Command Palette
Search for a command to run...
GSM-Symbolic:理解大语言模型在数学推理中的局限性
GSM-Symbolic:理解大语言模型在数学推理中的局限性
Iman Mirzadeh Keivan Alizadeh Oncel Tuzel Samy Bengio Hooman Shahrokhi Mehrdad Farajtabar
摘要
大型语言模型(LLM)的最新进展引发了学界对其数学推理能力的广泛关注。尽管在广受推崇的 GSM8K 基准测试中,模型表现有所提升,但关于已报告评估指标的可靠性以及 LLM 推理能力的真实进展仍存在疑虑。为了克服现有评估方法的局限性,我们引入了 GSM-Symbolic,这是一个基于符号模板构建的改进型基准测试,能够生成多样化的问题集。GSM-Symbolic 支持更具可控性的评估,为衡量模型的推理能力提供了关键见解和更可靠的指标。我们的研究结果揭示,LLM 在应对同一问题的不同实例化时,表现存在显著差异。具体而言,当 GSM-Symbolic 基准测试中的问题仅数值发生改变时,模型的性能会出现下降。此外,我们深入探讨了这些模型在数学推理方面的脆弱性,并证明随着问题中子句数量的增加,模型性能会显著恶化。我们假设,这种性能衰退的原因是当前的 LLM 并不具备真正的逻辑推理能力,而是试图复现其训练数据中观察到的推理步骤。
一句话总结
作者介绍了 GSM-Symbolic,这是一个利用符号模板生成多样化问题的基准测试,旨在克服现有评估(如 GSM8K)的局限性,通过揭示不同数值实例化下的性能差异以及条款数量增加导致的显著性能下降,表明模型是在复制训练模式而非执行真正的逻辑推理。
核心贡献
- 这项工作引入了 GSM-Symbolic,这是一个由符号模板创建改进的基准测试,允许生成多样化的问题集。该基准测试支持更可控的评估,并为衡量模型的推理能力提供可靠的指标。
- 研究发现,大语言模型在响应同一问题的不同实例化时表现出明显的差异。具体而言,当仅改变 GSM-Symbolic 基准测试中问题内的数值时,模型性能会下降。
- 研究表明,随着问题中条款数量的增加,模型性能会显著恶化。这些发现支持了当前模型缺乏真正逻辑推理而是复制训练数据中观察到的步骤的假设。
引言
数学推理对于在科学和现实世界应用中部署人工智能至关重要。现有评估依赖于静态基准测试(如 GSM8K),这限制了鲁棒性测试并存在数据污染风险。作者通过 GSM-Symbolic 解决了这些差距,这是一个利用符号模板生成多样化问题变体以进行受控评估的基准测试。他们的发现表明,模型性能在不同问题实例化之间变化,并在数值或无关条款改变时下降。这些结果表明大语言模型依赖于模式匹配而非真正的逻辑推理。
数据集
-
数据集构成与来源
- 作者的工作基于 GSM8K 数据集,该数据集包含超过 8000 道小学数学问题,分为 7473 个训练示例和 1319 个测试示例。
- 他们引入 GSM-Symbolic 以生成具有可控难度的大量实例,解决数据污染风险和对问题微小修改的敏感性。
-
处理与关键细节
- 模板由 GSM8K 测试示例创建,通过识别变量、域和条件(如整除性)以确保整数答案。
- 使用常见专有名词作为人名、食物和货币,同时自动化检查验证原始值未出现在模板中。
- 人工审查涵盖每个模板的 10 个随机样本,如果在评估期间少于两个模型正确回答问题,则触发额外审查。
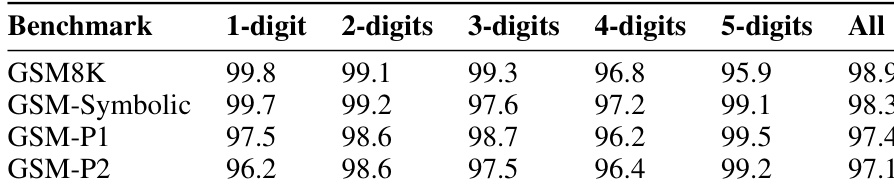
- 数值范围与原始 GSM8K 测试集保持一致,以专注于已知精度边界内的逻辑推理而非算术技能。
-
模型使用与评估
- 数据作为可靠的评估框架,将大语言模型性能视为各种问题实例上的分布。
- 这种方法评估数学能力和对多样化问题难度及增强的鲁棒性,超越了单一固定指标。
实验
这项工作使用 GSM-Symbolic 评估各种大语言模型的推理能力,该基准测试通过变异 GSM8K 模板生成,以测试可靠性和鲁棒性。结果表明,在不同问题实例化之间存在显著的性能差异,由于潜在的数据污染,原始 GSM8K 指标往往高估了真实能力。额外实验表明推理能力是脆弱的,因为随着数值复杂性或无关信息的增加,准确率下降,表明模型依赖于模式匹配而非正式逻辑理解。
作者在 GSM8K 基准测试及其符号变体上评估各种大语言模型,以评估推理可靠性。结果表明,与原始 GSM8K 数据集相比,当模型在符号变体上测试时,性能一致下降,表明存在潜在的数据污染或依赖于模式匹配而非正式推理。此外,增加问题难度或添加无关信息导致所有测试模型的准确率显著下降。模型在标准 GSM8K 基准测试上通常比符号变体获得更高的准确率。通过添加条款增加问题难度会导致与基础符号版本相比更低的性能分数。添加看似相关但无关紧要的信息导致整体性能分数最低。
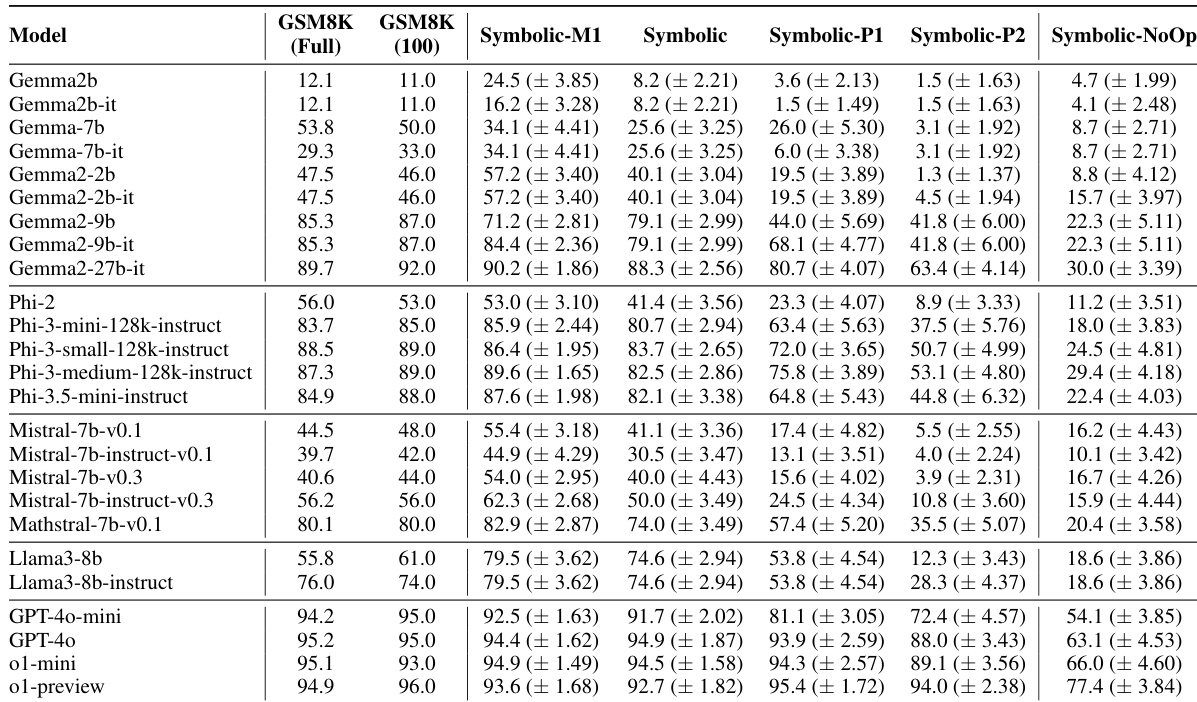
作者比较了模型在原始 GSM8K 基准测试和三种修改变体上的性能,这些变体旨在通过符号变化和增加难度来测试推理鲁棒性。结果表明,与修改版本相比,原始 GSM8K 基准测试持续获得更高的整体准确率。这表明这些变体引入了略微降低模型性能的挑战。原始 GSM8K 基准测试显示出优于修改后的 GSM-Symbolic 和 GSM-P 变体的整体性能。通过添加条款增加问题难度导致准确率可测量的下降,GSM-P1 和 GSM-P2 的得分低于 GSM-Symbolic。模型在基准测试上保持高准确率,尽管测试的具体变体对最终结果有明显影响。
作者在 GSM8K 基准测试和修改变体上评估大语言模型,以评估推理可靠性及针对符号变化的鲁棒性。结果表明,与原始数据集相比,这些变体上的性能一致下降,表明可能依赖于模式匹配而非正式推理。此外,增加问题难度或添加无关信息导致所有测试模型的准确率显著下降。