Command Palette
Search for a command to run...
MegActor:利用原始视频的强大力量实现生动的肖像动画
MegActor:利用原始视频的强大力量实现生动的肖像动画
Shurong Yang Huadong Li Juhao Wu Minhao Jing Linze Li Renhe Ji Jiajun Liang Haoqiang Fan
一键部署 MegActor
摘要
尽管在肖像动画领域,原始驱动视频包含的面部表情信息比地标等中间表示更为丰富,但它们很少成为研究的主题。这是由于由原始视频驱动的肖像动画存在两个固有挑战:1)显著的身份泄露;2)无关的背景和面部细节(如皱纹)会降低性能。为了利用原始视频的强大力量实现生动的肖像动画,我们提出了一种开创性的条件扩散模型,名为 MegActor。首先,我们引入了一种合成数据生成框架,用于创建具有相同运动和表情但身份不一致的视频,以缓解身份泄露问题。其次,我们对参考图像的前景和背景进行分割,并使用 CLIP 对背景细节进行编码。然后将这些编码信息通过文本嵌入模块集成到网络中,从而确保背景的稳定性。最后,我们将参考图像的外观进一步风格化迁移到驱动视频中,以消除驱动视频中面部细节的影响。我们的最终模型仅使用公开数据集进行训练,取得了与商业模型相当的结果。我们希望这有助于开源社区的发展。
一句话总结
MegActor 是一种条件扩散模型,它利用合成数据框架生成具有相同运动和表情但身份不一致的视频,以减轻身份泄露问题;通过文本嵌入集成 CLIP 编码的背景分割以稳定背景;并将参考图像的外观风格迁移至驱动视频,以消除干扰性的面部细节。该模型仅使用公开数据集进行训练,最终实现了与商业模型相媲美的性能,能够生成生动的肖像动画。
核心贡献
- 本文提出了 MegActor,一种条件扩散模型。该模型通过采用合成数据生成框架,将运动控制与主体身份解耦,从而从原始驱动视频中生成肖像动画,并有效减轻身份泄露问题。
- 通过背景分割与 CLIP 编码模块,结合将参考外观映射到驱动帧的风格迁移流程,实现了对无关背景与面部细节的鲁棒性,有效过滤视觉噪声。
- 该框架仅使用公开数据集进行训练,通过 SOTA 对比与视觉评估证明,其动画质量与身份保持能力可与商业模型相媲美。
引言
肖像动画技术能够将驱动视频中的运动与面部表情迁移至目标图像,同时保持身份与背景的一致性,为数字分身和 AI 驱动对话等应用提供动力。尽管近期基于扩散模型的方法利用文本、图像或音频控制提升了视觉质量,但它们在处理细微面部动作时仍显吃力,依赖不稳定的外部姿态检测器,或在原始视频数据上训练时容易出现身份泄露问题。为突破这些瓶颈,本文提出 MegActor,这是一种条件扩散模型,可直接利用原始驱动视频生成高度表现力的肖像动画。该研究通过自定义合成数据框架将运动与外观解耦,以解决身份泄露问题;利用 CLIP 编码的文本嵌入稳定背景生成;并应用风格迁移技术过滤驱动视频中的无关面部细节。该方法实现了稳健且达到像素级精度的动画效果,在仅依赖公开训练数据的情况下,其性能与最先进的商业系统持平。
数据集
- 数据集构成与来源: 作者使用公开的视频数据集(VFHQ 和 CelebV-HQ)对模型进行训练。为了解决身份与背景泄露问题,他们通过 Face-Fusion 和 SDXL 生成合成数据,以此补充真实视频。
- 子集详情与筛选: 真实数据来源于 VFHQ 和 CelebV-HQ。合成子集包括 AI 换脸视频(将每个驱动帧与来自不同个体的源图像配对生成)以及使用 SDXL 生成的风格化视频。作者还应用 L2CSNet 测量帧间的视线偏移,分离出约 5% 表现出显著眼球运动的数据,用于专项微调。
- 训练用途与混合比例: 在初始训练阶段,模型使用混合数据,包含 50% 的真实视频、40% 的 AI 换脸视频和 10% 的风格化视频。作者采用步长为 2 采样帧,生成 16 帧片段,其中一帧作为参考帧,其余帧同时作为驱动输入和真实标签。在第二阶段,模型仅使用步长为 12 的高视线偏移子集进行微调,同时保持 16 帧片段的长度。
- 处理与增强策略: 为最小化背景泄露,作者使用 pyFacer 检测人脸,并将所有非面部像素遮罩为黑色。他们还对驱动视频应用随机增强,包括灰度转换以及尺寸和纵横比调整,这些操作会改变面部结构而不影响表情或头部姿态。所有视频帧在训练前均被调整大小为 512×512 像素。
方法
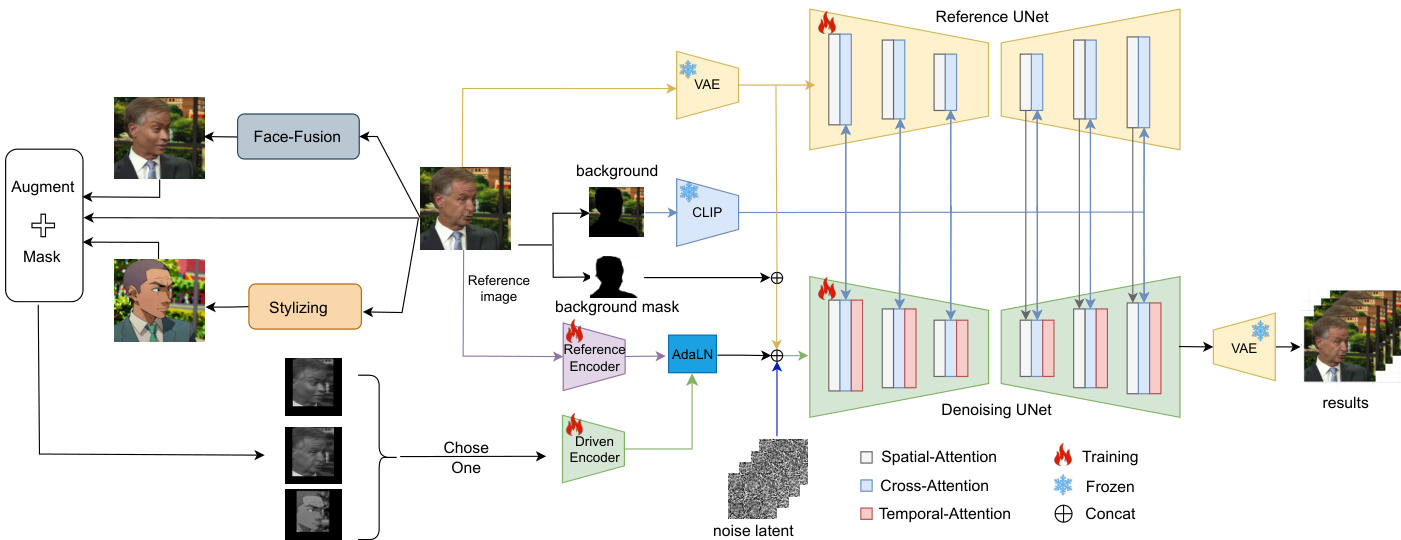
作者利用一种名为 MegActor 的条件扩散模型架构,实现由原始视频输入驱动的生动肖像动画。整体框架旨在解决使用原始驱动视频时的两大核心挑战:身份泄露,以及由无关背景和面部细节导致的性能下降。系统首先通过独立流程处理参考图像和驱动视频,随后将它们的特征整合到统一的去噪过程中。
参考图像经过处理以提取身份与背景信息。ReferenceNet 基于 Stable Diffusion 1.5 (SD1.5) 的 UNet 架构,用于编码细粒度的身份与背景特征。同时,参考图像的背景区域被隔离,并使用 CLIP 的图像编码器进行编码。该编码后的背景信息随后通过文本嵌入模块集成到模型中,替代了标准的文本提示。从 CLIP 提取的全局 (CLS) 和局部块特征被合并,并通过交叉注意力机制注入到 ReferenceNet 和去噪 UNet 中,以稳定生成输出中的背景。
对于驱动视频,采用轻量级的 DrivenEncoder 提取运动特征。该编码器由四个具有不同通道大小的 2D 卷积层组成,旨在高效处理视频帧。运动特征与从扩散过程中采样的噪声潜变量分辨率对齐。为保留预训练去噪 UNet 的空间结构,作者将 conv-in 层中新添加通道的参数初始化为零。在运动特征提取过程中,将参考图像作为引导加入,进一步增强了 DrivenEncoder。参考图像的潜表示(通过变分自编码器 VAE 获取)与源自 DensePose 的前景遮罩,在输入去噪 UNet 前,与噪声潜变量和运动特征进行拼接。这确保了运动迁移过程尊重参考角色的身份特征。
为提高生成帧之间的时间一致性,在去噪 UNet 的每个 Res-Trans 层之后插入时间模块。该模块执行帧间的时间注意力计算,捕捉时间依赖关系并增强动画的连续性。时间模块被单独微调以优化其性能,同时不破坏基础模型的预训练图像生成能力。
驱动视频经过预处理以减轻身份泄露。采用合成数据生成框架,应用换脸与风格化技术创建具有相同运动和表情但身份不一致的视频。风格化视频在训练阶段使用,以降低皱纹等面部细节的影响。此外,对驱动视频应用了包括缩放和纵横比调整在内的数据增强方法。所有非面部区域均被遮罩,使模型专注于面部运动。
实验
评估通过驱动多个数据集的视频对不同的参考帧进行动画化,验证了跨身份肖像生成的能力。在独立视频源上的初步测试证实,该模型在准确保持背景细节与主体身份的同时,能够忠实迁移复杂的面部表情与细微的头部动作。与最先进基线的对比评估进一步凸显了其在细微解剖特征上的清晰度优势,并展示了与领先方法相匹敌的整体动画质量。这些定性结果共同确立了该模型在跨身份动画任务中稳健的泛化能力与竞争地位。
作者通过跨身份视频生成任务将 MegActor 与现有方法进行评估对比。结果表明,MegActor 能够生成逼真的肖像动画,在保持身份与详细面部特征的同时,达到与最先进方法相当的性能,并支持开源代码与权重。在跨身份条件下,MegActor 生成保留身份与详细面部表情的逼真肖像动画。MegActor 取得了与最先进方法相当的结果,与 EMO 相比,在牙齿等区域的输出更为清晰。与对比列表中列出的其他几种模型不同,MegActor 支持开源代码与权重。
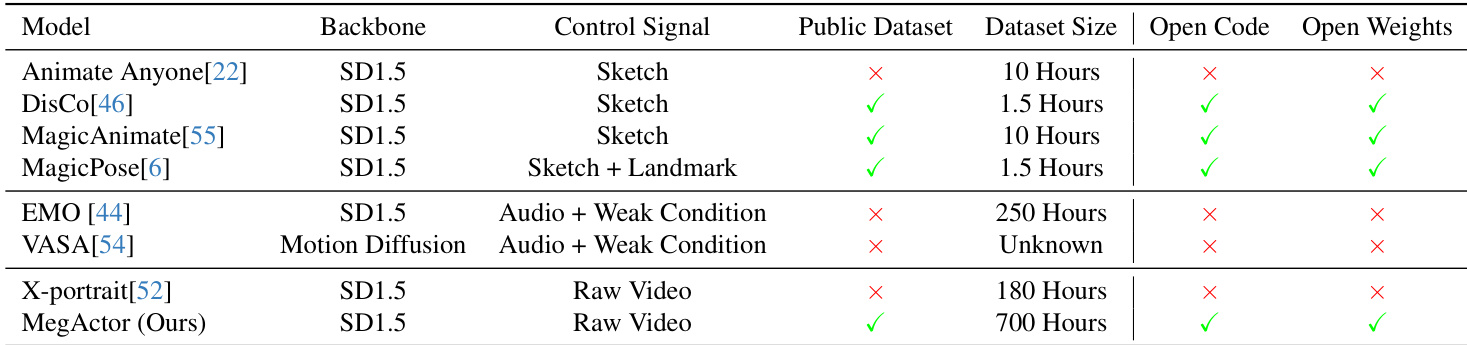
作者通过跨身份视频生成任务评估 MegActor,以验证其生成维持主体身份与精细面部细节的逼真肖像动画的能力。定性评估证实,该模型成功保留了身份特征,并以与现有最先进方法持平或超越的清晰度渲染出富有表现力的特征。此外,该框架凭借出色的性能并全面开源代码与权重,树立了可访问性的新标准。