Command Palette
Search for a command to run...
使用序列到序列模型和点注意力机制的机器翻译
摘要
一句话总结
作者提出了一套系统性框架,通过注意力熵与对齐一致性指标评估神经机器翻译的可解释性。该框架在英德双语 WMT14 测试子集上,定量比较了预训练 mT5 的注意力模式与统计对齐结果,并将其与标准的机器翻译质量指标进行相关性分析。
核心贡献
- 引入了一套系统性框架,通过将神经机器翻译的注意力模式与统计词对齐及标准翻译质量指标进行对比,实现定量评估。
- 提出注意力熵与对齐一致性指标以衡量注意力聚焦分布,证明尖锐的注意力分布与 BLEU 和 METEOR 分数的轻微提升相关,且更贴近外部参考对齐结果。
- 在 WMT14 的英德子集上基于预训练 mT5 模型验证了该框架,并辅以可视化热力图与统计图表,阐明注意力可解释性与翻译性能之间的关系。
引言
神经机器翻译(NMT)模型虽已达到最先进的性能水平,但仍是缺乏透明度的黑盒模型,因此对可解释性存在迫切需求,以验证内部行为并建立用户信任。尽管注意力机制被广泛用于解释模型决策,但先前研究表明,注意力权重并非专门设计为词对齐结果,且常存在错位问题,这限制了其作为直接可解释性代理的可靠性。作者通过提出一种定量框架来填补这一空白。该框架通过注意力熵与对齐一致性指标评估注意力模式,并将这些指标与统计真值对齐及翻译质量分数进行系统关联,从而区分可解释性与实际性能。
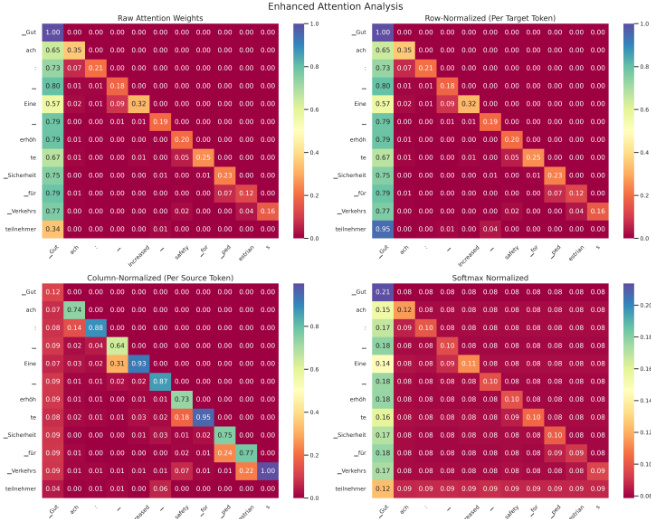
方法
作者利用基于 Transformer 的神经机器翻译(NMT)模型,具体为经过微调的 mT5 架构,执行英德翻译任务。该模型通过自回归方式生成目标 tokens,其中位置 t 处的每个 token yt 的概率由解码器的隐藏状态 ht 及此前生成的 tokens y<t 决定,并以源句子 x 为条件。该条件概率计算方式为 P(yt∣x,y<t)=softmax(Wht),其中 W 为学习到的投影矩阵。
如图所示,模型的注意力机制在决定每个目标 token 如何关注源 tokens 方面发挥核心作用。对于给定的目标 token yt,注意力分布 αt=(αt,1,αt,2,…,αt,∣X∣) 表示分配给每个源 token xs 的权重,且约束条件为源句子中所有注意力权重之和等于 1。为评估注意力的集中程度,作者为每个目标 token 计算注意力熵 Ht,其定义为 Ht=−∑s=1∣X∣αt,slog(αt,s)。较低的熵值表明注意力更集中于少量源 tokens,而较高的熵值则反映注意力分布更为分散。随后,在句子或整个语料库的所有目标 tokens 上计算平均注意力熵 Havg,以总结该行为特征。
为评估注意力机制的可解释性,作者引入了一套框架,将模型的注意力模式与通过 FastAlign 获取的外部对齐参考进行对比。这些参考数据由对齐对 A={(si,tj)} 组成,用于将源索引映射到目标索引。对齐一致性得分定义为所有对齐对的平均注意力权重:Agreement=∣A∣1∑(si,tj)∈Aαtj,si。较高的对齐一致性得分表明模型的注意力分布与统计对齐参考高度吻合,这意味着注意力机制能够提供更具可解释性且符合人类认知习惯的源 tokens 与目标 tokens 之间的映射关系。
实验
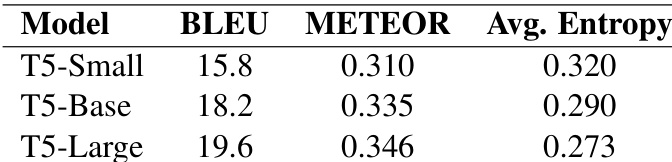
该评估框架通过将质量指标与注意力分布及统计对齐结果进行关联,在不同模型容量下评估翻译性能与注意力可解释性。初步实验验证了模型容量的增加能够带来更高的翻译质量与更集中的注意力模式,同时相关性分析证实,更尖锐的注意力分布与类人对齐一致性高度吻合,并对翻译分数的提升起到适度推动作用。最终结果表明,可解释性与性能之间存在内在关联。这暗示注意力聚焦程度的提升虽不能保证实现最优翻译,但为开发更具透明度的神经机器翻译系统提供了一条可行路径。
作者在 T5 模型的不同变体上评估了翻译质量与注意力可解释性,发现更大规模的模型能够实现更高的翻译质量,并表现出更集中的注意力模式。结果显示,注意力熵的降低与对齐一致性的提升及翻译指标的轻微改善相关,这表明模型容量、可解释性与性能之间存在关联。与较小规模的模型相比,较大规模的模型展现出更高的翻译质量与更低的注意力熵。较低的注意力熵与更好的对齐一致性相关,表明注意力更加集中且具备更高的可解释性。注意力熵的降低与轻微提升的翻译质量相关联,暗示二者存在适度的正向关系。
作者分析了不同规模 T5 模型的注意力模式,考察注意力归一化方法对可解释性与对齐效果的影响。结果显示,较大规模的模型表现出更集中的注意力分布,这与对齐效果的改善及翻译质量指标的轻微提升相关。分析表明,较低的注意力熵与更好的对齐一致性以及适度提升的质量得分相关,这进一步印证了可解释性与性能之间的关联。在不同归一化方法下,较大规模的模型均展现出更集中的注意力模式,表明其可解释性得到改善。较低的注意力熵与更高的对齐一致性相关,说明更强规模的模型具备更符合人类认知习惯的注意力分布。熵值的降低往往对应着翻译质量的轻微提升,表明可解释性与性能之间存在适度的正向关联。
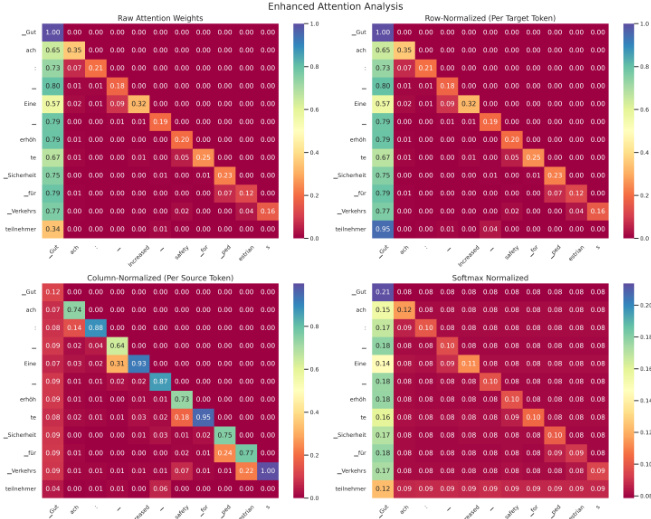
该评估在规模各异的 T5 模型变体上检验了翻译质量与注意力可解释性,验证了模型容量、注意力归一化与对齐行为之间的关系。结果证明,较大规模的模型在生成更高质量翻译的同时,逐渐形成更集中的注意力分布。这种以注意力熵降低为特征的关注度提升,更贴近人类判断标准,并与性能改善呈现适度相关,从而在模型规模、可解释性与整体效能之间确立了清晰的定性关联。