Command Palette
Search for a command to run...
美国手语检测
摘要
一句话总结
本文介绍了 3D-LEX v1.0,这是一个包含 1,000 个美国手语和 1,000 个荷兰手语词汇的数据集。该数据集通过高分辨率的 3D 姿态、手型和深度感知面部特征进行捕获,用于半自动语音特征标注。在手语识别任务中,一种直接的手型生成方法使词义识别准确率较未标注基线提升 5%,较专家标注提升 1%。
核心贡献
- 引入了一种高效的 3D 手语捕获流程,同步高分辨率 3D 姿态、3D 手型和深度感知面部特征,实现平均每 10 秒采样一个手语的频率。
- 展示了 3D-LEX v1.0 数据集,包含来自美国手语和荷兰手语各 1,000 个手语词汇,并与现有的手语基准和语言资源保持一致。
- 详述了一种用于语音特征的半自动标注方法,可生成手型标签,在手语识别任务中使词义识别准确率较未标注基线提升 5%,较专家标注提升 1%。
引言
手语是一种复杂的视觉系统,结合手部与非手部标记来传递意义,既是听障群体的主要交流方式,也是计算语言学和无障碍应用日益关注的领域。传统的词汇资源在捕捉手语完整空间动态方面往往存在不足,这阻碍了准确的手语处理与翻译系统的发展。本文利用 3D 建模技术推出了 3D-LEX v1.0,这是一个面向美国手语和荷兰手语的综合词汇数据库。该资源提供了标准化的空间标注,支持更精确的计算分析,并助力先进手语技术的开发。
数据集
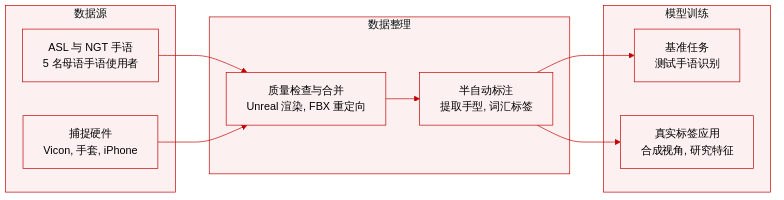
-
数据集构成与来源
- 本文展示了 3D-LEX v1.0,这是一个包含 2,000 个孤立手语的语料库,美国手语与荷兰手语各占一半。
- 所选词汇与 WLASL、SEMLEX、ASL-LEX 2.0 和 SignBank NGT 等既定基准保持一致。
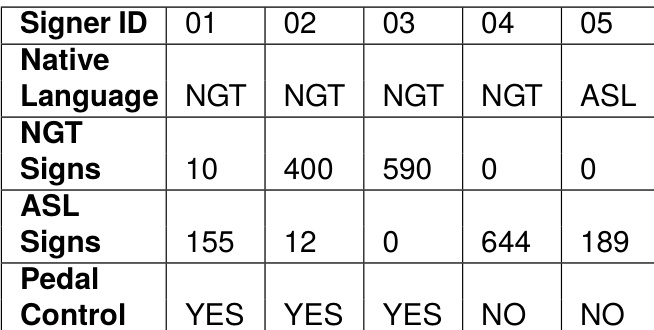
- 所有录制均源自五名母语手语使用者,在配备专业动作捕捉硬件的控制工作室环境中完成。
-
子集详情
- 手型数据: 使用 StretchSense Pro Fidelity 手套捕获,用于测量手指张开度、关节旋转角度和传感器拉伸值。本文公开了原始传感器日志及导出的 FBX 文件。
- 身体姿态数据: 通过 Vicon 光学系统记录,该系统包含十个顶置摄像头和两个地置摄像头。本文提供了原始标记点坐标以及通过 Shogun Post 处理生成的 FBX 动画。
- 面部特征: 通过运行 Live Link Face 和 ARKit 的 iPhone 13 Pro 捕获,以提取面部混合形状(blendshapes)。
- 重定向动画: 本文结合处理后的身体姿态与手型数据,生成统一 FBX 文件,针对扩展现实(XR)流程进行优化。
-
数据使用与处理
- 本文并未使用该数据集训练核心机器学习模型。相反,利用其作为基准,评估应用于 1,000 个美国手语词汇的半自动手型标注流程。
- 这些自动生成的标签在孤立手语识别任务中进行评估,结果显示其词义识别准确率较未标注基线提升 5%,较专家提供标签提升 1%。
- 该数据集作为未来研究的 3D 真实值资源,主要用于支持合成多视图 2D 数据生成与详细语音分析,而非直接用于模型训练。
-
裁剪、元数据与制作流程
- 每个手语均在标准化的 10 秒时间窗口内捕获,涵盖演示、表演与归档阶段。
- 本文实施即时质量控制步骤,录制内容在保存至 SignCollect 平台前,需在 Unreal Engine 中渲染为虚拟形象以供实时视觉验证。
- 元数据包含用于保护匿名性的唯一使用者标识符、StretchSense 手套的校准姿态日志,以及由三踏板接口触发并同步三个捕获系统的时间戳。
- 后处理环节包括将原始 Vicon 标记点重定向至骨骼动画,并从手套传感器数据中提取主导手型,以用于后续语言学标注。
方法
本文利用半自动标注框架,从使用 StretchSense 手套捕获的 3D 手语数据中生成手型标签,重点聚焦 3D-LEX 数据集内的美国手语词汇。整体流程旨在生成与现有 ISR 基准所用标注一致的标签,从而实现自动化标签与专家标签的直接对比。该方法首先进行时序分割,以从静止或过渡姿态中分离出特征手型信号。具体做法是计算每一帧手部姿态相对于一组校准姿态的欧几里得距离。得到的距离值用于识别并分割包含主导手型的帧,有效过滤掉无信息量的片段。

为确定每个手语的主导手型,系统计算分割帧中各观测手型的出现频率。出现频率最高的手型被选为代表标签,静止姿态“5”为特例:若其出现频率超过 90%,则保留为标签;否则选择第二频繁的手型。该过程生成用于下游分析的候选帧,进而用于进一步标注。图 5 展示了基于欧几里得距离的分类输出,通过逐帧分类结果的时间序列可视化,说明了手型“o”如何被识别为手语“zero”的特征手型。

鉴于欧几里得距离方法存在局限性,尤其是其对校准姿态的依赖可能无法充分反映词汇表的多样性,本文引入了一种基于 k-means 聚类的更灵活方法。完成时序分割后,候选帧的平均手部姿态被聚类为 k=50 个组,对应 ASL-LEX 词汇表中手型的大致数量。每个手语根据其平均姿态的聚类 ID 分配手型标签,从而覆盖更广泛的手型变化。这种基于聚类的标注方法能够在不严格依赖预定义校准姿态的情况下生成半自动标注。
为评估这些标注的有效性,本文采用孤立手语识别(ISR)任务,使用在 WLASL 基准上训练的 SL-GCN 架构,并限定在与 3D-LEX 重叠的子集上。模型在两种条件下进行训练以预测词义:使用来自 ASL-LEX 的专家标注,以及使用源自 3D-LEX 数据的半自动标签。训练过程持续进行,直至验证准确率在连续 30 个轮次中趋于平稳,数据集划分详见表 3。该设置实现了对使用人工标注与自动生成手型标签训练的模型性能的直接对比。
结果表明,半自动标注达到了与专家标注相当的识别准确率,表明 3D-LEX 手型数据经此流程处理后,能够捕获支持下游识别任务所需的充分语音信息。这一结果说明,高分辨率 3D 传感器数据可在保持语音标签质量的同时,大幅降低对人工语言学标注的依赖。图 6 提供了平均手部姿态的 t-SNE 投影,显示高维特征自然聚合成不同组别,进一步验证了手型标签的有效性以及传感器数据的区分能力。