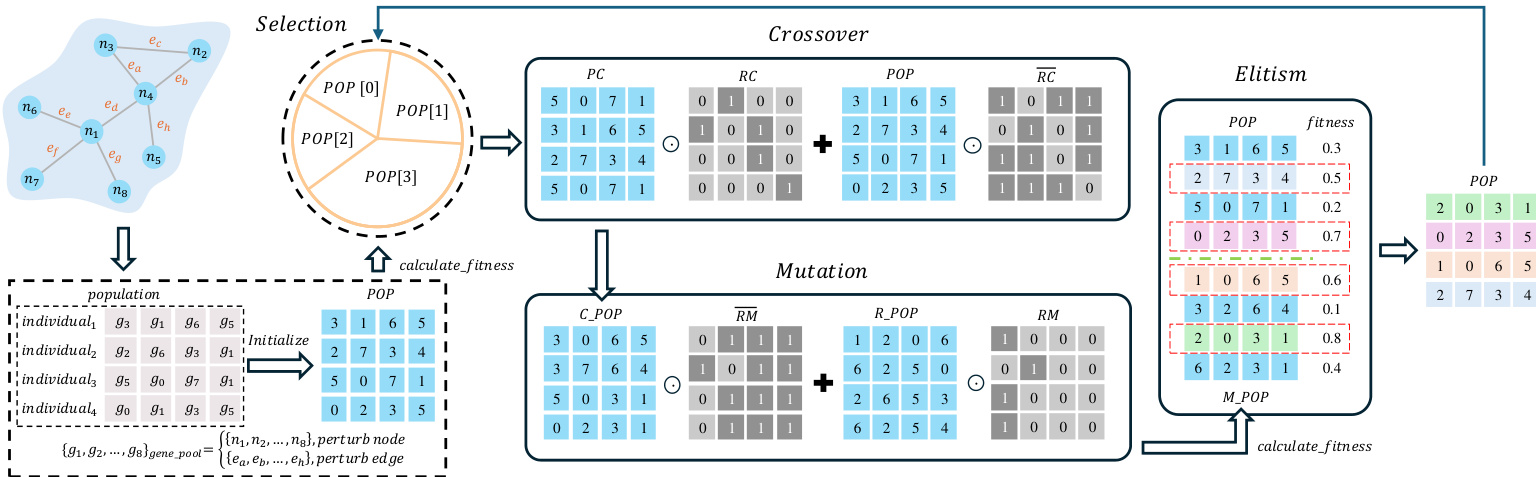
如图下方所示,初始化阶段将个体扰动转换为矩阵表示,从而支持后续遗传操作的并行执行。交叉操作实现为两个父代矩阵 PC 和 RC 之间的矩阵加法,生成新的种群矩阵 POP。类似地,变异操作将变异掩码 RM 应用于种群矩阵,生成变异后的种群 CPOP。这些操作专为在 GPU 等并行硬件上高效执行而设计,通过利用矩阵的规则结构和各元素的独立性来实现。
适应度计算是 GA 中关键且耗时的环节,该框架通过重构评估流程对其进行优化。框架不再迭代更新和评估每个扰动,而是通过单次批处理操作计算种群矩阵的适应度。这一过程通过将网络转换为邻接矩阵 A,并直接通过矩阵运算应用扰动来实现。基于六度分隔定理设计的适应度函数,通过计算可达矩阵 M 来评估网络连通性。该矩阵由邻接矩阵的幂次求和推导而来,利用二项式定理进行简化以降低计算复杂度。生成的矩阵 M 提供了各节点连通性的度量,其中最大值作为适应度得分。该方法显著减少了所需的矩阵乘法次数,从 O(N⋅n3) 降低至 O(log2N⋅n3),从而加快收敛速度。
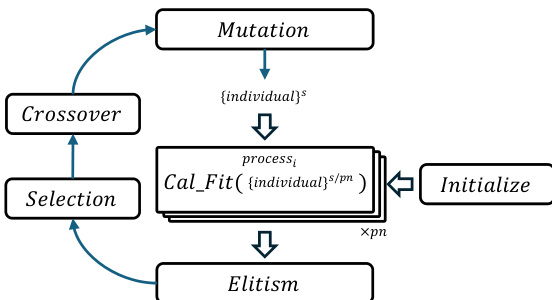
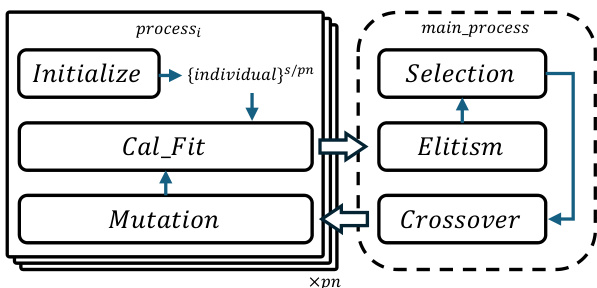
该框架通过采用基于进程的并行化策略进一步提升了效率。主进程负责编排遗传操作,多个工作进程则并行处理各自的任务。每个工作进程初始化部分种群,并计算分配个体的适应度。随后结果与主进程进行交换,主进程执行选择、交叉和精英保留操作。这种分布式方法实现了动态负载均衡和计算资源的高效利用。框架支持单机和多机配置,进程间的数据交换通过集中式主进程进行管理。模块化设计支持不同遗传操作和适应度函数的无缝集成,使其能够适配各类 PSSO 问题。
实验
评估设置使用 CPU 和多 GPU 环境,在多种网络优化任务、数据集和算法上测试 GAPA,以评估四种不同的加速模式、不同种群规模以及分布式计算配置。实验验证了该框架显著加速了基于遗传算法的计算负载,且随着数据规模增加,多进程模式始终提供优异的性能。定性结果表明,加速收益随种群和数据集规模的增大而正向增长,尽管分布式部署最终会因进程间通信开销而遭遇收益递减。总体而言,结果证实 GAPA 有效平衡了计算效率与资源利用率,在大规模进化计算任务中优于现有加速框架。
研究团队评估了 GAPA 在不同加速模式、数据集和任务上的性能,重点关注计算时间与算法效率。结果显示,GPU 加速显著提升了大规模数据集的性能,其中 M 模式通常提供最佳加速效果。加速效果随种群规模和数据集规模的增大而提升,且在大多数情况下 GAPA 优于 Evox,尤其是在大规模数据集上。M 模式在各类任务和数据集上始终实现最佳加速性能,尤其针对大规模问题。随着种群规模和数据集规模的增加,加速效果愈发显著,GAPA 在多数情况下表现优于 Evox。S 模式和 M 模式在大规模数据集上展现出显著加速,但在 GPU 数量较多时,数据传输开销限制了性能提升。
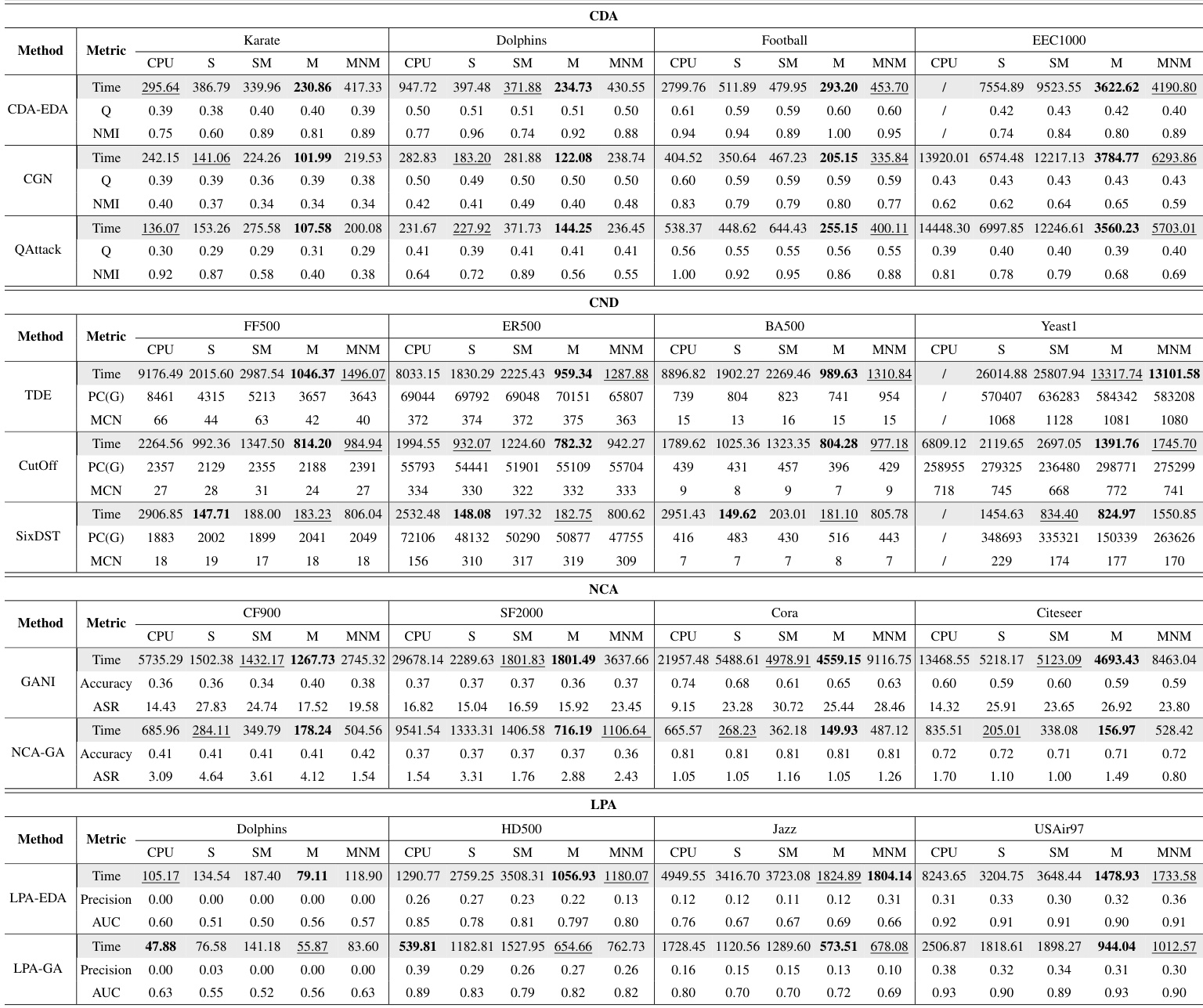
研究团队评估了 GAPA 在不同加速模式、种群规模和数据集上的性能,重点关注其提升基于遗传算法问题计算效率的能力。实验表明,加速效果因计算负载而异:更大的数据集和种群规模带来更显著的加速,尤其在 M 模式中;而小规模计算可能无法从 GPU 加速中获益。在加速计算密集型算法方面,GAPA 优于 Evox,尤其是在大规模数据集上。GAPA 在大规模数据集和种群规模下实现显著加速,M 模式通常提供最佳性能。GPU 加速的有效性随计算负载增加而提升,因为轻量级任务可能无法从 GPU 处理中获益,甚至可能受到阻碍。与 Evox 相比,GAPA 展现出更优越的加速能力,尤其在大规模数据集和计算密集型算法上。

研究团队使用多种算法和数据集,评估了 GAPA 在四个任务类别(CDA、CND、NCA 和 LPA)上的性能,重点关注加速模式、种群规模与分布式计算。实验表明,GPU 加速显著缩短了计算时间,尤其针对大规模数据集和重负载任务,M 模式通常表现最佳。随着种群规模和数据集规模的增大,加速效果愈发明显,而轻量级计算从 GPU 加速中获得的收益极小甚至为负。分布式加速进一步提升了性能,但随着 GPU 数量增加,数据传输开销增大导致收益递减。GPU 加速显著改善了大规模数据集和重负载任务的计算时间,M 模式提供最佳性能。GAPA 的加速效果随种群规模和数据集规模增加而提升,轻量级计算从 GPU 加速中获得的收益极小或为负。分布式加速提升了性能,但增加更多 GPU 会因数据传输开销增加而导致收益递减。
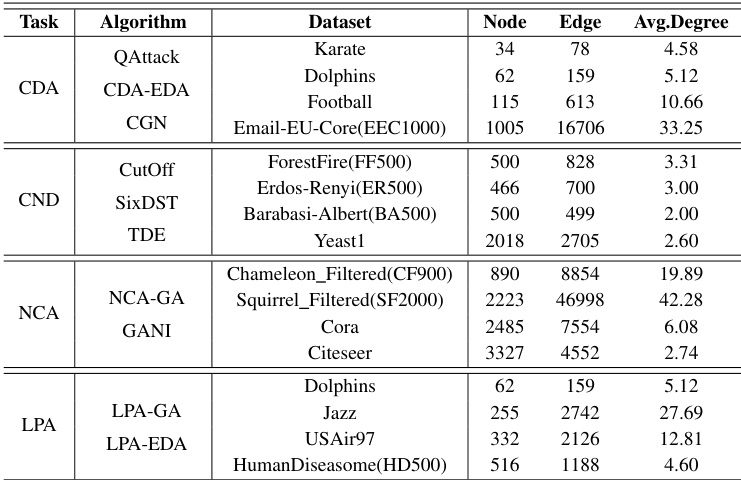
研究团队评估了 GAPA 在四种加速模式和多个数据集上的性能,重点关注计算效率与可扩展性。结果显示,M 模式通常提供最佳加速效果,尤其适用于大规模数据集和种群规模;而 S 模式因开销较高效果相对较弱。随着数据集规模和种群规模的增加,加速效果显著提升,且在多数情况下 GAPA 展现出优于 Evox 的性能。表格指出,GPU 加速在重计算任务中优于 CPU,但当数据传输开销显著时,收益会下降。M 模式始终实现最佳加速性能,尤其针对大规模数据集和种群规模。对于重计算任务,GPU 加速显著优于 CPU,但数据传输开销增加时收益会下降。与 Evox 相比,GAPA 展现出更优越的加速能力,尤其在 EEC1000 和 Yeast1 等大规模数据集上。
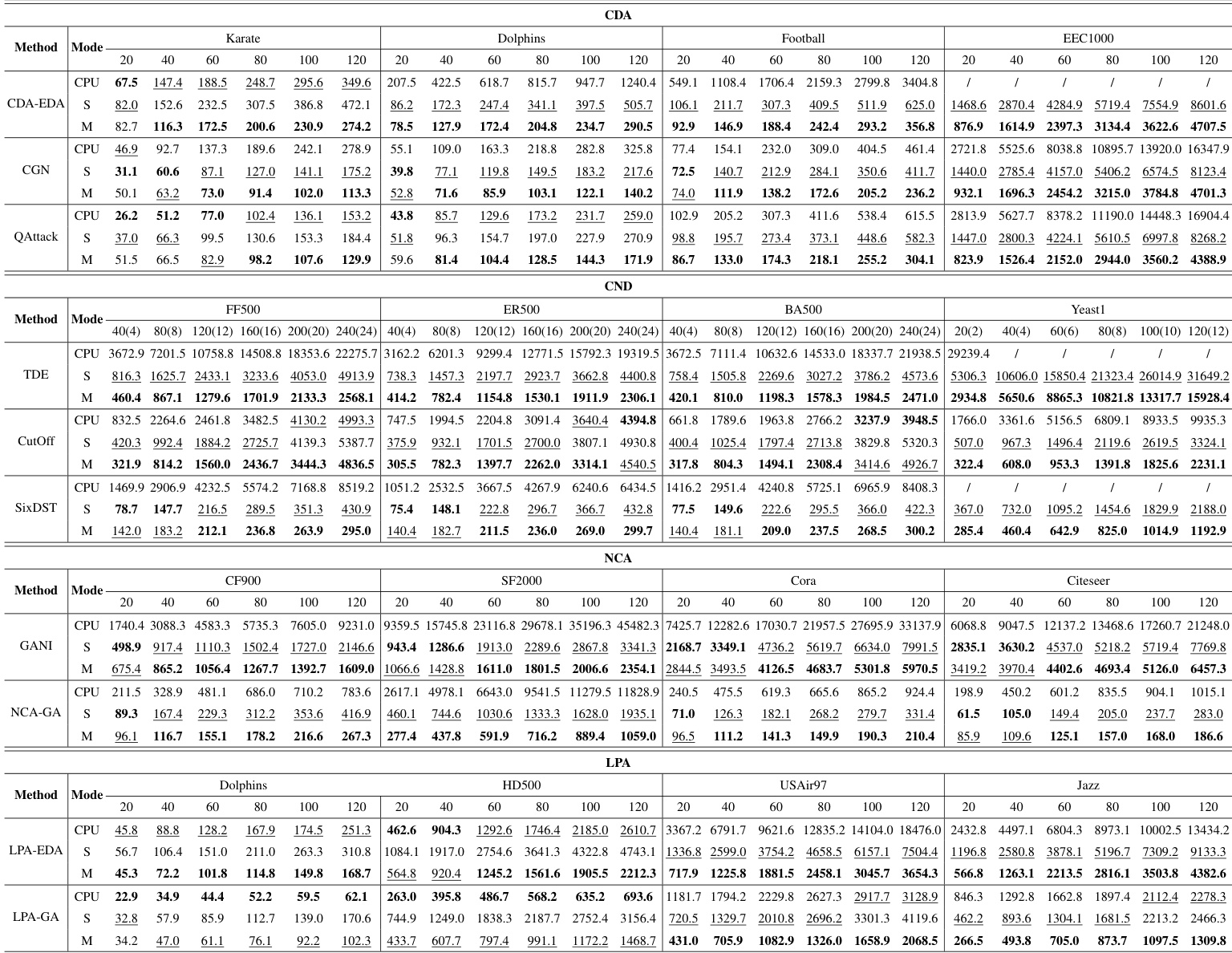
实验在多种加速模式、数据集和种群规模下评估 GAPA,以验证其在不同任务类别中的计算效率与可扩展性。结果表明,GPU 加速大幅提升了性能,尤其在 M 模式中,且收益随数据集规模增大和计算负载加重而正向增长。相反,轻量级任务以及使用过多 GPU 的配置会因数据传输开销而遭遇收益递减。总体而言,GAPA 始终提供卓越的加速效果与可扩展性,确立了其在大规模遗传算法应用中的有效性。