Command Palette
Search for a command to run...
使用 Open WebUI 一键部署 Llama 3.1 405B 模型
摘要
一句话总结
作者对 Meta 的 Llama 3.1 405B 在自动化代码生成和算法问题解决方面的表现进行了评估,证明其上下文感知能力和多语言支持能够将自然语言提示词有效转化为简单算法与数据结构任务的可执行代码,但该模型在量子计算、生物信息学和人工智能等高级领域仍面临挑战。
核心贡献
- 本文对 Llama 3.1 405B 将自然语言提示词转化为多语言可执行代码的能力进行了实证评估,奠定了其在基础算法与数据结构任务上的性能基线。
- 实验结果量化了模型在特定领域的性能下降情况,明确指出其在生成量子计算、生物信息学和人工智能领域正确代码时存在一致的局限性。
- 分析指出了大语言模型生成代码的固有缺陷,包括语法错误、语义不准确和效率低下,同时展示了上下文感知与调试功能如何提升软件开发效率。
引言
大语言模型日益赋能开发者将自然语言提示词转化为多种编程语言的功能性代码,从而简化软件开发工作流并降低编程门槛。尽管取得这些进展,现有方法仍常生成语法正确但语义存在缺陷或未优化的代码,且在深度推理、复杂编程结构和严格领域约束方面表现不佳。作者对 Meta 的 Llama 3.1 405B 模型进行评估,以基准测试其代码生成与算法问题解决能力,证明其在基础数据结构与排序任务中表现可靠。研究指出,当模型接触量子计算、生物信息学和高级人工智能等特定领域时,性能会出现显著下降,这为针对性的架构优化与领域特定训练以弥补计算短板提供了清晰路线。
数据集
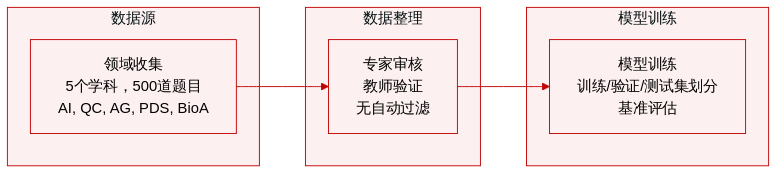
- 数据集构成与来源:作者通过咨询五个技术领域的专家教师,汇编了一个专门的编程语料库,涵盖人工智能(AI)、量子计算(QC)、算法(AG)、编程与数据结构(PDS)以及生物信息学应用(BioA)。
- 子集详情:每个领域恰好包含 100 道编程题,共计 500 题,形成平衡的数据集。该集合包含领域特定的编码任务,例如量子计算实现中为最大割问题定义量子比特算子。
- 数据用途与处理:作者将该精选数据集用作模型训练与评估的基准。尽管提供的片段未明确具体的训练集划分或混合比例,但题目按学科结构化排列,以测试综合技术能力。
- 其他处理细节:文本未提及任何裁剪策略或元数据构建流程。验证完全依赖专家咨询而非自动过滤,从而确保技术准确性与教学相关性。
方法
作者采用模块化且结构清晰的方法实现 A* 算法,用于加权图中的高效路径搜索。核心框架通过维护两个主要数据结构运行:一个包含待评估候选节点的开放集合,以及一个通过 cameFrom 字典追踪到达每个节点已知最佳路径的映射表。每个节点被分配一个代价函数 f(n)=g(n)+h(n),其中 g(n) 表示从起始节点到节点 n 的实际代价,h(n) 是对到达目标剩余代价的启发式估计。算法迭代进行,每一步从开放集合中选出 f(n) 最低的节点,若发现更短路径则更新其邻居节点的代价,并将这些更新传播至整个图。
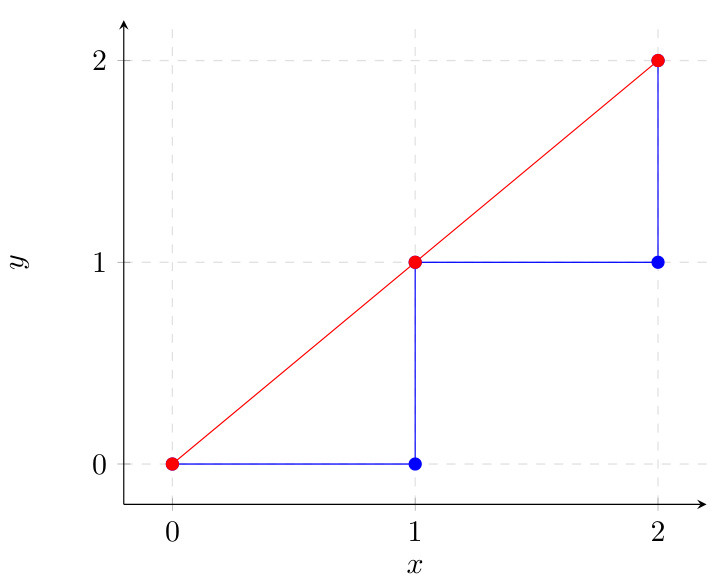
如图所示,算法按总估计代价的顺序评估节点,优先选择看似更直接通向目标的路径。红线表示算法实际走过的路径,蓝线代表探索过程中遍历的边。启发式函数 h(n)(本例中为曼哈顿距离)通过使选择偏向更接近目标的节点来引导搜索,确保算法高效收敛至最优路径。该实现包含一个标准循环,在到达目标节点或开放集合耗尽时终止,返回重建的路径或失败指示符。该设计强调清晰性与正确性,变量定义明确,逻辑流程与 A* 搜索的理论基础保持一致。
实验
通过专家验证与人工评分,对三种大语言模型在多个技术领域生成正确、相关且完整代码的能力进行了评估。该实验框架验证了各模型在特定领域问题解决能力方面的客观准确性与主观质量。定性分析表明,Llama 3.1 405B 持续提供最可靠且详尽的输出,Gemini 紧随其后,而 GPT-3.5 Turbo 在特定类别中表现出明显局限。尽管专家反馈指出领先模型在优化与结果解读方面存在微小的实现考量,但其仍是处理复杂编程任务的最优选择。
作者对比了三种语言模型(Llama 3.1 405B、Gemini 和 GPT-3.5 Turbo)在跨领域编程任务上的表现,评估其正确性与人工评分质量。结果显示,Llama 3.1 405B 在多数类别中达到最高准确率,并在相关性与完整性的评估中优于其他模型,而 GPT-3.5 Turbo 表现较低,尤其在特定领域。在正确性方面,Llama 3.1 405B 在所有类别中均取得最高性能。GPT-3.5 Turbo 在算法与 PDS 领域表现良好,但在 AI、BioA 和 QC 领域表现显著较差。Llama 3.1 405B 在相关性与完整性方面获得最高的人工评分。
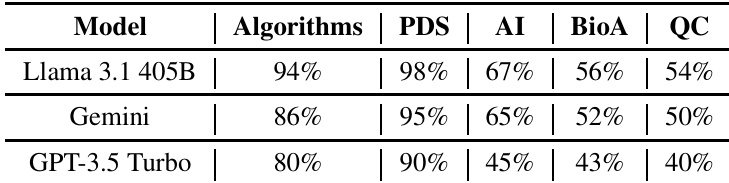
作者结合自动正确性评估与人工评估,对三种语言模型(Llama 3.1 405B、Gemini 和 GPT-3.5 Turbo)在跨学科编程任务上的表现进行了评估。结果显示,Llama 3.1 405B 在相关性与完整性方面均优于其他模型,Gemini 排名第二,GPT-3.5 Turbo 得分最低。与 Gemini 和 GPT-3.5 Turbo 相比,Llama 3.1 405B 在相关性与完整性上均取得最高分。Gemini 表现强劲,在两项评估指标中均排名第二。在三个模型中,GPT-3.5 Turbo 的相关性与完整性得分最低。
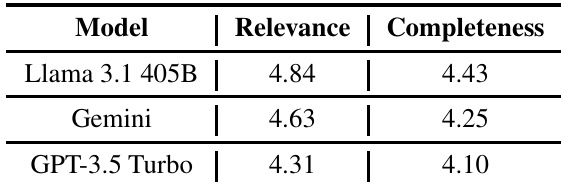
实验通过自动正确性验证以及人工对相关性与完整性的评估,考察了 Llama 3.1 405B、Gemini 和 GPT-3.5 Turbo 在跨领域编程任务上的表现。Llama 3.1 405B 持续展现出卓越的准确性,并生成最相关且完整的解决方案,确立其作为最强性能模型的地位。Gemini 凭借可靠结果位列第二,而 GPT-3.5 Turbo 表现出明显短板,尤其在专业技术领域。这些发现共同验证了清晰的性能层级,突显了 Llama 3.1 405B 在复杂编程应用中的鲁棒性。