Command Palette
Search for a command to run...
稳定扩散与扩散器
摘要
一句话总结
Built upon Stable Diffusion, SDSeg is the first latent diffusion segmentation model that employs a latent estimation strategy for a single-step reverse process and latent fusion concatenation to eliminate multiple sampling, surpassing existing methods with stable, state-of-the-art performance across five benchmark datasets featuring diverse imaging modalities.
核心贡献
- The SDSeg framework adapts Stable Diffusion to operate within a compressed latent space, effectively mitigating the high computational costs and inefficient optimization typical of pixel-space diffusion segmentation.
- A direct latent estimation strategy enables the model to generate segmentation maps via a single-step reverse process, while a latent fusion concatenation mechanism eliminates the necessity for multiple sampling iterations.
- Comprehensive evaluations across five diverse medical imaging benchmark datasets demonstrate that the method achieves state-of-the-art performance while substantially reducing training resources, accelerating inference speed, and ensuring prediction stability.
引言
Medical image segmentation is critical for automating clinical diagnostics and reducing physician workload, with diffusion models recently gaining traction for their ability to generate highly accurate segmentation maps. Despite their promise, prior diffusion-based methods face significant bottlenecks: they typically operate in high-resolution pixel space, which wastes computation on sparse semantic data, and they demand extensive reverse steps alongside multiple sampling runs to stabilize predictions. To overcome these limitations, the authors leverage Stable Diffusion to develop SDSeg, a latent diffusion segmentation framework that operates in a compressed, computationally efficient latent space. By introducing a targeted latent estimation loss and a latent fusion concatenation technique, they enable the model to produce stable segmentation outputs in a single reverse step without requiring multiple samples. This streamlined architecture significantly reduces training overhead, accelerates inference, and achieves state-of-the-art performance across five diverse medical imaging benchmarks.
方法
The authors leverage a diffusion-based framework for medical image segmentation, termed SDSeg, which operates in a latent space to achieve efficient and accurate segmentation. The overall architecture, as shown in the figure below, consists of a trainable vision encoder, a diffusion process in latent space, and a segmentation map reconstruction module. The framework begins by encoding an input medical image C∈RH×W×3 into a latent representation zc=τθ(C) using a trainable vision encoder τθ. Concurrently, the segmentation map X∈RH×W×3 is compressed into a latent representation z=E(X) via an autoencoder, with the decoder D reconstructing the segmentation map from this latent space. The autoencoder is kept frozen during training, as it performs adequately for binary segmentation maps, which is validated by the visualizations in the figure below.
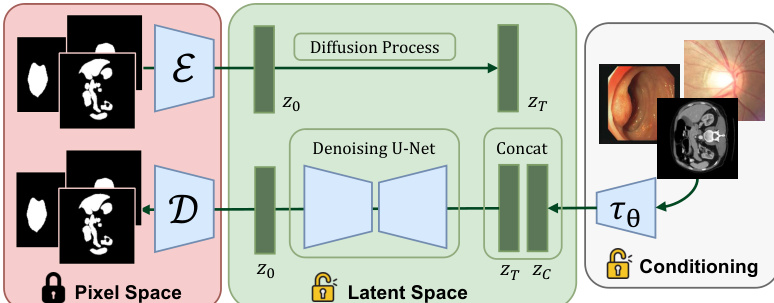
The diffusion process is conducted entirely in the latent space, where the initial latent z0 of the segmentation map is progressively corrupted with Gaussian noise over t time steps, resulting in zt. The denoising U-Net learns to estimate the noise n added at each step, formulated as n~=f(zt;zc), where f(⋅) denotes the denoising U-Net. This noise prediction is used to derive a direct estimate of the original latent z0 through a simple transformation, enabling single-step latent prediction and bypassing the need for iterative reverse diffusion steps. This approach introduces a supervision branch with a latent loss function Llatent=L(z~0,z0), which, combined with the noise prediction loss Lnoise, forms the final training objective L=Lnoise+λLlatent, with λ=1.
To integrate the image and segmentation latent representations, the model employs a concatenation-based fusion strategy, where the latent representation zc from the vision encoder is concatenated with the noisy latent zt from the diffusion process. This concatenation is performed at multiple layers of the denoising U-Net, allowing the segmentation map to be guided by the semantic and structural features extracted from the input image. The trainable vision encoder τθ is designed with the same architecture as the autoencoder's encoder, consisting of a downsampling block, a mid block with self-attention, and an output block, and is initialized with pre-trained weights. This design enables the encoder to capture rich semantic information from diverse medical image modalities, enhancing the model's adaptability and performance.
实验
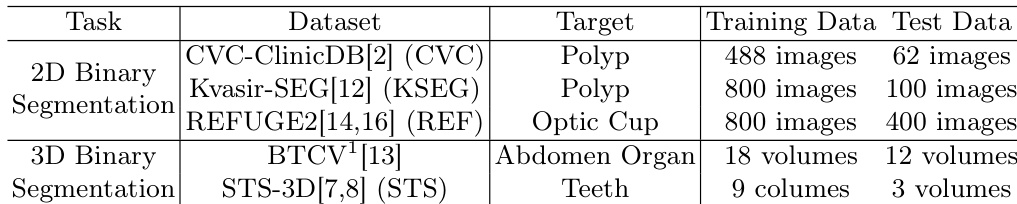
The evaluation utilizes five diverse medical imaging datasets to assess segmentation accuracy, computational efficiency, output stability, and architectural contributions. Experiments validate that SDSeg consistently outperforms existing methods in accuracy and generalization while achieving substantially faster inference through a streamlined single-step sampling process. Stability assessments confirm the model produces reliable and consistent segmentation maps despite varying initial noise, meeting clinical reliability standards. Additionally, ablation studies demonstrate that the proposed latent fusion and trainable encoder modules effectively enhance semantic feature extraction and accelerate convergence without relying on external samplers.
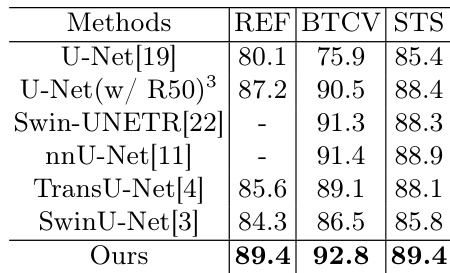
The authors compare their model against several state-of-the-art segmentation methods across multiple datasets, demonstrating superior performance in terms of segmentation accuracy. The model achieves the highest scores on all evaluated datasets, indicating strong effectiveness and generalization capabilities. The proposed method outperforms all compared models on the evaluated datasets. The model achieves the highest segmentation accuracy across multiple datasets. The method demonstrates strong generalization ability by excelling on diverse datasets.
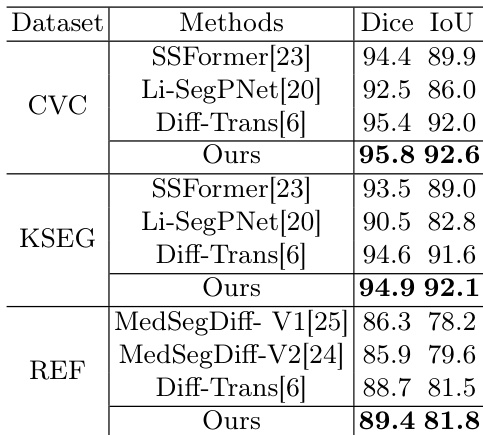
The authors compare their method against several state-of-the-art segmentation models across multiple datasets, demonstrating superior performance in terms of segmentation accuracy. The results show that their approach achieves higher Dice and IoU scores compared to existing methods, particularly on the CVC and KSEG datasets, while also maintaining strong performance on the REF dataset. The proposed method achieves higher segmentation accuracy than competing models on multiple datasets, especially on CVC and KSEG. The model outperforms other diffusion-based segmentation methods in terms of Dice and IoU scores. The approach maintains strong performance on the REF dataset, indicating robustness across different imaging modalities.
The authors conduct experiments on multiple datasets to evaluate the performance, efficiency, and stability of their model. Results show that the model achieves strong segmentation accuracy across diverse imaging modalities, outperforming existing methods while requiring significantly fewer computational resources and inference time. It also demonstrates high stability in predictions despite variations in initial conditions. The model achieves superior segmentation accuracy across multiple datasets with varying imaging modalities. The model is significantly more efficient in terms of training resources and inference speed compared to other diffusion-based methods. The model produces stable and consistent segmentation results, showing high reliability under different initial noise conditions.
The authors present an ablation study to evaluate the contribution of key components in their model, focusing on latent estimation, latent fusion, and a trainable image encoder. Results show that combining all three components yields the highest performance across multiple datasets, with the latent estimation module enabling a single-step inference process. The inclusion of latent fusion and the trainable encoder significantly improves segmentation accuracy compared to the baseline. Combining latent estimation, latent fusion, and a trainable image encoder leads to the best performance. Latent estimation enables a single-step inference process, improving efficiency. Latent fusion and the trainable image encoder significantly boost segmentation accuracy compared to the baseline.

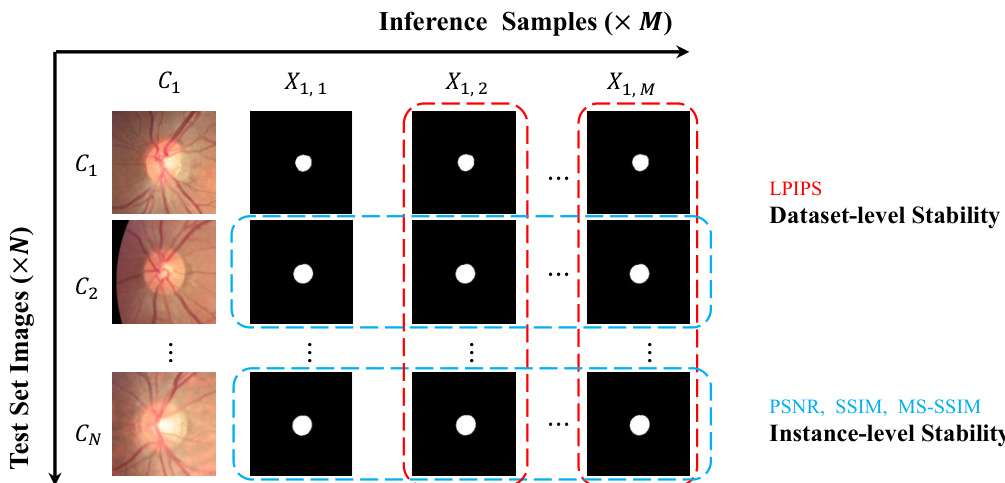
The authors compare their model with other diffusion-based segmentation methods on stability metrics, showing that their approach achieves significantly lower LPIPS scores and higher PSNR, SSIM, and MS-SSIM values for both segmentation maps and predicted scores. Results indicate that the proposed method provides more consistent and reliable outputs across different inference runs and initial noise conditions. The improvements are attributed to the latent estimation and concatenation fusion modules, which enhance stability and reduce dependency on external samplers. The proposed method achieves superior stability with lower LPIPS and higher PSNR, SSIM, and MS-SSIM compared to baseline models. The model shows consistent performance across repeated inferences, indicating high reliability in segmentation outputs. The integration of latent estimation and concatenation fusion modules contributes to improved stability and faster inference without external samplers.

The authors benchmark their segmentation model against state-of-the-art methods across multiple datasets, employing ablation and stability tests to validate the contributions of key architectural components. Qualitative analysis confirms that the integrated latent estimation, fusion, and trainable encoder modules collectively deliver superior segmentation accuracy and robust generalization across diverse imaging modalities. These components also enable highly efficient single-step inference while significantly reducing computational demands. Finally, stability evaluations demonstrate that the proposed design ensures consistent and reliable outputs across varying initial conditions, eliminating the need for external sampling procedures.