Command Palette
Search for a command to run...
扩展VSR基准以适配VLLM,专精于空间规则
扩展VSR基准以适配VLLM,专精于空间规则
Peijin Xie Lin Sun Bingquan Liu Dexin Wang Xiangzheng Zhang Chengjie Sun Jiajia Zhang
使用 vLLM 部署 QwQ-32B
摘要
区分空间关系是人类认知的基本组成部分,需要对跨实例进行细粒度感知。尽管MME、MMBench和SEED等基准已经全面评估了包括视觉空间推理(VSR)在内的多种能力,但针对视觉大语言模型(VLLMs)且专门聚焦于视觉位置推理的充足数量和质量评估与优化数据集仍然匮乏。为解决这一问题,我们首先使用VSR数据集对当前VLLMs进行了诊断,并提出了一个统一的测试集。我们发现当前的VLLMs表现出对语言指令过度敏感而对视觉位置信息欠敏感的矛盾现象。通过从调整数据和模型结构两个方面扩展原始基准,我们缓解了这种现象。据我们所知,我们首次利用扩散模型可控地扩展了空间定位图像数据,并将原始的视觉编码器(CLIP)与其他三种强大的视觉编码器(SigLIP、SAM和DINO)进行了整合。在进行了数据和模型的扩展组合实验后,我们获得了一个VLLM VSR专家(VSRE),它不仅对不同指令具有更好的泛化能力,还能准确区分视觉位置信息的差异。VSRE在VSR测试集上的准确率提高了27%以上。
一句话总结
作者提出了VSRE,这是一种视觉大语言模型。该模型通过基于扩散模型的数据扩展以及将CLIP与SigLIP、SAM和DINO进行整合,缓解了模型对语言指令过度敏感以及对视觉位置信息敏感度不足的问题,在VSR测试集上实现了超过27%的准确率提升。
核心贡献
- 引入了一个用于视觉空间推理的统一评估测试集,并提出了一种基于扩散模型的方法,以可控方式扩展具有空间位置信息的图像数据,从而优化视觉大语言模型。
- 该架构将CLIP与SigLIP、SAM和DINO视觉编码器进行整合,并应用针对性的数据调整,以缓解视觉模型过度依赖文本指令而未能充分利用视觉位置线索的冲突倾向。
- 提出的VSRE模型在视觉空间推理测试集上实现了超过27%的准确率提升,并在面向细粒度位置感知任务的各种指令中展现出增强的泛化能力。
引言
视觉空间推理是视觉大语言模型的一项基础能力,但当前的基准测试缺乏高质量、针对性的数据集,无法对位置理解能力进行有效评估与优化。现有模型通常存在显著的能力差距,表现为过度依赖文本指令,同时对实际的视觉位置线索敏感度不足。为解决这一问题,作者分析了该不平衡现象,并利用扩散模型可控地扩展具备空间感知能力的图像数据。随后,他们在扩展架构中将CLIP与SigLIP、SAM和DINO视觉编码器进行整合,以开发VSRE模型。该方法显著提升了指令泛化能力与位置辨别能力,在VSR基准测试上带来27%的准确率增益,同时开源了数据集与模型以推动该领域发展。
数据集
- 数据集构成与来源: 作者以VSR数据集为基础,该数据集从MSCOCO中筛选出超过1万组自然图像与文本对。他们采用对比式标题生成方法,并经过第二轮人工验证,以确保位置关系清晰,并在66种不同的空间关系类型中实现均衡分布。
- 子集详情与规模: 训练核心包含1.1万组结构化三元组,涵盖主体、空间关系与客体。这些三元组衍生出多个子集:用于预训练的pre-100k和pre-500k,用于指令微调的turn-g 500k、turn-g 11k和turn-s 11k,以及两个评估集Test-G和Test-S。Test-G在50种模板中随机打乱提示词以衡量指令遵循的泛化能力,而Test-S则固定为特定的真假标题格式,以评估空间推理的峰值性能。
- 训练用途与数据混合: 在预训练阶段,作者以5:3:2的比例组合三种图像增强策略,将数据集规模扩展至10万或50万样本。在指令微调阶段,他们使用50种不同的提示词模板,将1.1万组基础三元组扩充约50倍,达到50万样本。未扩充的1.1万组样本作为受控基线,其中一组为每个样本随机应用模板,另一组则使用固定模板。
- 处理与元数据构建: 每个原始样本均通过spaCy进行解析,提取主体-关系-客体三元组以及主体和客体的边界框坐标。为增强空间感知能力,作者冻结原始标题,并使用SDXL生成多样化的图像变体。他们依次应用三种增强策略:图像到图像的重新绘制以保留背景一致性,文本到图像的生成以变换风格与颜色,以及基于边界框引导的修复操作以交换主体与客体。文本数据同时通过混合30个手动筛选与20个GPT-4o生成的提示词模板进行多样化处理,以提升指令遵循的鲁棒性。
方法
作者采用融合视觉编码器架构,以提升视觉语言模型在视觉空间推理方面的能力。该框架整合了多个预训练视觉骨干网络,具体包括CLIP、SigLIP、DINOv2和SAM,各网络为整体视觉特征表示贡献了独特的优势。该设计基于实证证据,表明结合多种视觉编码器能够提升以视觉为中心的任务性能,尤其是需要细粒度视觉细节感知的任务。如图下方所示,每个骨干网络均通过专用的投影器或适配器模块进行处理,以将各自的visual tokens对齐至统一的表示空间。随后,这些对齐的特征沿特征维度进行拼接,形成包含高层语义信息与细粒度空间细节的复合视觉嵌入。该方法借鉴了MoF、MG-LLaVA和Cambrian等 prior work,证明了多编码器融合在视觉定位中的优势。
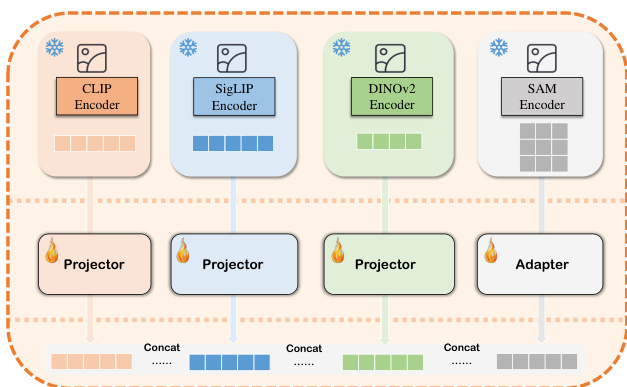
视觉编码器的扩展辅以数据增强流水线,通过生成多样化的图像-文本对来提升模型泛化能力。该过程涉及可控图像生成技术,包括文本到图像、图像到图像以及图像修复,用于根据文本提示与现有图像生成新的视觉输入。生成的图像随后与重写后的文本描述配对,重点强调空间关系与物体位置。此过程通过物体摆放、场景构图与上下文线索的变化丰富训练数据,从而增强模型对视觉空间配置的推理能力。整合这些增强数据与融合视觉编码器的设计旨在解决现有视觉语言模型的局限性,例如对文本提示过度敏感以及对视觉位置信息缺乏敏感度。整体框架的结构旨在使模型通过增强数据与更强大的视觉编码器,发展出更稳健且专业的空间推理理解能力。
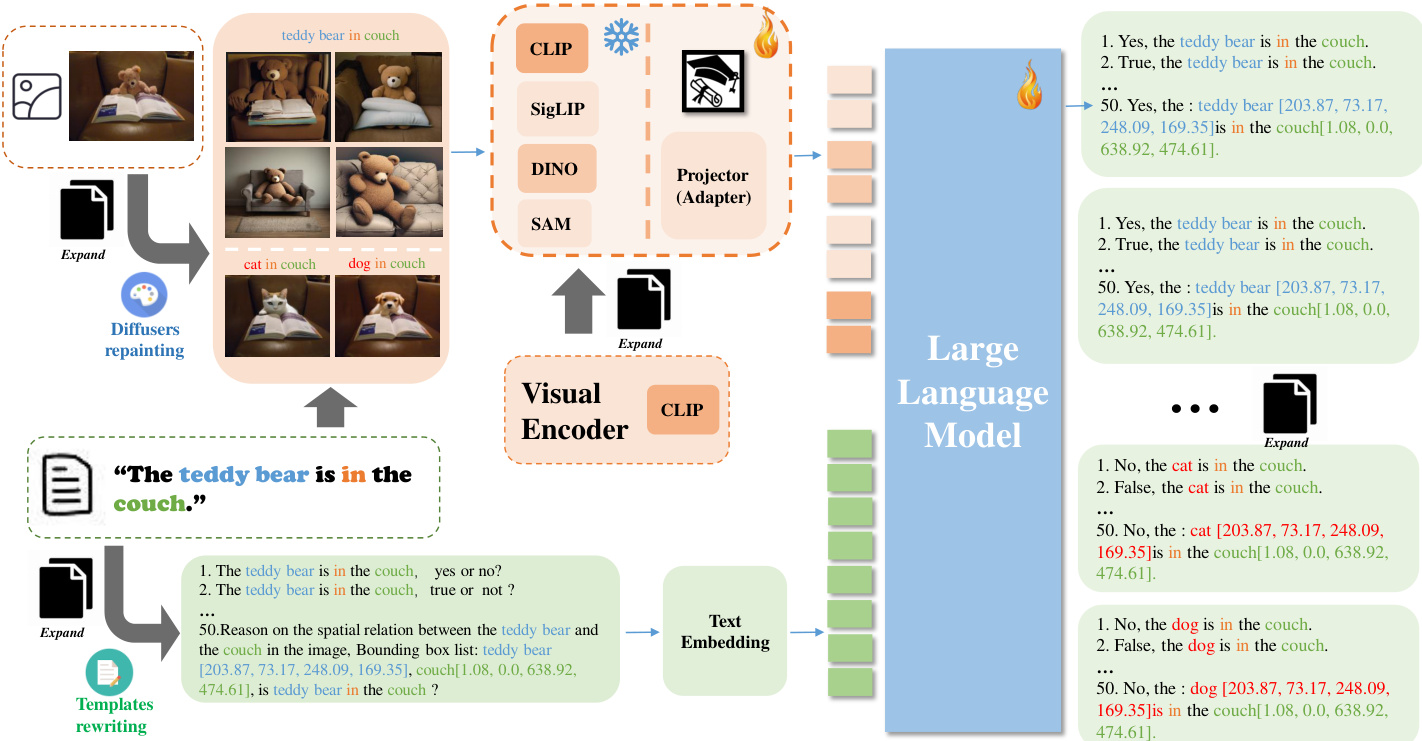
实验
初始的重新评估隔离了视觉语言模型中的性能不一致问题,揭示出文本过度敏感、视觉敏感度不足以及答案偏差严重阻碍了空间推理。后续实验验证了结合大量指令与视觉数据增强以及融合多骨干编码器架构的两阶段优化策略能有效解决这些缺陷。这些干预措施在定性上提升了模型在不同问题格式下的泛化能力,细化了细粒度空间特征的辨别力,并通过将注意力从文本共现转移至实际视觉位置关系,显著缓解了响应偏差。最终,该方法展现出稳健的跨基准泛化能力,证实了针对性的数据扩展与编码器整合成功突破了核心感知与推理局限。
作者通过扩展训练数据与结合多种视觉编码器,开展了提升视觉语言模型视觉空间推理能力的实验。结果表明,增加数据多样性并使用融合视觉编码器能够提升区分空间关系的能力,并降低对文本提示的敏感度。最终模型在不同问题类型上实现了更高的准确率与更均衡的响应。扩大训练数据规模提升了模型在空间推理任务中的表现。结合多种视觉编码器增强了模型感知空间细节的能力。最终模型降低了响应偏差,并在不同问题格式中展现出更均衡的准确率。
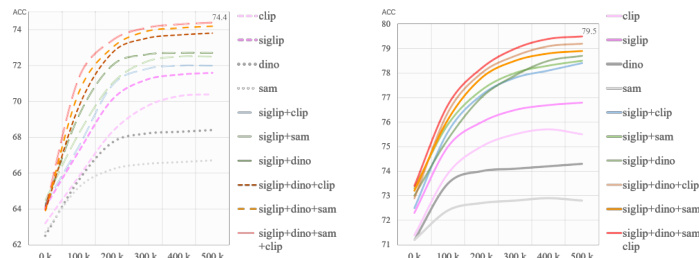
作者评估了各模型在空间推理任务上的性能,重点在于提升视觉敏感度与降低答案偏差。结果表明,与基线模型相比,所提模型在多个基准测试中实现了更高的准确率,表明其泛化能力得到改善,且对空间关系的辨别能力更强。所提模型在多个基准测试中优于基线模型,展现了增强的空间推理能力。该模型降低了答案偏差,在肯定与否定问题上的准确率差距更小。该模型表现出更好的视觉特征辨别力,空间关系类别的聚类更加明显。
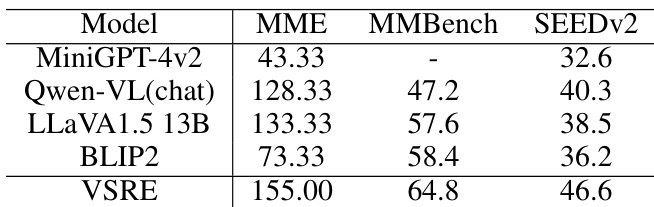
作者对比了基线模型与增强模型在空间推理任务上的性能,结果显示增强模型实现了显著更高的准确率,并能更好地区分不同的空间关系。结果表明视觉敏感度提升且答案偏差降低,在不同问题格式下的响应更加一致。与基线模型相比,增强模型展现出大幅更高的准确率与更优的空间关系辨别能力。增强模型降低了答案偏差,在肯定与否定问题上的表现更加均衡。增强模型表现出更强的视觉敏感度,不同空间关系的视觉特征分离更加清晰。
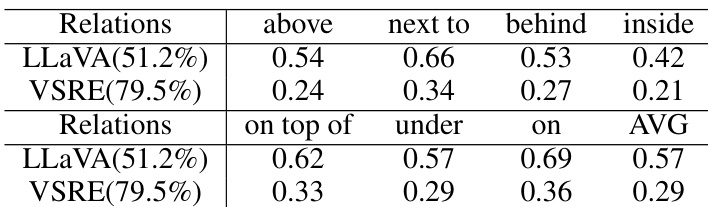
作者通过扩展数据规模与结合多种视觉编码器,开展了提升视觉语言模型视觉空间推理能力的实验。结果表明,增加训练数据量提升了通用任务与空间推理任务的性能,而结合多种视觉骨干网络增强了模型感知空间细节的能力。最终模型VSRE相比基线模型实现了更高的准确率与更优的泛化能力。扩大训练数据规模在通用任务与空间推理任务中均带来准确率的持续改善。结合多种视觉编码器提升了模型对视觉空间信息的敏感度。最终模型相比基线模型实现了更高的准确率并降低了响应偏差。
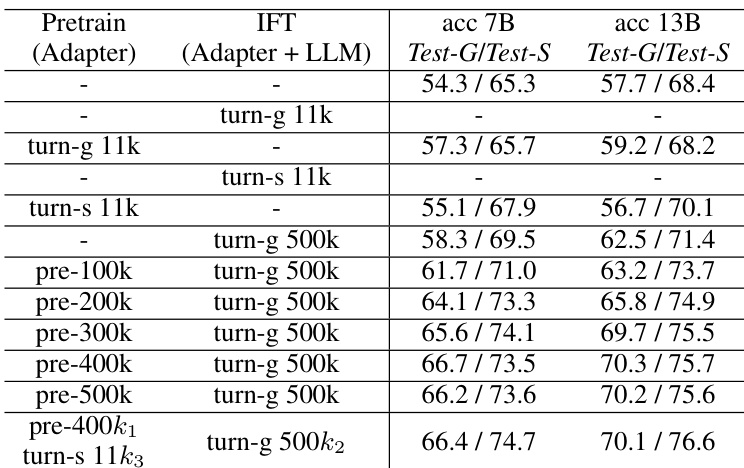
作者通过扩展训练数据与优化视觉编码器,开展了提升视觉语言模型视觉空间推理能力的实验。结果表明,增加数据多样性与结合多种视觉骨干网络显著提升了模型准确率与泛化能力,涵盖多种问题格式与基准测试。增强模型表现出对视觉位置信息更好的敏感度,并降低了响应偏差。扩大训练数据规模与多样性改善了模型在空间推理任务上的泛化能力与准确率。结合多种视觉编码器增强了模型感知细粒度空间细节的能力。优化后的模型降低了响应偏差,并能更好地区分视觉位置关系。
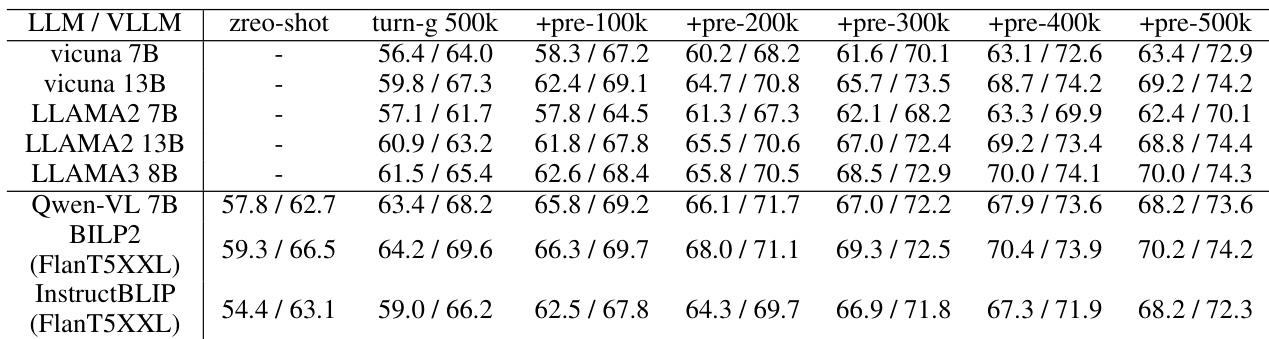
作者通过系统性地扩展训练数据与整合多种视觉编码器,评估视觉语言模型在空间推理任务上的表现。这些实验验证了扩展数据多样性能够持续增强模型泛化能力与空间感知能力,而结合视觉骨干网络显著提升了模型对细粒度位置细节的敏感度。最终,与基线方法相比,优化后的模型在多样化的基准测试与问题格式中展现出更优的准确率与显著降低的响应偏差。