Command Palette
Search for a command to run...
Phi-4 技术报告
Phi-4 技术报告
一键部署 Phi-4
摘要
我们介绍了 phi-4,这是一个拥有 140 亿参数的语言模型,其训练方法以数据质量为核心。与大多数主要基于网页内容或代码等自然数据源进行预训练的语言模型不同,phi-4 在训练过程中战略性地融入了合成数据。Phi 系列之前的模型主要通过知识蒸馏获取教师模型(具体为 GPT-4)的能力,而 phi-4 在面向 STEM 领域的问答能力上大幅超越了其教师模型,这表明我们的数据生成和后训练技术超越了单纯的知识蒸馏。尽管对 phi-3 架构的改动极小,但得益于更优的数据、训练课程以及后训练方案的创新,phi-4 在其规模下实现了强劲的性能表现——尤其在以推理为主的基准测试中。
一句话总结
Phi-4 是一款拥有 140 亿参数的大型语言模型,通过战略性地整合合成数据、优化训练课程以及引入新颖的后训练创新,优先保障数据质量,从而在专注于推理的基准测试中实现卓越性能。该模型在面向 STEM 的问答任务上大幅超越 GPT-4,并证明了这些技术的作用超越了传统的教师模型蒸馏。
核心贡献
- 本文提出 phi-4,一款 140 亿参数的大型语言模型,通过在训练全过程中战略性地整合合成数据,突破传统有机数据源与标准蒸馏流程的局限。
- 开发了一套优化的后训练流程,构建更高质量的监督微调数据集,并实施基于关键 token 搜索的直接偏好优化技术。
- 该模型展现出强大的推理与 STEM 问答能力,性能匹配甚至超越参数量大得多的架构,在 GPQA 和 MATH 基准测试中显著超越 GPT-4o,并在多项推理评估中优于 Llama-3.1-405B。
引言
大型语言模型传统上优先依赖算力扩展与海量有机数据集,但新兴证据表明,数据质量是提升推理能力更高效的核心驱动力。以往模型通常依赖未筛选的网页文本或从更大规模教师模型中蒸馏知识,这限制了其在复杂问题解决上的深度,且常导致事实性不一致。作者利用 140 亿参数架构推出 phi-4,从根本上将训练范式转向精心策划的合成数据生成、优化训练课程与先进的后训练优化。这种以数据为中心的方法使模型能够在无需修改架构的情况下,匹配或超越规模大得多的竞争对手,并在严格的 STEM 基准测试中超越其 GPT-4 教师模型。
数据集
- 数据集构成与来源
- 作者将高度筛选的有机语料库与大量生成的合成数据集相结合,构成核心预训练语料。
- 有机数据来源涵盖过滤后的网页转储、学术存储库(arXiv、PubMed Central)、代码平台(GitHub)、教育论坛、授权书籍以及涵盖 176 种语言的多语言档案(CommonCrawl、Wikipedia)。
- 合成数据包含约 4000 亿 token,涵盖五十个独立类别,专门设计用于覆盖多样化的推理任务、代码生成与学术解题。
- 后训练数据集包括监督微调提示词以及源自拒绝采样与大语言模型评估的直接偏好优化对。
- 各子集关键细节
- 过滤网页数据:最大规模集群,包含约 1.3 万亿唯一 token,划分为重推理与高密度知识两部分。质量通过基于 LLM 生成标注训练的小型分类器进行控制,并采用专用流程平衡 STEM 与非 STEM 内容。
- 合成数据:基于高质量种子生成,采用多阶段提示、自我修订反馈循环与指令反转技术。作者优先保障多样性、细微复杂性、事实准确性与显式思维链推理。
- 网页重写:约 2900 亿 token,通过将过滤后的有机段落转化为结构化练习、讨论与推理任务生成。
- 代码数据:约 8200 亿唯一 token,结合原始与合成来源。所有代码均通过执行循环与自动化测试进行验证,以确保正确性。
- 问答与学术数据:收集并过滤数千万道有机题目,使用多数投票法平衡难度。不准确的答案被合成生成的替代答案替换,整个数据集经过严格的去污染处理。
- 长上下文数据:专为中期训练设计的子集,包含长度超过 8K 与 16K token 的样本,专门提高权重以改善长序列处理能力。
- 数据使用与混合比例
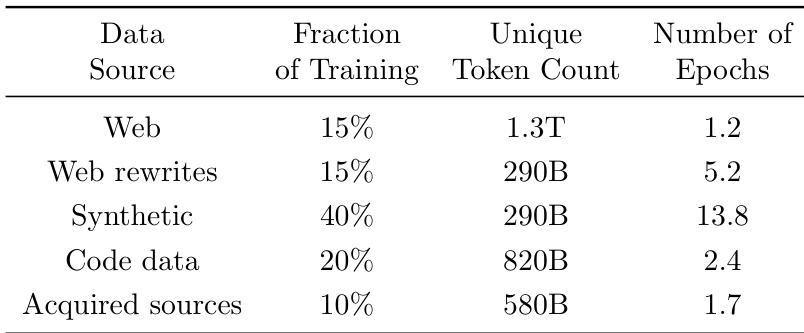
- 预训练阶段将 40% 的 token 分配给合成数据,30% 分配给网页与网页重写(各半),20% 分配给代码,10% 分配给学术文献与书籍等定向获取数据。
- 作者通过消融实验优化这些比例,发现高比例合成数据分配有助于提升推理能力,而定向有机数据对知识保持与减少幻觉至关重要。
- 中期训练将上下文窗口从 4K 扩展至 16K token。混合比例调整为 30% 新策划的长上下文数据与 70% 预训练召回数据,在降低学习率与调整 RoPE 频率的情况下,使用 2500 亿 token 进行训练。
- 后训练使用 SFT 数据进行回复生成,并采用两阶段 DPO 流程进行对齐。DPO 流程整合关键 token 对与裁判引导优化,预留 1% 至 5% 的数据用于安全与拒绝训练。
- 处理、元数据与裁剪策略
- 作者采用自定义提取流程解析多样化文件格式,同时通过 DOM 树规范化保留 MathML 公式、语法高亮代码与论坛线程结构等脆弱元素。
- 合成种子标注了丰富的元数据,包括复杂度等级、事实冷门度评分、推理链、逐步逻辑依赖关系与信息类型分类。
- 高级生成技术包括中间填空练习,即移除有意义的文本片段以创建上下文与答案对,以及多轮对话合成,通过自我批评迭代优化对话。
- 去污染依赖混合 n-gram 算法,使用 13-gram 与 7-gram 特征与标准基准进行匹配,并明确将常见短语列入白名单以防止过度过滤。
- 质量保证通过基于执行的代码验证、答案一致性的多数投票以及数据进入训练循环前的基于评分标准的模型自我修订来强制执行。
方法
phi-4 模型基于仅解码器 Transformer 架构构建,设计与 phi-3-medium 高度相似,但包含多项关键增强。该模型拥有 140 亿参数,默认上下文长度为 4096,在中期训练期间扩展至 16K 以支持更长序列。模型采用 tiktoken 分词器,实现更优的多语言处理能力,并使用填充后的词表大小 100,352,包含未使用的 token。与在 2K 上下文上使用滑动窗口注意力机制的 phi-3-medium 不同,phi-4 在预训练期间对完整 4K 上下文使用全注意力机制,从而更有效地建模长距离依赖关系。

预训练在约 10 万亿 token 上进行,采用线性预热与衰减的学习率调度策略,峰值学习率为 0.0003,权重衰减恒定为 0.1,全局批处理大小为 5760。超参数通过较短训练运行的插值进行优化,并通过预热阶段的压力测试进行验证,以确保稳定性。预训练结束后,应用中期训练阶段将上下文长度从 4K 扩展至 16K,使模型能够有效处理更长输入。
为在预训练期间评估模型,采用自定义基准测试框架,结合对多种任务的对数似然评估与少样本提示。其中包括 MMLU(5-shot)、MMLU-pro 与 ARCC(1-shot)的对数似然评估,以及使用 1、3、4 与 8 个示例对 TriviaQA(TQA)、MBPP、MATH 与 GSM8k 进行的少样本评估。这些评估旨在确保模型遵循预期的答案格式,便于后续提取解决方案。
后训练旨在将预训练模型转化为安全且能力出众的 AI 助手。该流程包含一轮监督微调(SFT),随后进行两轮直接偏好优化(DPO)。首轮 DPO 使用基于关键 token 搜索(PTS)方法生成的数据,第二轮则在完整长度偏好对上应用 DPO。模型使用标准 chatml 格式进行微调,该格式通过系统、用户与助手消息结构化对话,实现连贯且具备上下文感知能力的交互。

关键 token 搜索(PTS)是偏好数据生成流程中的核心创新。它识别响应序列中显著影响正确概率的关键 token。对于给定提示 Q 与补全 Tfull=t1,t2,…,PTS 通过从 Q+t1,…,ti 采样补全来估计成功条件概率 p(success∣t1,…,ti)。该算法递归细分序列,直至成功概率变化低于阈值 pgap 或仅剩单个 token。导致成功概率急剧变化的 token 被视为关键 token,并用于构建偏好对,其中接受与拒绝的补全分别为分别提升与降低成功概率的单个 token tacc 与 trej。
PTS 应用于具备真实值验证的任务,如数学、问答与编程,并进行过滤以仅保留满足 0.2≤p(success)≤0.8 的题目,因为极端简单或困难的案例中关键 token 极为罕见。该方法确保 DPO 优化聚焦于高影响 token,通过避免被低显著性 token 的噪声稀释来改善模型行为。图 5 展示了通过 PTS 生成的偏好数据,其中关键 token 以下划线标出,凸显其在决定解决方案正确性方面的关键作用。
后训练框架还整合了幻觉缓解策略。SFT 数据与 DPO 对的构建旨在鼓励模型在不确定时拒绝回答,而非生成虚构内容。该方法显著降低了幻觉,如图 6 所示,后训练期间 SimpleQA 问题的尝试频率持续下降。
安全性对齐通过引入有用性与无害性偏好数据集进一步增强,这些数据集改编自先前工作并辅以内部生成数据。这确保模型在多个危害类别中遵循负责任的 AI 原则。此外,训练数据包含来自 AgentKit 的轨迹,这些轨迹记录了详细的思维链推理,提升了规划、推理、工具使用与错误纠正能力。这些轨迹被重写为自包含的思考过程,以保留推理本质,使模型能够展现出结构化与反思性的问题解决行为。
实验
评估框架整合了去污染的内部基准、全新数学竞赛与独立安全红队测试,以验证模型的推理能力、计算效率与对齐水平。在未见过竞赛数据与防污染数据集上的测试证实,模型在 STEM 与编程方面的卓越性能反映了真实的泛化能力而非基准泄露,而对比分析则证明了其在长思维链替代方案上更优的推理效率。尽管在严格遵循指令方面仍存在微小局限,但针对性的后训练策略成功提升了推理质量与对抗防御能力,确立了该模型作为高度能力出众且资源高效的基础模型地位。
作者分析了不同后训练组件对模型在各基准上性能的影响,表明结合关键 token DPO 与裁判引导 DPO 能够提升重推理任务的表现。结果表明,S + WR 配置取得最高平均分,而 Uniform 基线在大多数指标上表现最差。S + W 配置结果呈现混合状态,在特定领域有所提升,但整体性能低于 S + WR。结合关键 token DPO 与裁判引导 DPO 在推理基准上实现最佳整体表现。S + WR 配置在所有评估基准上取得最高平均分。Uniform 基线在大多数指标上表现最差,凸显了后训练技术的重要性。

作者分析了合成数据与网页重写对模型在多基准上性能的影响。结果表明,在合成数据中增加网页重写使大多数基准的性能得到提升,在 Human-Eval 与 MBPP 上增益显著,而 TQA 与 MMLU 等部分指标出现轻微下降。提升效果在不同评估领域保持一致,表明该数据策略的有效性。结合使用网页重写与合成数据改善了大多数基准的性能,尤其在 Human-Eval 与 MBPP 上表现突出。模型在使用组合数据时跨评估领域展现一致增益,表明改进具有稳健性。尽管多数指标得到改善,但添加网页重写导致 TQA 与 MMLU 等部分基准出现轻微下降。
作者对 phi-4 进行评估,并将其性能与其他多款模型在多基准上进行对比,表明 phi-4 在各类任务中均取得优异表现,尤其在推理与 STEM 相关评估中。模型性能在不同输入长度下保持一致,在部分基准上随最大长度增加而提升,表明对输入尺寸具有良好的鲁棒性。结果表明,phi-4 在大多数类别中超越同类模型,在推理与编程任务中优势显著。phi-4 在多个基准上达到顶尖水平,在大多数类别中超越 Qwen-2.5-14B 与 Llama-3.3-70B 等模型。模型在不同输入长度下表现稳定,当最大长度提升至 16K 时部分指标进一步改善。phi-4 展现出强大的推理能力,尤其在 STEM 与编程任务中,在关键领域超越更大规模模型。
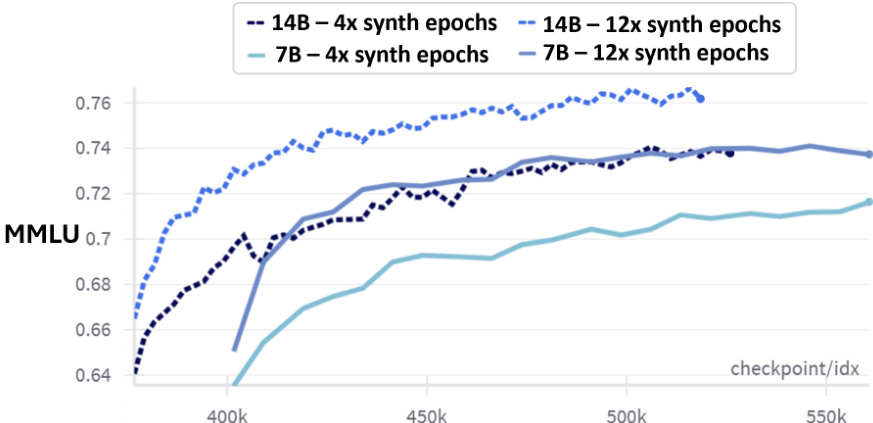
作者描述了涉及多数据源的训练流程,其中合成数据贡献了最大比例的 training token。训练策略针对不同数据类型设置不同的训练轮数,合成数据经历最密集的训练。网页相关数据源采用中等轮数训练,而代码与获取数据训练轮数较少。合成数据构成训练数据最大部分,并经历最多训练轮数。网页相关数据源采用中等轮数训练,代码与获取数据训练轮数较少。训练流程使用多样化数据源,各源包含不同的训练 token 比例与轮数。
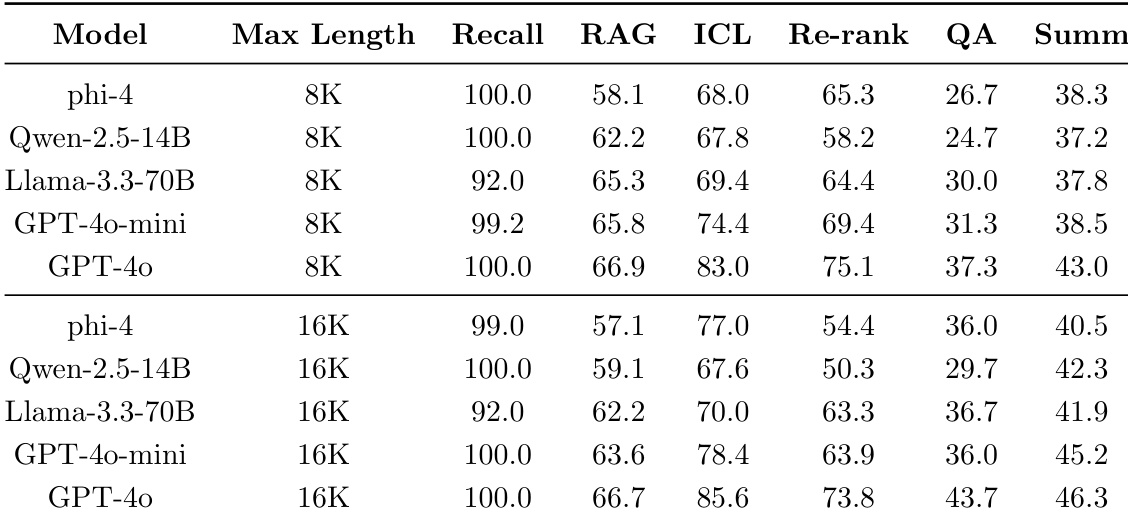
作者展示了 phi-4 的基准测试结果,对比不同模型规模与评估任务的表现。结果表明,16K 版本的 phi-4 在大多数基准上超越 4K 版本,在推理与 STEM 任务中提升显著,而两个版本在指令遵循与特定问答任务上均显现相对短板。性能提升归因于后训练技术,包括关键 token DPO 与裁判引导 DPO,这些技术在重推理基准上尤为有效。16K 版本 phi-4 在大多数基准上持续超越 4K 版本,尤其在推理与 STEM 任务中。关键 token DPO 与裁判引导 DPO 是有效的后训练方法,在不同类型基准上具备互补优势。phi-4 在推理与 STEM 任务中表现强劲,在部分基准上超越更大模型,但在指令遵循与特定问答基准上表现相对较弱。

评估设置涵盖多种推理、STEM、编程与指令遵循基准,以检验数据构成、训练时长与对齐技术如何影响模型能力。每项实验均验证了结合关键 token 与裁判引导 DPO,并辅以优先保障合成内容与网页重写的数据策略,能够显著强化推理与编程性能。尽管这些配置带来了稳健的跨领域提升,但也揭示了在特定问答与指令遵循任务中的微小权衡。总体而言,结果证实了针对性的后训练对齐与战略性加权的多元训练混合是驱动模型高级推理能力的关键因素。