Command Palette
Search for a command to run...
文本预处理流程如何影响本体匹配?
文本预处理流程如何影响本体匹配?
Zhangcheng Qiang Kerry Taylor Weiqing Wang
一键部署文本预处理入门教程
摘要
由分词(Tokenisation)、规范化(Normalisation)、停用词去除(Stop Words Removal)以及词干提取/词形还原(Stemming/Lemmatisation)组成的经典文本预处理流程已在许多本体匹配(OM)系统中得到应用。然而,文本预处理缺乏标准化导致了映射结果的多样性。在本文中,我们调查了文本预处理流程对8个本体对齐评估倡议(OAEI)赛道及其49种不同对齐结果的影响。我们发现,分词和规范化(归类为第一阶段文本预处理)比停用词去除和词干提取/词形还原(归类为第二阶段文本预处理)更为有效。我们提出了两种新颖的方法来修复在第二阶段文本预处理中产生的不良错误映射。第一种是事前基于逻辑的修复方法,用于文本预处理之前,通过采用特定于本体的检查来找出导致错误映射的常见词汇。第二种修复方法是事后基于大语言模型(LLM)的方法,用于文本预处理之后,利用LLM提供的强大背景知识来修复不存在且违反直觉的错误映射。实验结果表明,这两种方法可以显著提高匹配的准确性和整体匹配性能。
一句话总结
针对 Ontology Alignment Evaluation Initiative (OAEI) 的八个评估轨道及 49 组独立映射展开调查,本文证明在本体匹配任务中,第一阶段预处理步骤(分词与规范化)的表现优于第二阶段步骤(停用词移除与词干提取/词形还原)。同时提出两种针对性修复策略以缓解第二阶段产生的错误映射:一种是在预处理前识别问题常见词的事前逻辑方法,另一种是利用外部知识纠正错误对齐的事后大型语言模型方法,从而显著提升匹配准确率与整体性能。
核心贡献
- 本文系统评估了涵盖 49 组独立映射的八个 OAEI 轨道上的经典文本预处理流水线,证明第一阶段操作(分词与规范化)产生的对齐质量高于第二阶段操作(停用词移除与词干提取/词形还原)。
- 引入两种新型修复方法以消除第二阶段预处理生成的错误映射,包含一个在预处理前过滤本体特定问题术语的事前逻辑模块,以及一个利用外部知识纠正不存在或违背直觉对齐的事后大型语言模型模块。
- 实验验证表明,与标准预处理工作流相比,集成这些修复机制能显著提升匹配准确率及整体本体对齐性能。
引言
本体匹配通过对齐不同本体中的概念,实现异构知识图谱间的互操作性,而文本预处理为该任务提供了计算高效的底层基础。然而,先前对经典预处理流水线的实现缺乏标准化,系统性研究表明,由于过度处理与不当过滤,停用词移除以及词干提取或词形还原频繁引入错误映射。研究利用跨多个本体对齐基准的综合评估,证明流水线早期阶段的表现始终优于后期阶段。为弥补这些缺陷,工作流引入一种事前逻辑验证步骤,在预处理前过滤问题术语,并采用一种事后大型语言模型方法,在预处理后纠正错误对齐。这两种方法结合使用,在弥合传统词汇技术与现代推理能力之间架起桥梁的同时,显著提升了匹配准确率。
数据集
- 数据集构成与来源: 研究使用来自 MELT 仓库中 8 个 OAEI 轨道的 49 组独立本体对齐基准。实体对源自本体的类与属性,非文本标识符由标注标签替代。
- 子集详情与过滤: 数据集仅聚焦于类与属性的等价映射,因真实标签有限而有意排除子集映射。包含超过 15 个复合词的实体将被过滤,以维持数据集平衡。
- 数据用途与评估: 研究未使用数据训练模型,而是将其作为静态基准以测试文本预处理流水线。对齐生成依赖确定性规则,即对预处理后的实体字符串进行精确相等比对。性能通过精确率、召回率与 F1 分数,与专家验证的参考对齐结果进行对比评估。因本体匹配中负样本空间极其庞大,刻意省略了准确率与特异度指标。
- 处理与元数据构建: 每个实体均经历标准化预处理流水线,包含全词分词、规范化、停用词移除以及词干提取或词形还原。分词步骤保留复合词的精确顺序以确保公平对比。规范化操作执行小写转换、HTML 标签移除与标点处理,同时避免使用改变语义的过滤器。停用词采用标准 NLTK 英文列表,词干提取与词形还原实验则测试 Porter、Snowball、Lancaster 及基于 WordNet 的方法,并支持可选的词性标注。
方法
研究采用基于上下文的流水线修复方法,以解决文本预处理方法在本体匹配任务中引发的假阳性问题。整体框架包含一个两阶段文本预处理流水线,其中第一阶段方法使对齐结果向参考结果靠拢,增加真阳性数量并减少假阳性。然而,第二阶段方法会扩展对齐范围,同时增加真阳性与假阳性数量。所提出的修复策略旨在使对齐结果向参考结果收缩,在仅轻微减少真阳性的情况下大幅降低假阳性。 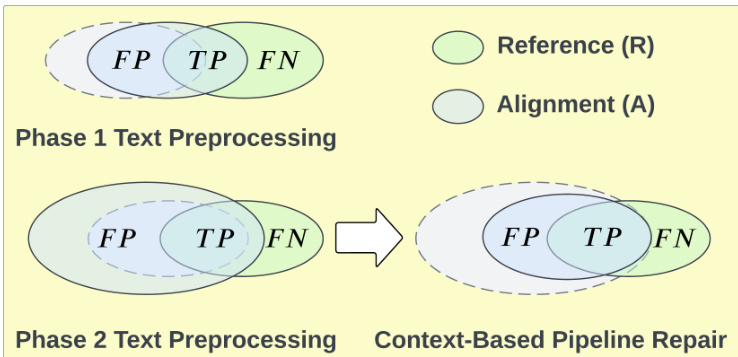
该方法的核心在于应用于文本预处理之前的事前逻辑修复。此方法构建保留词集,防止特定术语进入文本预处理流水线,从而保留原本可能被混淆的实体间的差异。保留词的选择基于两项本体特征:单一本体内实体名称的唯一性,以及表征相同领域的本体倾向于使用相似术语的规律。如图 1 所示,算法 1 用于生成该词集。该算法首先识别源本体与目标本体中在给定文本预处理函数 f(·) 下产生相同输出的实体对。针对每对实体,将其字符串表示中的非共有词加入保留集。随后,算法会从保留集中移除预处理函数下不可变的词(即满足 f(w) = w 的词),因为这些词不会影响映射结果。 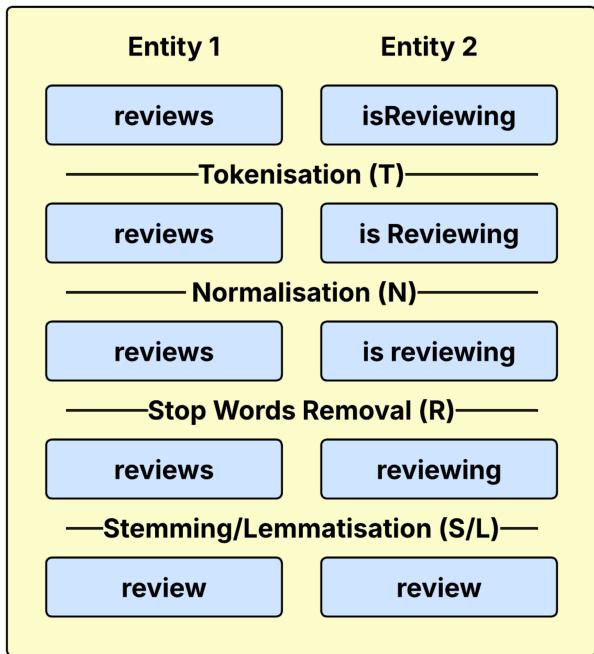
整体匹配过程的框架如图 2 所示。流程首先从源本体与目标本体中检索实体。这些实体依次经历分词(T)、规范化(N)、停用词移除(R)以及词干提取或词形还原(S/L)等文本预处理步骤。处理后的实体用于计算对齐结果(A),并与参考结果(R)进行比对以评估匹配性能。基于上下文的流水线修复机制被集成至该流程中,具体表现为在预处理阶段应用保留词集,在生成对齐前修改实体的文本表示。 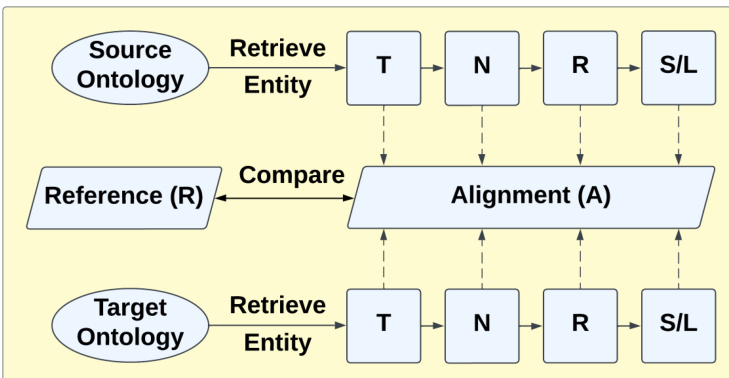
该修复方法的有效性通过韦恩图得到验证,图中展示了比对结果与参考结果集中假阳性、真阳性与假阴性之间的关系。图示清晰表明,流水线修复在维持真阳性区域的同时压缩假阳性区域,从而提升整体对齐质量。该过程被可视化为由同时增加真阳性与假阳性的第一、二阶段文本预处理,向专门针对并降低假阳性的基于上下文的流水线修复的演进。 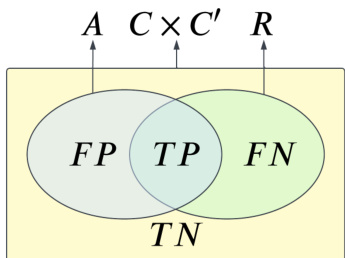
实验
本研究在多个基准轨道上评估了综合本体匹配流水线,系统分析文本预处理步骤的连续影响,并测试不同提示策略下的大规模语言模型。实验验证了初始的分词与规范化操作通过保留语义含义持续提升匹配准确率,而后续的停用词移除与词干提取技术则意外增加假阳性并降低整体性能。为克服这些局限,研究引入并验证了两种针对性修复方法,将用于真匹配检测的确定性预处理与基于大型语言模型的验证相结合,以过滤错误对齐。最终结果表明,将经典预处理与结构化大型语言模型修正相融合,能显著提升精确率与系统鲁棒性,建立比纯提示驱动方法更可靠的工作流。
研究对比了不同大型语言模型与提示策略在本体匹配任务中检测错误映射(假阳性)的性能。结果表明,通过 API 调用的商业模型在假阳性发现率上普遍优于开源模型,且更复杂的提示策略并未始终提升性能。经典文本预处理流水线在不同模型与提示下均能保持高且稳定的假阳性发现率。API 调用的商业模型在错误映射发现率上高于开源模型。复杂提示策略并未始终提升错误映射检测性能。经典文本预处理流水线在不同大型语言模型与提示下为错误映射提供稳定且较高的发现率。
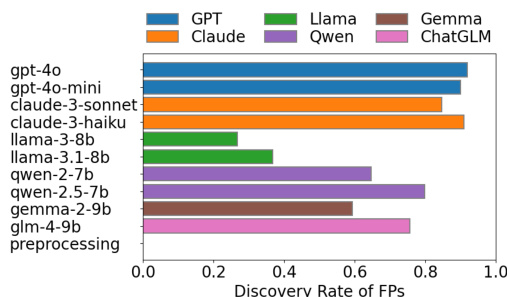
研究对比了不同大型语言模型与经典文本预处理流水线的假阳性发现率。结果表明,通过 API 调用的商业模型在假阳性发现率上优于开源模型,且更复杂的提示策略并未始终提升性能。经典文本预处理流水线能实现高且稳定的发现率,与表现最佳的模型相当。商业模型在假阳性发现率上高于开源模型。复杂提示策略并未始终提升假阳性发现率。经典文本预处理流水线为假阳性提供高且稳定的发现率,与顶尖模型表现持平。
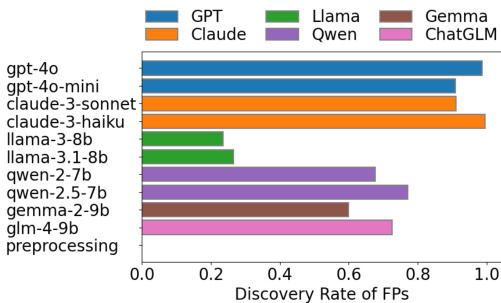
研究对比了不同大型语言模型与经典文本预处理流水线的真映射发现率。结果表明,经典预处理方法能达到接近 1.0 的发现率,而大型语言模型的表现存在差异,部分商业模型的表现甚至低于开源模型。发现率同时受模型类型与提示策略的影响。经典文本预处理流水线为真映射实现的发现率接近 1.0,优于大多数大型语言模型。商业模型在真映射发现率上低于开源模型。少样本与自我反思等提示策略并未显著提升真映射发现率,甚至可能产生负面影响。
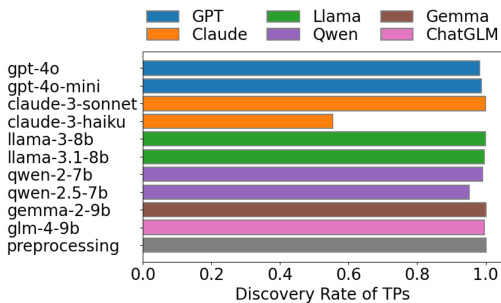
研究对比了不同大型语言模型与经典文本预处理流水线的假阳性发现率。结果表明,通过 API 调用的商业模型在假阳性发现率上普遍优于开源模型,且更复杂的提示策略并未始终提升性能。文本预处理流水线能达到接近顶尖模型的表现,显示其在识别错误映射方面具备强大能力。商业模型在假阳性发现率上高于开源模型。复杂提示策略并未始终提升假阳性检测性能。经典文本预处理流水线为假阳性提供高发现率,与表现最佳的模型相当。
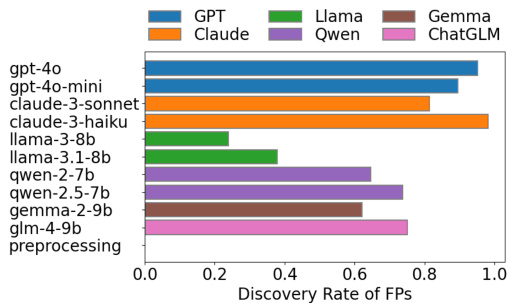
研究对比了不同大型语言模型与提示策略在本体匹配任务中检测真映射的性能。结果表明,开源模型在真映射发现方面普遍优于通过 API 调用的商业模型,且简单的提示策略比包含少样本示例或自我反思的复杂策略更为有效。经典文本预处理流水线在所有模型与提示下均能达到近乎完美的发现率,证明其作为稳定识别方法的可靠性。开源模型在真映射发现率上高于商业模型。简单提示策略在真映射检测上优于包含少样本示例与自我反思的复杂策略。经典文本预处理流水线在所有大型语言模型与提示策略下始终维持近乎完美的发现率。
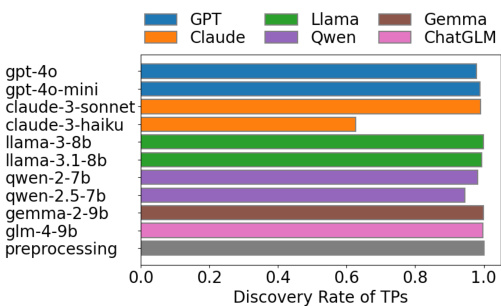
实验通过对比商业与开源大型语言模型、多种提示策略及经典文本预处理流水线,评估本体匹配中错误映射与真映射的检测能力。结果表明,商业模型通常在识别错误映射方面表现优异,而开源模型在真映射检测上表现更佳,复杂提示策略在这两类任务中均未展现出稳定优势。最终,经典预处理流水线展现出更优的稳定性与可靠性,在两项评估任务中始终与表现最佳的模型持平或超越该模型。