Command Palette
Search for a command to run...
Deberta-v3-base 基准模型 [训练]
摘要
一句话总结
为解决行人属性识别中的数据稀缺与领域差异问题,本文提出了 MSP60K 基准数据集(包含 60,122 张图像,涵盖 57 种属性及 8 个场景,并包含合成退化数据),在随机划分与跨领域划分下评估了 17 种代表性模型,并提出了 LLM-PAR 框架。该框架采用 Vision Transformer 作为主干网络,结合多嵌入查询 Transformer,并引入大语言模型进行集成学习与视觉特征增强。
核心贡献
- 针对行人属性识别中的领域偏移与数据集饱和问题,本文提出了 MSP60K,这是一个包含 60,122 张图像的大规模跨领域数据集,涵盖 8 个场景下的 57 项属性标注。该数据集引入了合成图像退化以模拟真实世界条件,并通过在随机划分与跨领域划分协议下对 17 种代表性识别模型进行基准测试,建立了严格的评估流程。
- 本研究提出了 LLM-PAR 识别框架,该框架将 Vision Transformer 主干网络与多嵌入查询 Transformer 相结合,以提取全局与局部感知视觉特征。该架构集成了大语言模型,通过指令引导的文本处理执行集成学习并增强特征表示。
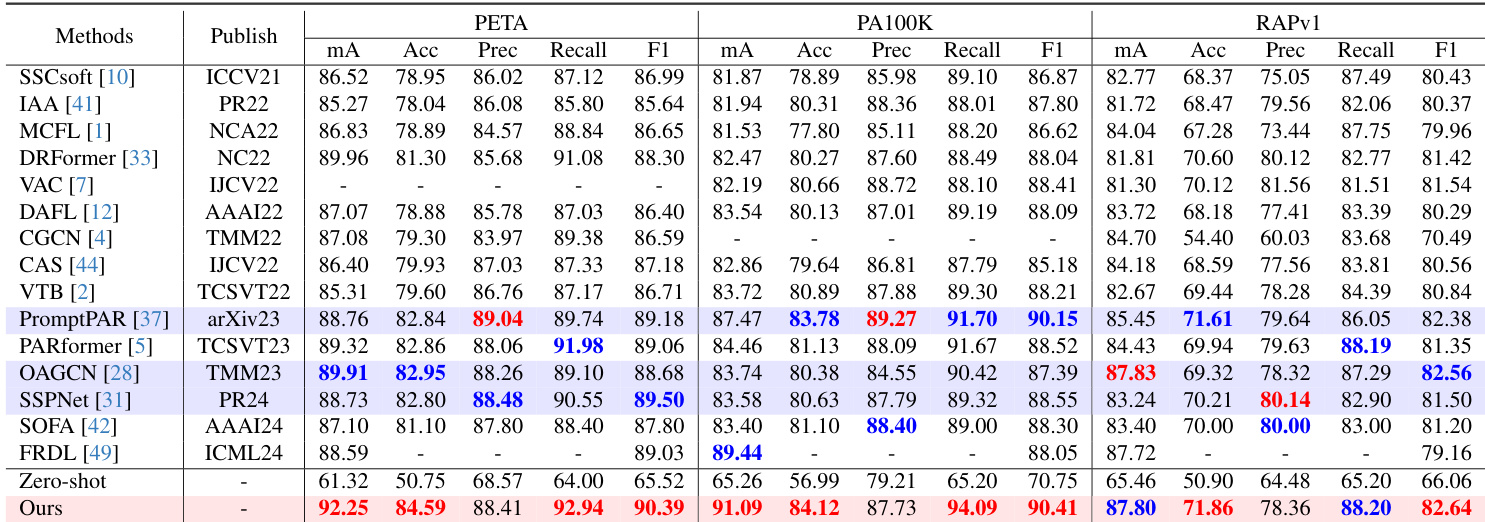
- 在 MSP60K 及现有基准数据集上的广泛评估验证了该框架的有效性,其在多个数据集上均取得了最先进的性能。该方法在 PETA 数据集上取得 92.20 mA 与 90.02 F1 的成绩,在 PA100K 数据集上取得 91.09 mA 与 90.41 F1 的成绩。
引言
行人属性识别通过将捕获的图像映射到服装与人口统计等语义标签,为监控追踪与行人重识别等关键计算机视觉应用提供核心支持。尽管具有实际应用价值,但该领域的发展已陷入停滞,主要原因在于现有基准数据集已接近性能饱和,过度依赖简单的随机划分,且忽略了跨领域差异或运动模糊、低光照等真实成像缺陷。为突破这些局限,本文提出了 MSP60K,这是一个包含 8 个多样化场景、超过 60,000 张图像的大规模跨领域数据集,并辅以合成退化数据以模拟实际部署挑战。基于该基准,本研究开发了 LLM-PAR 框架,该框架将 Vision Transformer 与多嵌入查询模块相结合,并利用大语言模型丰富视觉特征,从而推动稳健的集成学习以用于属性分类。
数据集

-
数据集构成与来源: 本文提出 MSP60K 行人属性识别基准,包含 60,122 张图像,拍摄于市场、学校、厨房、滑雪场以及多种户外与建筑场地等 8 个真实环境。数据源自多种相机与手持设备,涵盖超过 5,000 名不同国籍的个体,包含季节变化以及正面、背面与侧面视角。
-
各子集关键细节: 数据集为评估目的划分为三种主要配置。标准随机划分将数据按均匀的场景分布分为 30,298 张训练图像、6,002 张验证图像与 23,822 张测试图像。跨领域划分将 5 个特定场景的 34,128 张图像用于训练,将 3 个户外场景的 24,994 张图像用于测试。此外,通过模拟光照变化、随机遮挡、运动模糊与噪声,有意对每个划分中三分之一的图像进行退化处理,从而构建鲁棒性子集。
-
数据使用与处理: 本文利用这些划分在标准与泛化条件下对行人属性识别模型进行基准测试。随机划分支持常规的训练与评估,跨领域划分则专门测试领域泛化与零样本性能。退化子集使研究人员能够衡量模型应对真实成像挑战的韧性。此外,本文还利用完整数据集分析长尾属性分布,并训练用于领域可视化的特征提取器。
-
元数据与标注细节: 每张图像均标注了 57 种独立属性,分为 11 个类别,包括性别、年龄、体型、视角、头饰、上下身服装、鞋履、包袋、肢体动作及运动器材。本文构建了全面的元数据,包含场景标识符、领域标签以及属性共现频率的统计记录。尽管未描述明确的裁剪流程,但原始图像分辨率跨度较大,从 30×80 到 2005×3008 像素不等,需在模型训练阶段进行下游归一化处理。
方法
本文提出了一种用于行人属性识别的多模态框架 LLM-PAR,通过视觉特征提取、图像描述生成与分类模块三个核心组件实现视觉与文本推理的融合。整体架构利用预训练 Vision Transformer 主干网络进行视觉特征提取,通过大语言模型(LLM)分支生成描述性文本,并采用模型聚合机制融合两个分支的输出。如框架图所示,处理流程始于输入行人图像,将其划分为图块并投影为视觉 tokens。这些 tokens 叠加位置嵌入后,输入至视觉编码器(如 EVA-ViT-G)以生成全局视觉表示 FV。为实现高效微调,视觉编码器参数被冻结,并应用 LoRA 自适应地微调模型。
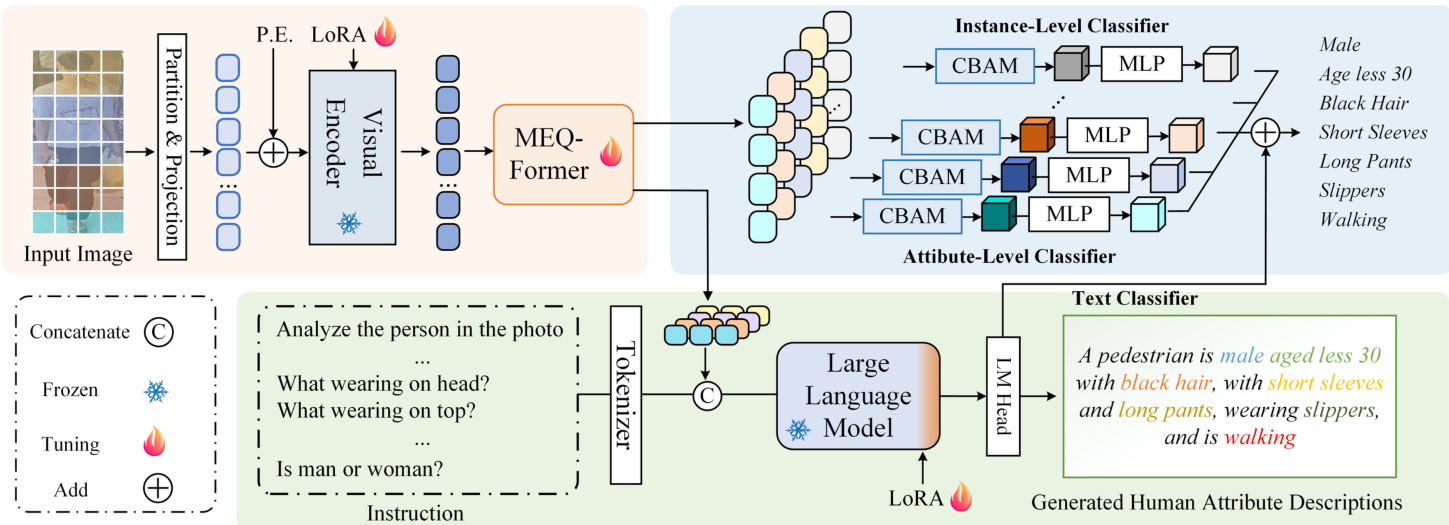
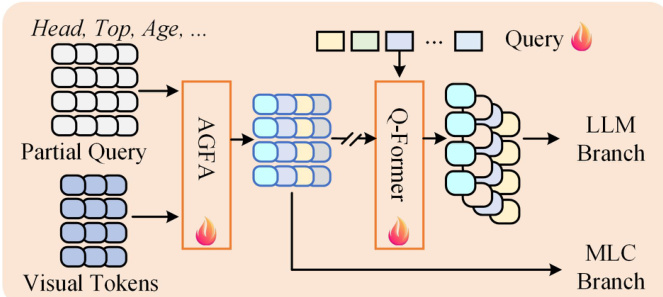
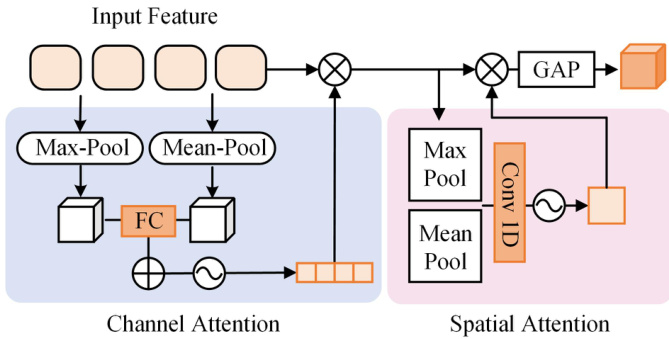
视觉特征随后输入至多嵌入查询 Transformer(MEQ-Former),该模块专为提取不同属性组的特定特征而设计。属性根据头部、上身服装或动作等语义类型被划分为 Aj 组。针对每组,生成一组局部查询 Qp,并通过属性组特征聚合(AGFA)模块进行处理。该模块由堆叠的前馈网络与交叉注意力层构成,计算 Fq=FFN(CrossAttn(Q=Qp,K=FV,V=FV)),输出组特定特征 Fg。这些特征进一步由 Q-Former 处理,该模块作为视觉与语言模态的桥梁,生成文本相关信息 Fqj。为捕捉细粒度细节,将卷积块注意力模块(CBAM)应用于组特征,从而实现针对特定属性的预测。
LLM 分支通过利用自然语言推理能力来增强属性识别。针对每个属性组构建指令,例如“分析人物照片,并将其分类为属性。头部佩戴的是什么?”。这些指令经过 token 处理以生成指令嵌入 TE,随后与视觉特征 Fq 拼接形成指令特征 FI。在训练阶段,真实描述被嵌入并与 FI 拼接,作为 LLM(通常为 Vicuna-7B 或 OPT-6.7B 模型)的初始输入。LLM 使用 LoRA 进行微调,低秩维度 r 设置为 32,最终隐藏状态用于生成行人属性的文本描述。生成的描述随后由语言模型头处理,输出用于属性分类的 logits。
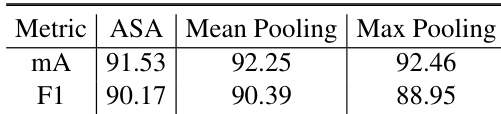
最终分类结果通过聚合视觉与语言分支的预测值获得。该框架采用两种视觉分类器:属性级分类器与实例级分类器,两者均利用多层感知机(MLP)与 CBAM 模块。这些分类器的预测结果与语言分支的输出通过三种策略之一进行融合:属性特定聚合(ASA)、平均池化或最大池化。在默认配置中,采用平均池化对三个分支的 logits 进行平均。训练过程中,属性预测分支采用加权交叉熵损失,LLM 分支的描述生成采用交叉熵损失。损失函数设计已考虑类别不平衡问题,并使用 AdamW 优化器进行优化,学习率设置为 0.00002,权重衰减为 0.0001。
实验
评估环节在多个公开数据集与跨领域划分上,将提出的 LLM-PAR 框架与 17 种最先进的行人属性识别方法进行了基准对比。对比实验验证了视觉分类与大语言模型结合的整体有效性,消融研究则证实 AGFA 模块、优化的定位策略以及定制化的聚合技术显著提升了特征整合与识别可靠性。组件分析进一步表明,谨慎平衡架构复杂度与针对性特征学习能够获得稳健性能,并有效缓解常见的生成幻觉问题。
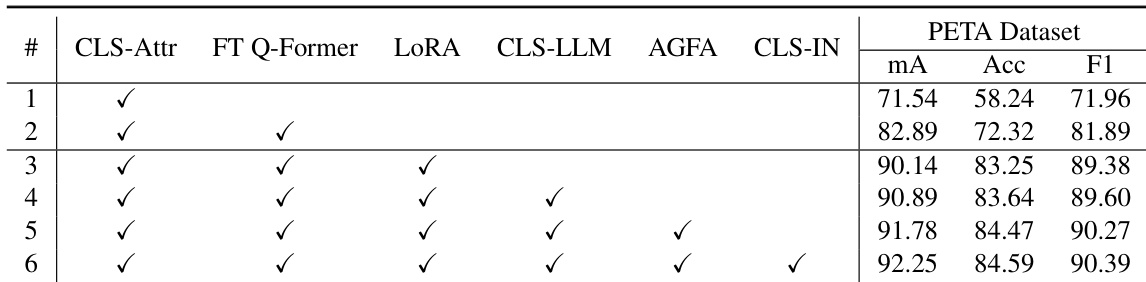
本文在 PETA 数据集上开展消融研究,以评估 LLM-PAR 框架中各组件的贡献。结果表明,按顺序添加各组件均可提升性能,完整模型在所有指标上均取得最高分数。AGFA 模块与 CLS-IN 模块的集成带来持续的性能提升,而所有组件的组合实现了最佳整体效果。相较于基线,加入 AGFA 模块使所有指标的性能均得到改善。CLS-IN 模块对性能提升有所贡献,尤其在细粒度属性识别方面。包含所有组件的完整模型在 PETA 数据集上取得了最高分数。
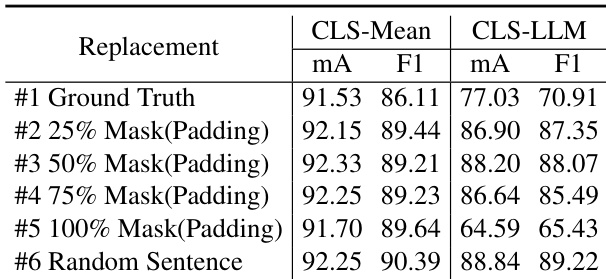
本文分析了不同真实标签替换策略对模型性能的影响,重点关注掩码与随机句子替换的使用。结果表明,使用训练集中的随机句子替换真实标签可获得最佳性能,而直接使用真实标签会导致泛化能力下降。最优策略采用 50% 的掩码率,相较于其他方法提升了识别指标。使用训练集随机句子替换真实标签取得最佳表现。50% 的掩码率相较于其他掩码策略提高了识别指标。直接使用真实标签会导致泛化能力差且性能较低。
{"summary": "本文在多个数据集上对提出的 LLM-PAR 方法与其他多种最先进的行人属性识别模型进行了全面评估。结果表明,LLM-PAR 取得了卓越的性能,尤其在跨领域设置下表现突出,且其有效性因 AGFA 模块与属性特定聚合策略等特定设计选择而得到增强。消融研究进一步验证了各独立组件的贡献,凸显了视觉分支、LLM 分支与特征聚合机制的重要性。", "highlights": ["LLM-PAR 在多个基准上取得了最先进的结果,在随机划分与跨领域划分中均优于现有方法。", "AGFA 模块与属性特定聚合策略通过增强特征表示与融合,显著提升了识别性能。", "消融研究证实,结合视觉与语言建模组件可有效提升属性识别准确率。"]
本文评估了不同大语言模型(LLM)对提出框架的影响,并在多项指标上进行了性能对比。结果表明,尽管两种模型均取得较高性能,但 Vicuna-7B 在多数情况下略优于 OPT-6.7B,这表明 LLM 的选择会影响识别结果。对比分析凸显了为有效属性识别选择合适 LLM 的重要性。Vicuna-7B 在关键指标上均取得高于 OPT-6.7B 的性能。两种 LLM 之间的性能差异虽小但保持一致,表明模型选择会产生可测量的影响。结果证实,不同的大语言模型会影响框架的整体有效性。

本文在多个数据集上将提出的 LLM-PAR 方法与一系列最先进的行人属性识别模型进行了评估,在准确率与 F1 分数方面展现出优越性能。该方法结合了视觉分类与大语言模型能力,组件分析证实了 AGFA 模块及 LLM 分支集成等特定设计选择的有效性。结果表明,LLM-PAR 在所有评估数据集上均取得最先进的结果,在随机划分与跨领域设置中均优于现有方法。LLM-PAR 在 PETA、PA100K 与 RAPv1 数据集上取得领先成绩,在多项指标上超越以往方法。大语言模型分支的集成显著提升了性能,消融研究证实了其与视觉主干的互补作用。AGFA 模块与属性特定聚合策略对于提高识别准确率及有效处理属性组特征至关重要。
本文在多个数据集上将 LLM-PAR 框架与最先进的行人属性识别模型进行对比,以验证其在标准与跨领域环境中的鲁棒性。PETA 数据集上的消融研究证实,按顺序集成视觉分支、语言建模分支以及 AGFA 与 CLS-IN 等专用模块,能够持续提升特征表示与识别准确率。关于训练数据策略的补充实验表明,相较于直接使用标签,战略性掩码与随机句子替换可显著改善泛化能力,而不同大语言模型的对比则表明模型架构的选择对最终性能具有中等程度的影响。综上所述,这些发现证实,通过针对性特征聚合与稳健的数据处理来协同视觉与语言能力,能够构建出高度有效的属性识别系统。