Command Palette
Search for a command to run...
SpeechPrompt:通过提示语音语言模型处理语音任务
SpeechPrompt:通过提示语音语言模型处理语音任务
Kai-Wei Chang Haibin Wu Yu-Kai Wang Yuan-Kuei Wu Hua Shen Wei-Cheng Tseng Iu-thing Kang Shang-Wen Li Hung-yi Lee
一键部署双人对话语音生成模型 CSM
摘要
提示(Prompting)已成为利用预训练语言模型(LMs)的一种实用方法。该方法具有多项优势:它允许语言模型以极少的训练和参数更新适应新任务,从而在存储和计算上实现高效性。此外,提示仅修改语言模型的输入,并利用语言模型的生成能力统一解决各种下游任务,显著减少了设计特定于任务的模型所需的人工劳动。随着语言模型所服务任务数量的增加,这些优势变得愈发明显。受提示优势的启发,我们首次探索了在语音处理领域应用提示语音语言模型的潜力。近年来,将语音转换为离散单元用于语言建模的研究日益增多。我们的开创性研究表明,这些量化后的语音单元在我们的统一提示框架中具有极高的通用性。它们不仅可以作为类别标签,还包含丰富的音素信息,可重新合成为语音信号,用于语音生成任务。具体而言,我们将语音处理任务重构为语音到单元(speech-to-unit)的生成任务。因此,我们可以在单一的、统一的提示框架中无缝集成语音分类、序列生成和语音生成等任务。实验结果表明,与基于自监督学习模型且具有相似数量可训练参数的强微调方法相比,提示方法能够取得具有竞争力的性能。此外,提示方法在少样本(few-shot)设置下也展现出令人鼓舞的结果。更重要的是,随着先进语音语言模型的不断涌现,所提出的提示框架展现出巨大的潜力。
一句话总结
SpeechPrompt 推出了首个面向语音语言模型的统一提示框架,将分类、序列生成和语音生成重构为单一的语音到单元生成流程,利用量化离散语音单元同时作为类别标签和可重建输出,在参数量相近的微调方法中实现了具有竞争力的性能,并展现出优异的少样本结果。
核心贡献
- 本研究推出了首个面向语音语言模型的统一提示框架,将多样化的语音处理目标重构为一致的语音到单元生成范式。
- 该方法利用量化语音单元,使其同时充当离散分类 tokens 和可重新合成的语音表示,在单一架构内统一了语音分类、序列生成与语音合成。
- 在 SUPERB 基准上的评估表明,该提示方法在保持强大少样本能力的同时,达到了与参数量匹配的微调自监督模型相媲美的性能。
引言
作者利用提示工程简化语音处理流程,而该应用领域传统上依赖资源密集型微调管道。尽管自监督语音模型能够提供稳健的基础表征,但标准的预训练与微调范式需要大量人工设计任务特定架构与损失函数。随着下游任务数量的增加,该方法会迅速面临计算成本过高且难以扩展的问题。为突破这些限制,作者引入了一种基于离散语音单元训练的无文本语音语言模型的统一提示框架。通过将分类、序列生成和语音合成重构为单一的语音到单元生成任务,该方法消除了对自定义下游头的需求。可学习的 verbalizer 能够高效地将离散单元内丰富的语音与声学信息映射到任务特定标签,从而在多样化基准上实现具有竞争力的性能,同时大幅降低存储、计算与人工工程开销。
数据集
- 数据集构成与来源: 作者汇编了一个涵盖三个类别的多任务语料库。语音分类任务采用 Google Speech Commands、Grabo Speech Commands、立陶宛语音命令(Lithuanian Speech Commands)、构音障碍普通话语音命令(Dysarthric Mandarin Speech Commands)、阿拉伯语音命令(Arabic Speech Commands)、流畅语音命令(Fluent Speech Commands)、Mustard++、AccentDB 和 Voxforge。序列生成任务依赖 LibriSpeech 和 AudioSNIPS。语音生成任务使用 CoVoST2 的西班牙语到英语子集以及 LJSpeech。
- 各子集关键细节: AccentDB 子集包含四种印度英语、四种母语英语和一种印度都市英语口音。Voxforge 涵盖六种语言。LJSpeech 提供约二十四小时的单说话人英语音频。Fluent Speech Commands 子集包含动作、物体和位置的三重标签。CoVoST2 子集提供用于西班牙语和英语翻译的平行文本。
- 训练划分与数据处理: 针对自动语音识别与音素识别任务,作者保留 train-clean-100 划分用于训练,test-clean 用于评估。LJSpeech 语料库被划分为训练集、验证集和测试集。语音活动检测任务使用自定义混合数据集 GFSound,该数据集将 Google Speech Commands 版本二与 FreeSound 背景噪声录音相结合。所有分类任务均使用准确率进行评估,而生成任务则依赖词错误率、字错误率、音素错误率、F1 分数、BLEU 分数和困惑度。
- 裁剪策略与元数据构建: 作者针对语音续写任务应用了裁剪策略,将每段语音的初始部分指定为条件种子片段。对于语音翻译,作者使用现成的文本转语音系统将平行文本转换为音频,随后利用现成的自动语音识别模型转录生成的音频,以计算 BLEU 分数与自然度预测。说话人相似度元数据通过计算从种子片段和生成片段中提取的 Resemblyzer 嵌入之间的余弦距离来构建。
方法
所提出的框架利用无文本语音语言模型(speech LMs)在单一生成范式下统一多样化的语音处理任务。核心架构如框架图所示,始于将输入语音波形转换为离散单元序列。该过程通过语音到单元编码器实现,该编码器将自监督学习(SSL)表征模型(如 HuBERT)与 K-means 等量化器相结合。SSL 模型提取连续声学特征,随后将其聚类为离散单元。这些单元旨在封装语音与语言信息,构成模型词汇表的基础。如下方所示,这些离散单元随后被输入至单元语言模型(ULM),该模型基于任务特定提示执行自回归生成。ULM 可以是类似 GPT 的仅解码器模型,也可以是类似 BART 的编解码器模型,两者均基于 Transformer 架构构建。仅解码器变体按顺序处理源语音单元与提示,使用分离 token 进行区分;而编解码器变体则使用编码器处理源单元,解码器基于编码器输出生成目标单元。 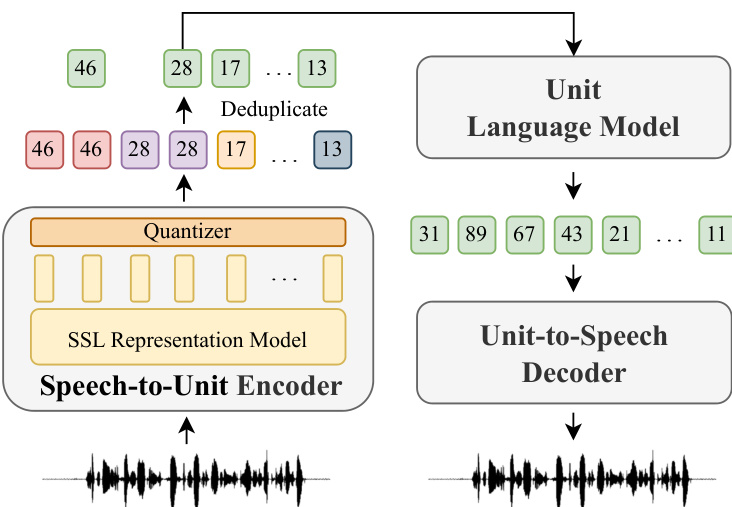
单元的生成由任务特定提示引导,旨在将单元语言模型导向预期的下游任务。该框架支持两种主要的提示微调策略:输入提示微调与深度提示微调。输入提示微调涉及将连续提示向量前置到单元 LM 的输入序列中,随后在嵌入层进行整合。该方法修改了提供给模型的初始上下文。深度提示微调受 prefix-tuning 启发,涉及将可训练提示向量直接插入每个 Transformer 层的注意力机制中。具体而言,这些向量与自注意力模块的键矩阵和值矩阵的输入进行拼接,从而影响注意力权重并引导模型的内部表征,同时不改变原始参数。在这两种方法中,仅提示向量可训练,而单元 LM 及其嵌入表保持冻结,从而确保参数效率。 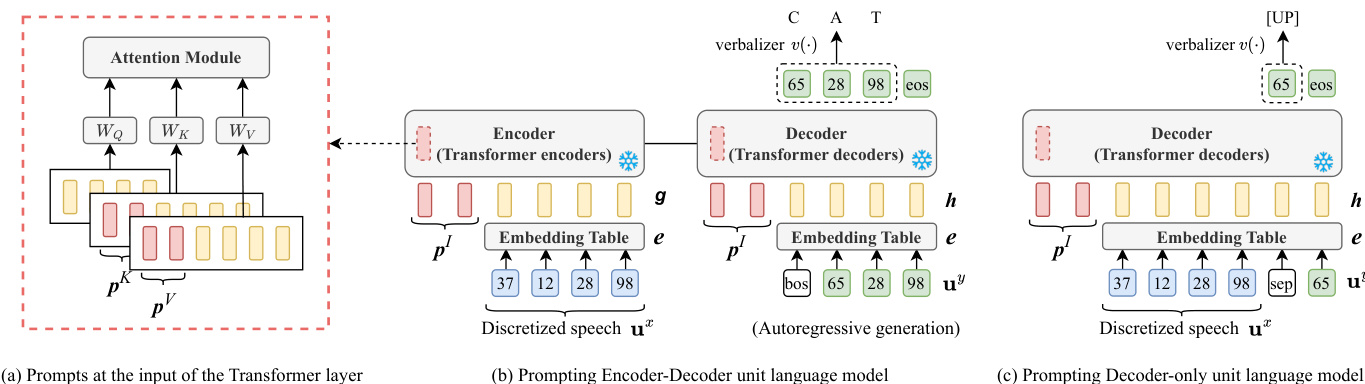
该框架将各类下游任务重构为统一的语音到单元生成任务。针对自动语音识别(ASR)等序列生成任务,模型生成对应于目标文本的离散单元序列。针对语音命令识别(SCR)等语音分类任务,模型生成单一单元序列,随后将其映射至类别标签。针对语音生成任务,生成的单元序列通过预训练的现成单元到语音解码器重新合成为语音波形。最终输出通过 verbalizer 或语音解码器获得。verbalizer 充当连接离散单元与下游任务标签的标签映射模块。它可以是固定映射(如基于随机或频率的启发式规则),也可以是训练用于寻找单元与标签之间最优对应关系的可学习模块。如下方所示,可学习的 verbalizer 使用线性变换将生成的单元映射至最终输出,通过学习相关关联关系来提升性能。 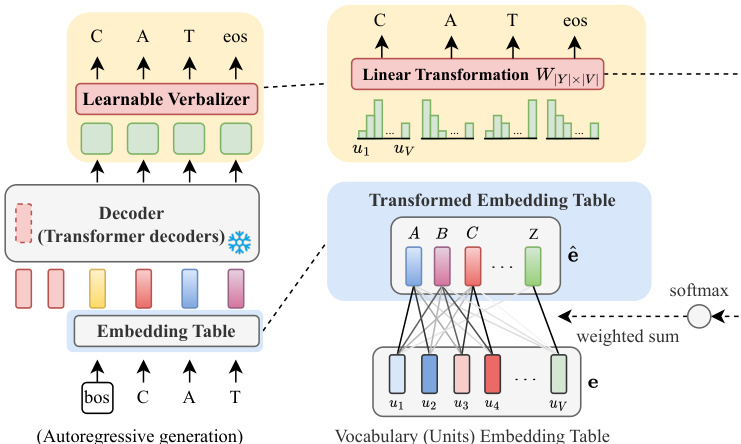
实验
本研究在语音分类、序列生成和语音生成任务上评估了提示范式与传统预训练及微调方法的对比效果。结果表明,提示方法在分类任务中始终能够匹配或超越微调性能,尤其是在使用可学习 verbalizer 时。对于序列生成,结果高度依赖于架构,仅解码器模型在提示下表现不佳,而编解码器模型则实现了具有竞争力或更优的性能。总体而言,提示方法成为微调的稳健且参数高效的替代方案,在与先进的编解码器语音语言模型配合时,在语音翻译与续写任务中展现出极强的可行性。
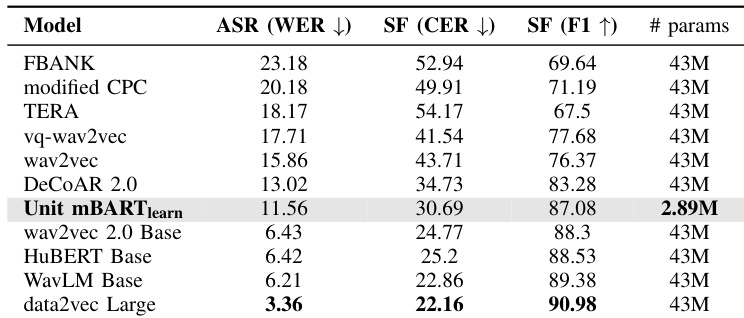
作者对比了不同模型在序列生成任务上的性能,重点聚焦于自动语音识别与槽位填充。结果表明,配备可学习 verbalizer 的 Unit mBART 模型在两项任务中均取得具有竞争力的结果,在槽位填充上优于其他模型,但在 ASR 任务上相较于表现最佳的模型略有下降。配备可学习 verbalizer 的模型参数量显著少于其他模型,凸显了其效率优势。Unit mBART 配合可学习 verbalizer 在槽位填充中实现高性能,同时使用的参数量少于其他模型。该模型在自动语音识别中展现出竞争力,尽管在此任务上略逊于表现最佳的模型。可学习 verbalizer 在多项指标上提升了性能,尤其在槽位填充方面,相较于固定 verbalizer 方法实现了显著改进。
作者对比了提示范式与预训练、微调范式在语音分类、序列生成和语音生成任务上的表现。结果显示,提示方法在语音分类任务中通常表现具有竞争力或优于微调;而在序列生成任务中,配合编解码器模型的提示方法取得竞争性结果,但提示仅解码器模型则表现不佳。在语音生成方面,配合编解码器模型的提示方法能够生成合理的翻译与多样化的语音续写内容,而其他方法无法产生有意义的输出。提示方法在大多数语音分类任务中优于微调,尤其是结合编解码器模型时。编解码器模型配合提示在序列生成中取得竞争性结果,而仅解码器模型配合提示则显著表现不足。提示方法实现了合理的语音翻译与续写,但其他方法在语音生成任务中未能产生有意义的输出。
作者对比了提示范式与预训练、微调范式在语音分类任务上的表现,表明提示方法通常能达到具有竞争力或更优的性能。在大多数情况下,提示方法优于微调,尤其针对特定模型与数据集,仅在少数场景中差异微小。提示方法在语音分类任务中常优于微调,尤其适用于特定模型与数据集。部分场景下提示与微调的性能差异极小,仅观察到细微变化。该提示方法在多种数据集与模型上均取得竞争性结果,并在多个场景中实现显著改进。

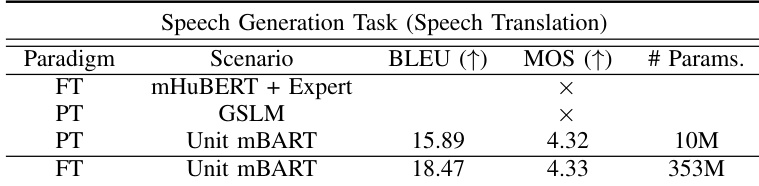
作者对比了提示与微调范式在语音生成任务(具体为语音翻译)上的性能。结果表明,提示 Unit mBART 以显著少于全模型微调的可训练参数,达到了具有竞争力的翻译质量。相比之下,提示 GSLM 以及使用专家模型微调 mHuBERT 均无法在此任务中产生合理结果。提示 Unit mBART 以大幅减少的参数量实现了具有竞争力的翻译性能。提示 GSLM 和使用专家模型微调 mHuBERT 在语音翻译任务中未能产生合理结果。提示 Unit mBART 在语音翻译中展现出熟练能力,尽管性能较全量微调有所下降,但仍取得了非平庸的 BLEU 分数。
作者对比了 GSLM 与 Unit mBART 在不同条件率下的语音续写任务性能。结果表明,GSLM 在所有条件下均取得低于 Unit mBART 的困惑度,而 Unit mBART 相比原始语音能生成更多样化且说话人相似度更高的输出。两款模型在平均意见得分与说话人相似度方面的语音质量相当。GSLM 在所有条件率下的困惑度均优于 Unit mBART。Unit mBART 生成的输出相比原始语音具有更高的多样性与说话人相似度。两款模型在平均意见得分与说话人相似度上均达到相当的语音质量。

实验在分类、序列生成、翻译与续写任务上评估了语音语言模型与训练范式,主要对比参数高效的提示方法与传统微调方法。结果表明,提示方法通常能够匹配或超越微调性能,尤其是在使用编解码器架构时,而仅解码器变体在序列与语音生成任务中表现吃力。针对特定模型的分析显示,配备可学习 verbalizer 的 Unit mBART 实现了高效准确的槽位填充,并具备竞争力的自动语音识别能力;而 GSLM 在语音续写中取得了更低的困惑度,Unit mBART 则在输出多样性与说话人相似度方面表现更优。综合来看,这些发现证实,战略性架构设计与基于提示的训练为多样化语音处理应用提供了稳健且参数高效的方案,可作为全量微调的有效替代。