Command Palette
Search for a command to run...
一键部署 MinerU
摘要
一句话总结
MinerU 是一款开源文档内容提取解决方案,它将 PDF-Extract-Kit 模型与精细调优的预处理和后处理规则相结合,能够针对各类文档持续输出高精度结果。实验评估验证了该方法在提取质量与一致性方面的显著提升。
核心贡献
- 推出 MinerU,一个用于高精度文档内容提取的开源框架,旨在解决现有开源解决方案性能不稳定的问题。
- 将 PDF-Extract-Kit 模型与优化后的预处理及后处理规则相整合,以精准解析多样化的文档布局与内容类型。
- 跨多类文档的实验评估表明,该框架能够持续保持高性能,提供可靠且准确的文档内容提取结果。
引言
文档内容分析仍是计算机视觉领域的一项基础任务,对于将复杂的论文、报告和表格转换为结构化、机器可读的格式至关重要。尽管在光学字符识别(OCR)、版面检测和公式识别方面已取得显著进展,但现有开源工具在面对高度多样化的文档布局时,始终难以维持高提取质量。本文提出 MinerU,一个开源框架,该框架结合 PDF-Extract-Kit 模型与优化后的预处理及后处理流水线,能够在不同文档结构中提供可靠且高精度的内容提取。该方法在保持对研究社区完全开放的同时,显著提升了自动化文档解析的准确性与一致性。
数据集
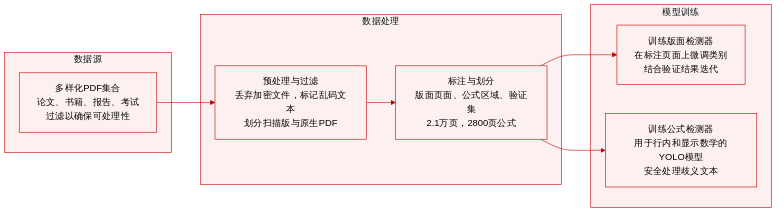
-
数据集构成与来源: 研究团队汇编了高度多样化的 PDF 文档集合,涵盖学术论文、教材、试卷、杂志、演示文稿、研究报告及财务报告。初始数据接入流水线严格过滤非 PDF 文件、加密文档及密码保护文件,以确保后续可处理性。
-
子集详情与标注:
- 版面分析子集: 约 2.1 万页标注数据,涵盖标题、正文段落、图片、表格、图注、注释,以及页眉、页脚和页码等需舍弃的元素。
- 公式检测子集: 从中英文论文、教材及财务报告中提取的 2,890 页数据,包含 24,157 个行内公式和 1,829 个行间公式。设置忽略类别以捕获无法可靠分类的模糊数字或化学文本。
- 评估子集: 精心筛选的 11 类文档集合,旨在实际场景中评估版面与公式检测的性能基准。
-
元数据构建与预处理: 流水线提取关键文档元数据,包括总页数、页面尺寸及语言识别(仅限中英文)。系统会自动标记乱码文本型 PDF,并基于图像面积与文本面积的比例以及接近零的平均页面文本长度,将文档分类为扫描件或原生文本。扫描件将触发 OCR 流程,而原生文本文档则直接跳过该步骤。
-
训练策略与使用: 采用迭代式数据筛选与模型训练循环。初始视觉聚类指导多样化文档的采样,验证结果动态调整采样权重,以优先覆盖表现不佳的类别或来源。版面子集使用自定义类别参数对现有检测架构进行微调,公式子集则训练基于 YOLO 的检测器,针对多样化文档布局在速度与精度之间取得优化平衡。
方法
研究团队将多模块文档解析策略作为 MinerU 的核心技术方案,旨在克服现有方法在处理多样化复杂文档布局时的局限性。整体框架包含四个连续阶段:文档预处理、内容解析、内容后处理与格式转换。如图所示,流程始于文档预处理,该阶段使用 PyMuPDF 读取输入 PDF,过滤加密文档等不可处理文件,并提取解析可行性、语言及页面尺寸等元数据。此阶段确保仅有效文档进入后续流程。
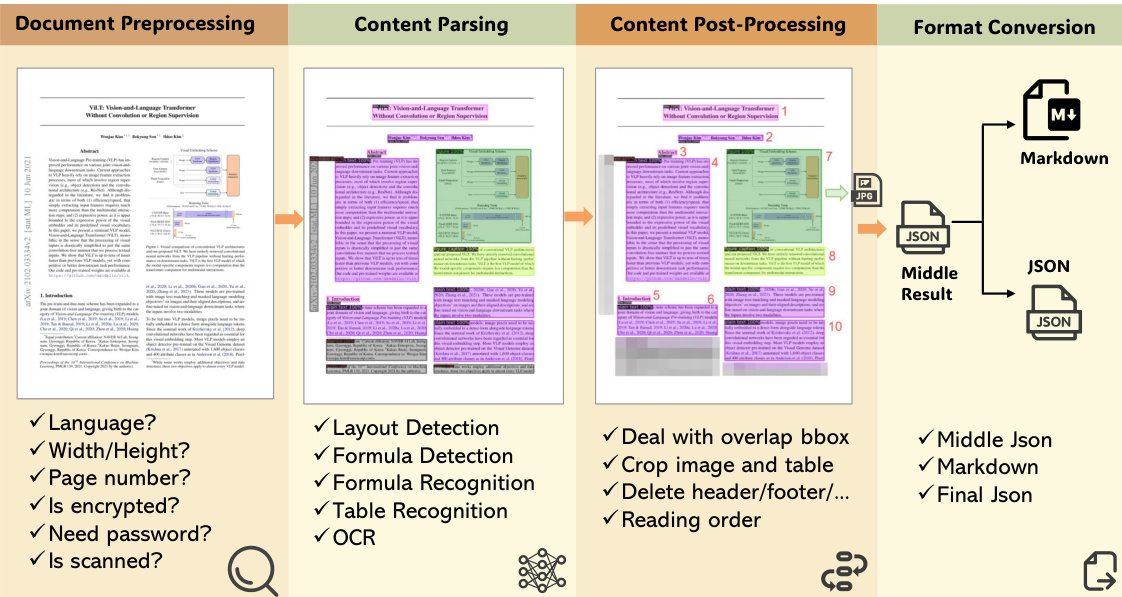
在内容解析阶段,MinerU 采用 PDF-Extract-Kit,该库包含在多样化真实文档上训练的最先进开源模型。该阶段首先进行版面分析,检测并分类文本、公式、表格及图像等各类区域。版面检测完成后,针对不同区域应用专用识别器:文本与标题使用 OCR,公式识别采用自研的 UniMERNet 模型,表格识别则使用 TableMaster 与 StructEqTable。UniMERNet 模型基于 UniMER-1M 数据集训练,在各类公式识别上达到与商业工具相当的性能。表格识别由基于 PubTabNet 训练的 TableMaster 和基于 DocGenome 训练的 StructEqTable 共同承担,后者针对复杂表格提供端到端识别能力。

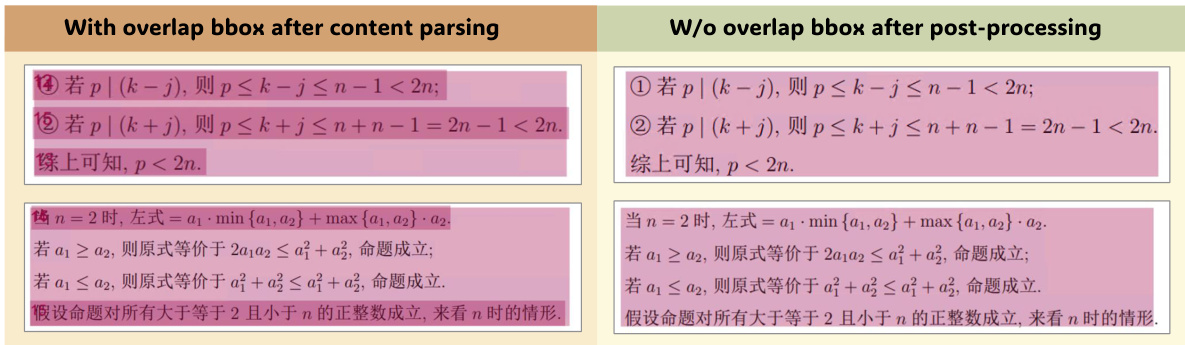
内容后处理阶段旨在解决由边界框重叠与嵌套引发的内容排序问题。该阶段处理不同元素间的包含与部分重叠关系。例如,移除图像或表格内嵌的公式与文本块,并收缩部分重叠的文本框以避免相互遮挡。为保持阅读顺序,采用基于人类“从上到下、从左到右”阅读习惯的分割算法,将页面划分为至多包含一列的区域。这确保了元素按照自然阅读流进行排序。
最后,格式转换阶段将处理后的数据转化为用户指定的格式。中间结构以 JSON 文件存储,保存所有文档区域的位置、内容与排序信息。基于该结构,MinerU 可生成 Markdown 及自定义 JSON 格式等输出。系统支持图像与表格的裁剪,并确保最终输出的阅读顺序正确。整个工作流专为处理学术论文、教材及报告等多样化文档类型而设计,在保持高提取质量的同时实现较低的推理成本。
实验
评估通过独立模块测试与端到端可视化,检验 MinerU 在学术及多样化文档类型上的 PDF 提取质量。版面检测、公式检测与公式识别实验验证了 MinerU 专用模型能够精准定位区域、识别数学内容,并以匹配或超越商业替代方案的鲁棒性转录公式。后续的后处理与拼接步骤进一步确保最终 Markdown 输出保持高可读性与结构准确性。综合结果表明,在异构文档源上进行训练显著优于单一领域的开源模型,能够交付可靠且精确的内容提取结果。
研究团队使用两个验证集(分别聚焦学术论文与多源文档)评估其公式检测模型与现有开源模型的性能。结果表明,该模型在两个数据集上均优于基线模型。所提模型在学术论文与多源验证集上均展现出超越基线的性能,并在不同类型的文档源上保持稳定的性能提升。评估结果凸显了在多样化数据上进行微调对公式检测的有效性。

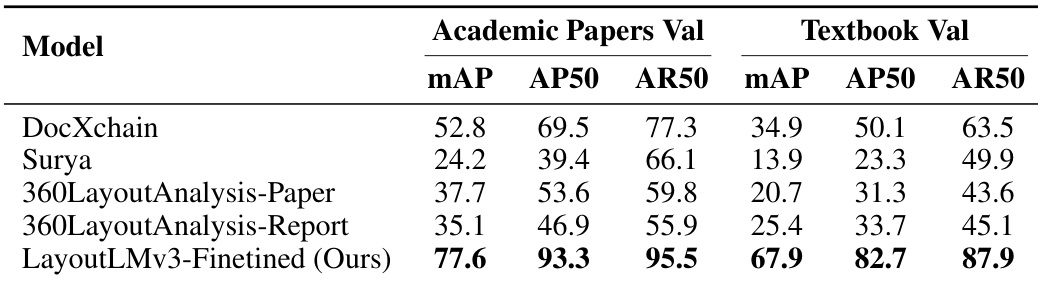
研究团队利用学术论文与教材的验证集,评估 MinerU 模型与多款开源模型的版面检测性能。结果显示,该模型在两个数据集的多个指标上均优于其他模型。相较于其他模型,所提模型在学术论文与教材验证集上均取得最高性能。模型在不同评估指标上均呈现稳定提升,表明其具备稳健的性能。结果证实,微调后的模型在版面检测任务中显著优于现有开源模型。
研究团队通过多项指标评估 MinerU 的 UniMERNNet 模型与其他开源模型的公式识别性能。结果表明,UniMERNNet 显著优于其他模型,尤其在 CDM 指标上表现突出,并达到与商业工具相当的性能。评估验证了多样化数据训练对提升公式识别鲁棒性的有效性。UniMERNNet 在公式识别任务中领先于其他开源模型,CDM 指标优势尤为明显。其识别性能与商业软件持平,凭借优异的 CDM 得分,在多样化的公式表示中均实现了高识别准确率。
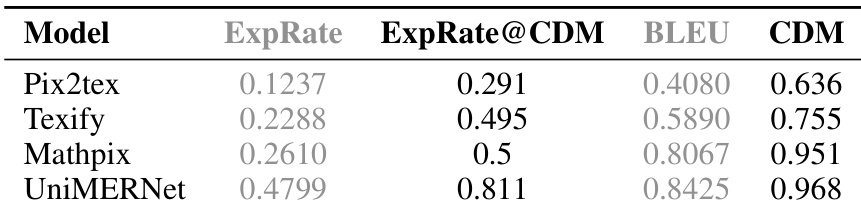
研究团队基于学术论文、教材及多源文档的验证集,对公式检测、版面检测与公式识别模型与开源基线及商业工具进行对比评估。公式检测与版面检测实验验证了模型在多样化文档结构上的稳健泛化能力,而公式识别任务则证实系统能够达到与成熟商业软件相当的准确率。综合这些发现,强调了在异构数据上训练的有效性,并证明其相较于现有开源替代方案具备持续的性能优势。