Command Palette
Search for a command to run...
来自个性化生成的个性化表示
来自个性化生成的个性化表示
Shobhita Sundaram Julia Chae Yonglong Tian Sara Beery Phillip Isola
个性化推荐
摘要
现代视觉模型在通用下游任务中表现出色。然而,它们如何用于个性化视觉任务尚不清楚,这类任务既需要细粒度分析又面临数据稀缺的问题。近期的研究已成功将合成数据应用于通用表示学习,而文本到图像(T2I)扩散模型的进展使得仅凭少量真实样本即可生成个性化图像成为可能。在此,我们探讨了这些思想之间潜在的关联,并形式化了利用个性化合成数据学习个性化表示的挑战。这种表示编码了关于特定感兴趣对象的知识,并可灵活应用于任何与该目标对象相关的下游任务。为此挑战,我们引入了一套评估套件,包括对两个现有数据集的重构以及一个专门为此目的构建的新数据集,并提出了一种对比学习方法,创造性地利用了图像生成器。我们表明,我们的方法提升了多样化下游任务中的个性化表示学习效果,涵盖从识别到分割的任务,并分析了那些对这一提升至关重要的图像生成方法的特性。
一句话总结
本文提出一种对比学习框架,利用文本到图像扩散模型从少量真实样本生成个性化合成数据,通过包含重新划分及全新数据集的评估套件解决数据稀缺的视觉任务,并在识别与分割基准测试中展现出改进的个性化表示学习能力。
核心贡献
- 该研究形式化了从数据稀缺场景中学习个性化表示的挑战,并引入一个评估套件,包含全新的实例级数据集 PODS,以及针对两个现有基准测试的重新划分划分与标注。
- 对比学习框架通过对文本到图像扩散模型施加少量真实样本的条件约束,适配通用表示空间,实现无需外部真实负样本的合成数据生成。
- 在识别与分割任务上的实证评估展现出一致的性能提升,同时分析明确了关键图像生成特征,并评估了计算高效的多种方法合成替代方案。
引言
现代视觉模型在广泛识别任务中表现优异,但在细粒度个性化方面存在不足,后者需要从极少真实样本中学习实例专属表示。该能力至关重要,因为它支持私有化、本地化的模型训练,无需依赖集中式数据存储库或大量用户标注。先前方法通常依赖大规模标注数据集、要求外部数据共享,或将图像生成与表示学习视为相互割裂的流水线,难以适用于少样本场景。本研究利用文本到图像扩散模型,仅凭少量真实图像合成多样化的训练样本,并应用对比微调技术适配通用视觉骨干网络。该策略生成稳健的个性化表示,持续推动分类、检索、检测与分割任务的性能提升。为推动领域发展,研究团队同步发布专用评估套件及专为个性化表示学习基准测试设计的全新实例级数据集。
数据集
-
Dataset Composition and Sources
- 本文使用三个独立数据集评估个性化表示学习:DeepFashion2 (DF2)、DogFaceNet 以及新推出的 PODS(Personal Object Discrimination Suite)基准测试。
- DF2 提供聚焦于衬衫的大规模商业与消费级时尚图像,DogFaceNet 提供狗重识别视频素材,PODS 则包含使用 iPhone 15 Pro 与 PolyCam 应用拍摄的 100 种日常个人物品,涵盖五个类别(马克杯、螺丝刀、鞋子、包和水瓶)。
-
Key Details for Each Subset
- DeepFashion2: 在筛选出图库图像充足的类别后,从验证集中提取 169 个独立衬衫实例。最终子集包含 507 张训练图像与 1,271 张测试图像,严格规定每个实例分配 3 张训练图像及 4 至 24 张测试图像。
- DogFaceNet: 基于 DogFaceNet_large 划分,仅保留每个实例图像超过 10 张的类别。执行随机训练测试划分,人工检查所有序列以消除重叠视频导致的数据污染,并丢弃剩余测试图像少于 4 张的实例。清洗后的子集包含 80 只狗,生成 240 张训练图像与 1,218 张测试图像。
- PODS: 该自定义数据集包含 100 个物体(每类 20 个),在四个受控场景中录制:标准训练场景、高干扰场景、姿态变化场景及组合变化场景。每个物体从三个视角拍摄,共生成 300 张训练图像与 10,888 张测试图像,其中 1,200 张测试图像获得密集标注。
-
Data Usage and Training Configuration
- 将 3 张图像的训练划分视为对比微调的正样本,并将其与大量负样本池配对,以学习实例级表示。
- 在分类、检索、检测与分割任务上评估模型性能,刻意构建测试集以同时包含分布内与分布外场景,用于鲁棒性评估。
- 该数据支持标准 DreamBooth 微调与计算开销更低的替代方案(如 Cut-and-Paste 与 Masked DreamBooth)之间的对比实验,便于衡量真实数据与生成数据对表示质量的影响。
-
Annotation, Metadata, and Processing Strategies
- Metadata Construction: 每个物体分配唯一标识符,所有测试图像均进行分类与检索标注。利用大语言模型为每个物体生成 100 条实例专属提示词,将物体名称替换为
<new1>占位符以标准化训练输入。 - Mask Generation and Cropping: DF2 与 Dogs 数据集的分割掩码由人工标注。针对 PODS,使用 Grounding-SAM 生成初始掩码建议,并通过 TORAS 进行人工微调,随后直接从掩码中提取边界框。
- DreamBooth Processing: 为防止背景过拟合,在 DreamBooth 训练期间应用梯度掩码技术,将背景像素的梯度置零。同时实现自动过滤步骤,利用 DreamSim 与 perSAM 对掩码训练图像与生成图像进行嵌入。计算嵌入间的余弦相似度,并丢弃低于阈值(DF2 与 PODS 为 0.6,Dogs 为 0.55)的生成样本。
- Cut-and-Paste Synthesis: 在掩码可用时,提取前景物体并将其合成至大语言模型生成的背景上。移除背景提示词中的
<new1>占位符,将前景随机缩放至原始尺寸的 0.3 至 1.3 倍,并粘贴至随机坐标。
- Metadata Construction: 每个物体分配唯一标识符,所有测试图像均进行分类与检索标注。利用大语言模型为每个物体生成 100 条实例专属提示词,将物体名称替换为
方法
本文采用三阶段方法,利用生成模型实现个性化视觉表示。整体框架以目标实例 c 的少量真实图像集合 DR 及其关联的通用类别 cpr 为起点。目标是通过在预训练生成模型生成的合成数据上进行训练,适配通用视觉编码器 fϕ,从而为 c 生成个性化表示。
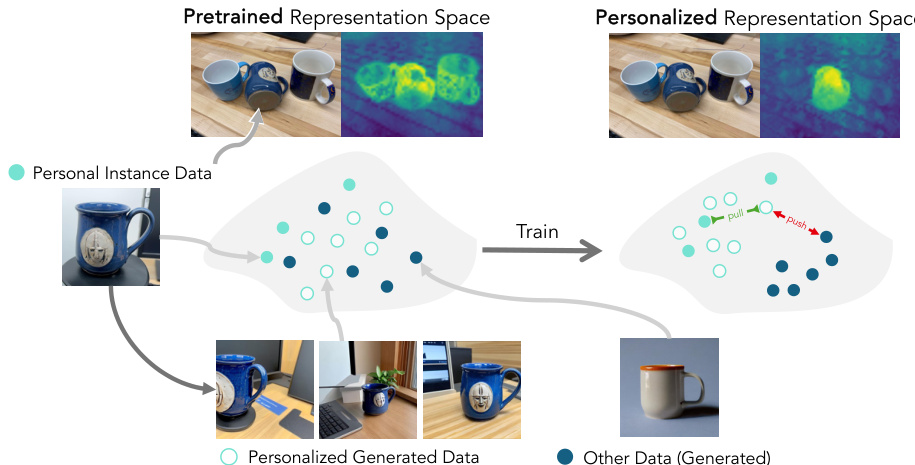
参考框架示意图,该图展示了从预训练表示空间向个性化空间的转换过程。流程始于个人实例数据,用于训练生成器。随后生成器输出个性化合成数据,用于训练表示模型。图中显示目标实例的真实图像输入系统,生成器学习生成该实例的新图像。个性化表示空间随后利用真实图像与生成图像进行训练,以区分目标实例与其他数据。
第一阶段中,以文本到图像(T2I)模型 Stable Diffusion 1.5 作为生成器 gθ,从 DR 生成个性化数据。利用 DreamBooth 适配 gθ,该技术在标识 token 条件约束下微调模型以生成 c 的新颖图像。T2I 扩散模型 gθ 在给定初始噪声潜变量 ϵ∼N(0,1) 与条件文本嵌入 y^=Γω(y) 的情况下生成图像,其中 Γω 为文本编码器,y 为用户提供的提示词。DreamBooth 使用包含真实图像 x 的重建损失与基于通用类别 cpr 条件的合成图像 xpr 的先验保持损失的损失函数对 gθ 进行微调。损失函数定义如下:
Ex,y^,ϵ,ϵ′,t[wt∣∣gθ(αtx+σtϵ,y^)−x∣∣22]+λwt′∣∣gθ(αt′xpr+σt′ϵ′,c^pr)−xpr∣∣22],其中 xpr 为使用预训练生成器在 cpr 条件下合成的图像,t 为时间步,变量 αt、σt 与 wt 关联噪声调度与采样质量。第一项为 x 的重建损失,第二项为 xpr 的先验保持损失,由 λ 加权。文本编码器 Γω 亦使用相同损失进行微调。
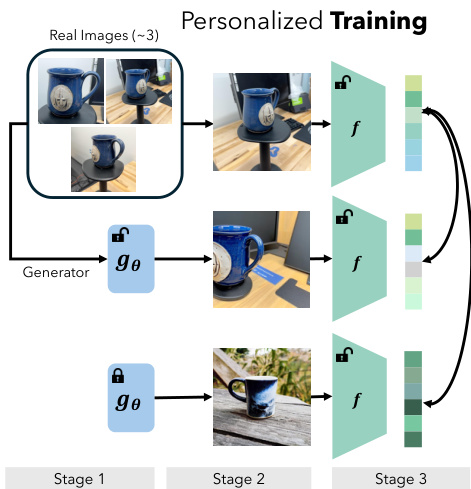
如图所示,个性化训练流水线包含三个阶段。阶段 1 针对目标实例的真实图像训练生成器 gθ。阶段 2 利用训练好的生成器合成数据。阶段 3 使用对比目标在生成的合成数据上微调视觉编码器 fϕ。
第二阶段中,利用训练好的生成器 gθ 生成合成数据 DS。生成数据用于训练个性化表示模型。通过无分类器引导(CFG)向生成输出注入多样性以控制生成数据集的属性,实验测试 CFG 值为 4.0、5.0 与 7.5。同时采用大语言模型生成的描述词为目标物体提供丰富的上下文信息,确保生成数据具备多样性与真实性。
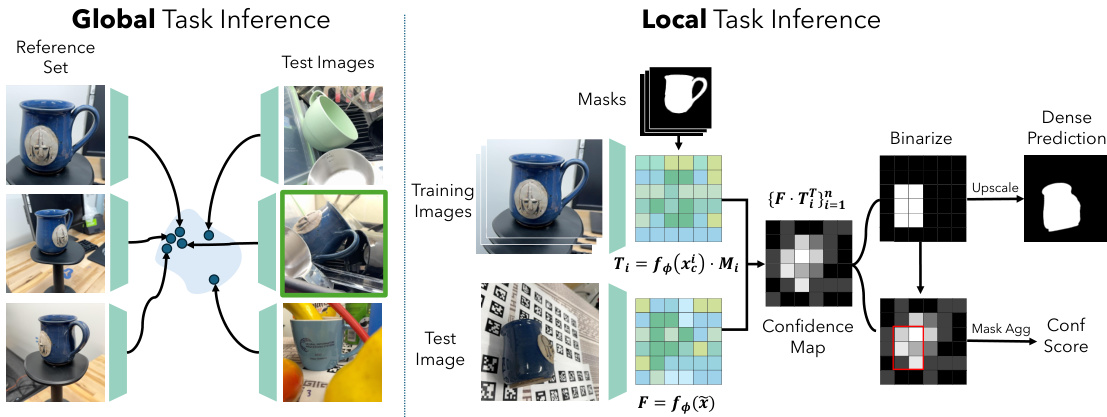
如图所示,展示了全局任务与局部任务的推理流水线。针对分类与检索等全局任务,模型使用 CLS 嵌入之间的余弦相似度。针对检测与分割等局部任务,模型提取具有空间信息的 patch 特征。图中显示训练图像用于生成特征图,随后进行处理以输出密集预测结果与置信度分数。
第三阶段中,使用对比目标在生成的合成数据上训练个性化表示。给定真实图像 DR 与合成数据 DS,通过向预训练生成器输入通用物体类别提示词“a photo of cpr”,从 DS 获取正样本,并生成负样本 D~S。从视觉编码器 fϕ 提取特征,将 CLS token 与平均池化后的最终层 patch 嵌入进行拼接。随后使用 infoNCE 损失对 fϕ 进行微调:
LInfoNCE=−log∑i=1Nexp(sim(x0,xi)/τ)exp(sim(x0,x+)/τ).该损失函数拉近 c 的真实图像与合成图像表示之间的距离,同时推远 c 与其他实例表示的距离。通过低秩自适应(LoRA)进行微调,其参数效率优于全量微调。实验采用多项前沿骨干网络,包括 DINOv2-ViT B/14、CLIP-ViT B/16 与 MAE-ViT B/16。各数据集随机划分为验证集与测试集,在验证集上遍历关键训练参数以确定最优配置。基于验证实验结果,使用 infoNCE 损失进行 2 个 epoch 的 LoRA 微调,共处理 4500 个 anchor-positive 对,其中包含 450 个合成正样本与 1000 个合成负样本。
实验
实验在分类、检索、分割与检测任务上,评估基于少量真实样本并结合合成数据增强的个性化视觉表示与标准预训练模型的性能差异。结果表明,个性化处理持续增强全局语义理解与精确物体定位能力,结合式合成生成策略通过平衡视觉保真度与姿态多样性被证明最为有效。尽管不同数据生成技术引入不同的归纳偏置(例如 DreamBooth 在姿态泛化方面的优势与 Cut-and-Paste 在物体保真度方面的严格性),研究结果证实精心筛选的合成数据增强显著提升表示质量。此外,这些个性化特征无缝集成至下游流水线,并在真实训练数据规模扩大时保持稳健性能,凸显合成数据在少样本个性化中的长期实用价值。
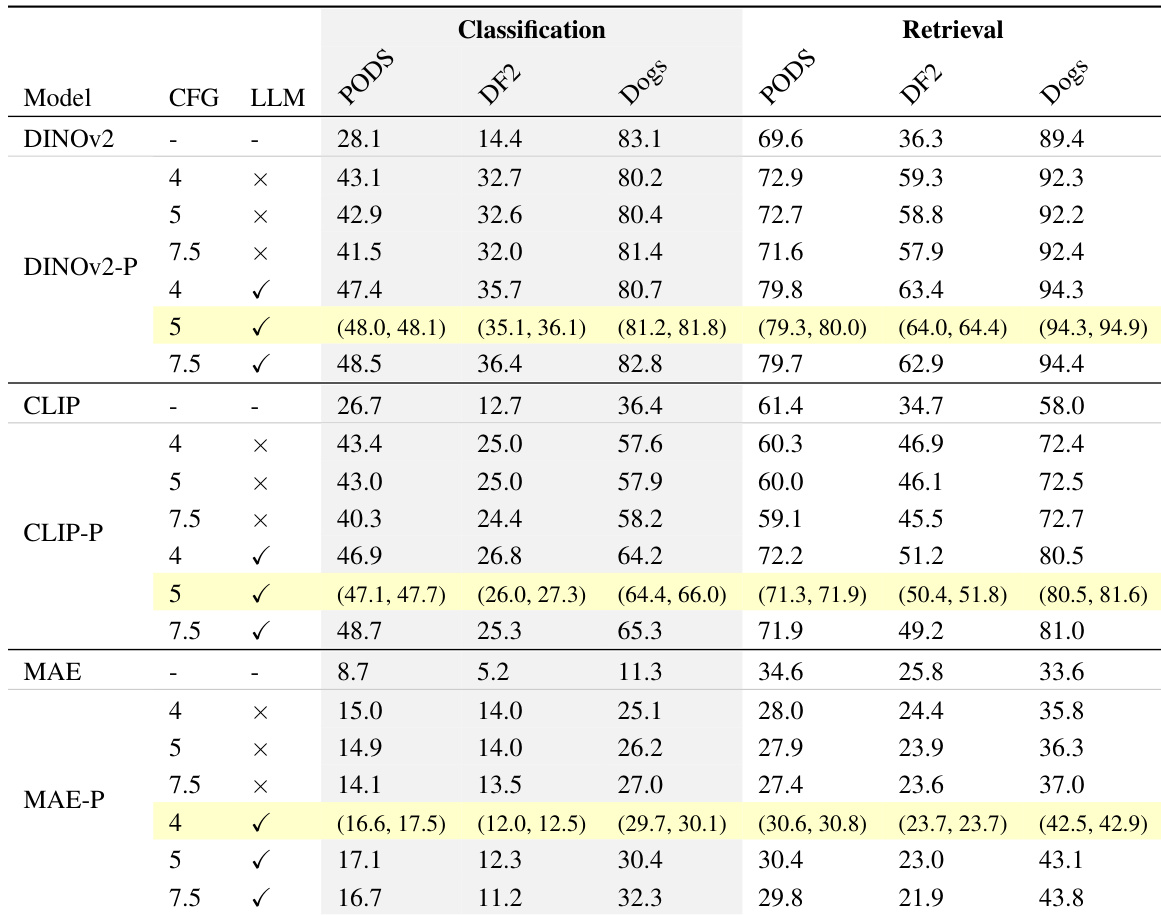
研究在多骨干网络与多任务上评估使用合成数据训练的个性化表示与预训练模型的性能,发现个性化模型在分类与检索任务中持续优于预训练模型。DINOv2 与 CLIP 的性能提升尤为显著,不同数据集与任务均观察到改进,尽管 MAE 的提升幅度相对较小。使用特定配置生成的合成数据(如较高 CFG 值与大语言模型生成的提示词)取得最佳结果,此类配置有效增强表示质量。针对 DINOv2 与 CLIP 骨干网络,个性化表示在分类与检索任务中持续超越预训练模型。采用较高 CFG 值与大语言模型提示词生成的合成数据在分类与检索任务中表现更佳。基于 MAE 的个性化表示改进幅度小于 DINOv2 与 CLIP,表明不同骨干网络的有效性存在差异。
评估个性化表示的不同损失函数,将 InfoNCE、含多正样本的 InfoNCE、Hinge 与交叉熵损失与基线进行对比。结果表明,InfoNCE 在分类与检索任务中均持续优于其他损失函数,分类与检索任务的最佳性能均由 InfoNCE 实现。个性化模型(DINOv2-P)相较于预训练基线显著提升检索性能,而分类性能在不同损失函数间波动较大。InfoNCE 在分类与检索任务中均取得最高性能。DINOv2-P 在检索任务中超越预训练 DINOv2 基线,提升幅度显著。分类性能因损失函数不同呈现较大差异,InfoNCE 表现最优。

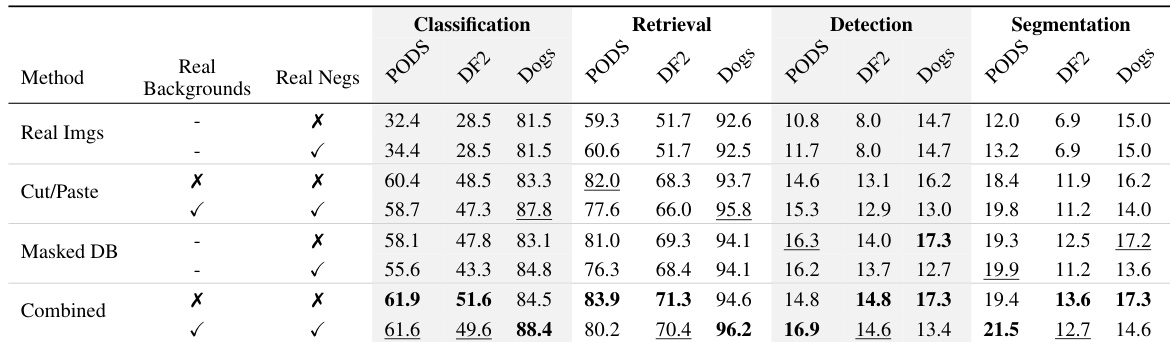
对比生成合成数据以个性化视觉模型的不同方法,评估其在分类、检索、检测与分割任务上的表现。结果表明,结合多种数据增强策略取得最佳整体性能,相较于仅使用真实图像或单一增强方法,多数任务与数据集均获得提升。多种数据增强方法的组合在所有任务与数据集上实现最高性能。使用包含真实背景与负样本的合成数据在多数任务中显著优于仅使用真实图像。不同增强方法展现差异化优势,部分方法在分类任务中表现突出,另一些则在密集预测任务中更具优势。
对比训练个性化表示时不同合成数据生成方法的运行时效率。结果表明,使用真实背景的 Cut/Paste 方法速度最快,生成耗时极短,而 DreamBooth 方法耗时显著更长,尤其在应用过滤机制时。DreamBooth 结合过滤机制的总运行时间大幅延长,主要归因于耗时的生成流程。使用真实背景的 Cut/Paste 为最快方案,生成时间可忽略不计。DreamBooth 方法耗时显著增加,过滤步骤进一步拉长生成周期。DreamBooth 结合过滤机制的总运行时间因漫长的生成过程而大幅提高。

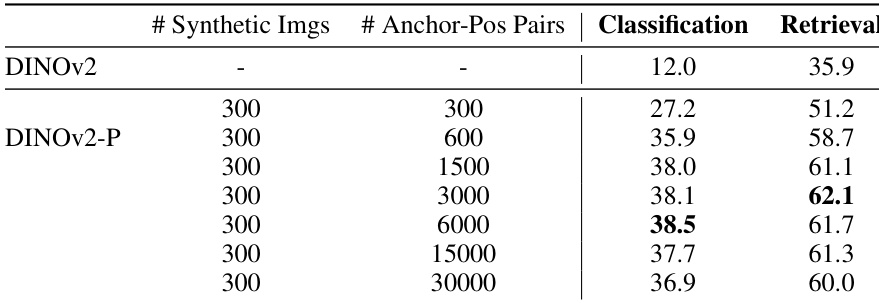
对比个性化表示与预训练模型在分类与检索任务上的性能,测试不同数量的合成图像与 anchor-positive 对。结果表明,个性化模型整体表现优于预训练模型,全局任务与密集任务均观察到性能提升。将大量 anchor-positive 对与固定数量合成图像相结合时取得最佳性能。个性化模型在分类与检索任务中持续领先预训练模型。增加 anchor-positive 对数量可提升性能,较高比例下取得最优结果。不同数据集与任务中的性能提升保持一致,表明该个性化方法具备良好鲁棒性。
实验评估基于合成数据训练的个性化视觉表示与预训练基线的性能差异,验证骨干网络架构、损失函数、生成策略、训练数据比例及计算效率对分类、检索、检测与分割任务的影响。结果一致表明个性化模型优于预训练模型,DINOv2 与 CLIP 从使用高 CFG 值、大语言模型提示词及组合增强策略生成的合成数据中获益最多。分析进一步揭示 InfoNCE 损失函数产出最强的表示质量,提高 anchor-positive 对比例可增强跨多样化数据集的性能与鲁棒性。尽管 Cut/Paste 等生成方法在运行时效率上优于 DreamBooth 等高计算开销方案,整体结论确立精心构建的合成数据显著提升模型个性化能力与泛化性能。