Command Palette
Search for a command to run...
如何使用 Transformers 和 Tokenizers 从头开始训练新的语言模型
摘要
一句话总结
作者提出了试错与演示(TnD)框架,这是一种交互范式,将学生试错、教师演示和能力条件化奖励相结合,旨在以相同或更少的参数量加速模型从零开始的词汇习得。研究证明,该方法优于非交互式后训练方法,教师词汇选择会影响特定词汇的学习效率,并揭示了“熟能生巧”效应,即试错频率与学习曲线高度相关。
核心贡献
- 提出了一种试错与演示(TnD)学习框架,通过整合学生试错、教师演示和能力条件化奖励来模拟交互式的语言习得过程。
- 系统性实验表明,TnD框架能够加速词汇习得,在参数量相同或更少的架构上,其学习曲线优于标准基线模型。
- 通过控制消融实验隔离了学生试错与教师演示的独立贡献,同时教师筛选的词汇通过“熟能生巧”效应调节学习效率,其中试错频率与特定词汇的学习轨迹高度相关。
引言
现代大型语言模型通常先在海量文本语料库上进行非交互式训练,随后再进行事后对齐,这与人类通过社会互动和纠正性指导高效习得语言的方式形成鲜明对比。先前的计算研究主要依赖被动学习设置、特定领域约束或缺乏明确教师演示与针对性纠正反馈的简单成功指标。作者利用试错与演示框架,通过学生生成、教师纠正以及发展阶段条件化奖励信号的交互循环,从零开始训练神经语言模型。实验表明,这种交互范式显著加速了词汇习得过程,证明结构化练习与明确演示为传统自监督预训练提供了更高效的替代方案。
数据集

- 数据集来源与构成: 作者使用两个公开文本语料库构建评估框架:BookCorpus 和 BabyLM 数据集。
- 子集详情与过滤规则: 他们构建了两个目标词汇集用于评估。通用(CMN)词汇集捕捉了两个语料库中跨越多种词性的高频词汇。交际发展清单(CDI)词汇集则来源于标准化的儿童语言评估。为确保评估的可靠性,他们排除了会干扰分词的多词 token,移除了在评估划分中出现次数少于 100 次的词汇,并将每个词汇的实例数限制在 512 以内。最终得到 309 个 CMN 词汇,BookCorpus 的 345 个 CDI 词汇,以及 BabyLM 的 243 个 CDI 词汇。
- 数据使用与处理流程: 作者将这些子集专用于评估而非训练。他们计算平均惊奇度以跟踪预测质量,并在对数训练步骤上绘制学习曲线。为衡量习得速度,他们使用 0.50 至 0.95 的惊奇度阈值计算神经习得年龄,并对结果取平均以确保稳健性。他们还在满足习得阈值时统计词汇数量,以监控有效词汇量的增长。
- 其他处理与建模细节: 工作流程通过严格过滤复合项来处理分词器约束,并依赖双sigmoid曲线拟合来捕捉学习平台期。所有指标均源自标准化的惊奇度计算,评估划分直接从原始语料库中提取,未进行额外的混合或增强。
方法
作者提出了一种试错与演示(TnD)学习框架,旨在无人类干预的环境中模拟带有纠正性反馈的交互式语言习得。该框架通过三个关键组件的循环运行:学生模型试错、教师模型演示以及奖励评估。整体流程始于一个学生模型,该模型初始化为随机初始化的 GPT-2,并使用来自训练语料库的句子前五个 token 作为提示以生成续写内容。生成的文本构成学生的试错结果。同时,一个基于相同 GPT-2 架构并使用因果语言建模(CLM)目标预训练的教师模型,使用相同的五个 token 作为提示以生成自然语言演示。随后,奖励模型对学生的试错结果与教师的演示进行评估,以判断语言输出的发展阶段。该奖励源自神经年龄预测器,该预测器估计给定文本输出通常出现的训练步骤,并根据当前训练步骤进行调整以形成年龄条件化奖励。该框架在交互与非交互学习阶段之间交替进行。在非交互阶段,学生模型通过标准的因果语言建模进行学习,预测序列中的下一个 token 以最小化 CLM 损失。在交互阶段,学生模型通过近端策略优化(PPO)算法利用强化学习进行训练。PPO 的训练批次包含学生的试错结果与教师的演示,使学生能够从自身输出与教师更优的示例中学习。PPO 算法采用裁剪代理目标与广义优势估计来更新策略,并通过均方误差训练价值函数。值得注意的是,为鼓励更大幅度的更新并防止过度依赖参考模型,省略了人类反馈强化学习中常见的 KL 散度惩罚项。这种交替调度(三次因果语言建模步骤后接一次强化学习步骤)旨在模拟被动语言暴露与主动纠正性学习。整个过程如图表所示。
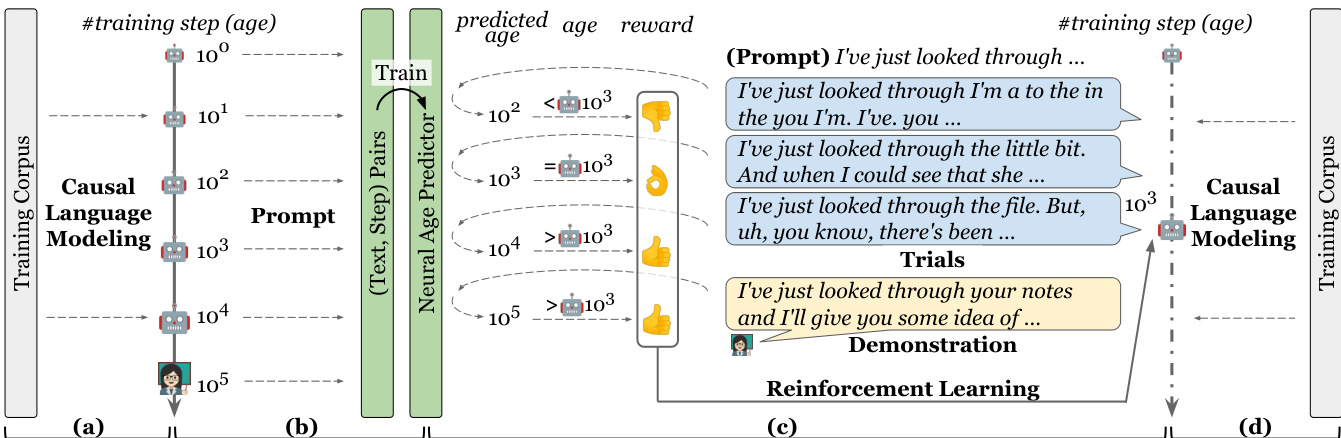
实验
在两个不同训练语料库上开展的实验将试错与演示框架与标准因果语言建模基线进行对比,以验证纠正性反馈、模型扩展与主动练习如何影响神经词汇习得。结果表明,将学生试错与教师演示相结合可显著加速早期词汇学习,尽管最终模型容量与下游任务性能最终会与标准预训练趋同。进一步的消融实验证实,交互试错与明确演示对于这种加速学习均不可或缺,其中主动练习对功能词与谓词尤为有益。这些发现验证了结构化的纠正性反馈与迭代练习能够高效优化不同模型规模下的词汇习得过程,同时保持稳健的性能。
作者使用两个训练语料库对比了不同模型在下游自然语言理解任务上的表现。结果显示,TnD 模型在大多数任务上的表现与 CLM 模型相当或略优,部分任务有显著提升,少数任务略有下降。TnD 模型在大多数下游 NLU 任务上与 CLM 模型表现持平。与 CLM 模型相比,TnD 模型在文本蕴含识别任务上表现出显著提升。在问答 NLI 任务上,TnD 模型的表现不及 CLM 模型。

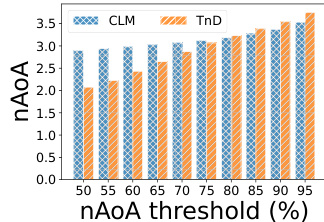
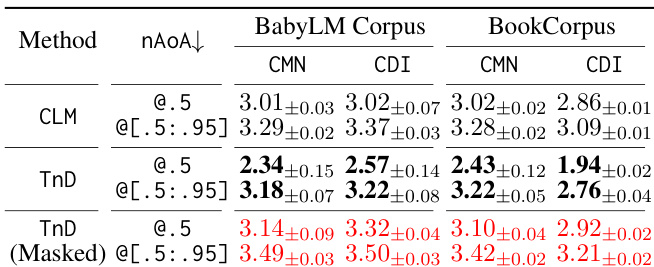
作者分析了不同惊奇度阈值下的神经习得年龄(nAoA),以评估语言模型中的词汇学习效率。结果显示,与 CLM 基线相比,TnD 框架显著改善了早期词汇习得,但随着学习过程推进,性能差距逐渐缩小,表明长期学习结果趋于收敛。TnD 模型在初始阶段实现更快的学习,尤其是在较低惊奇度阈值下,而两种模型最终均达到相似的词汇掌握水平。TnD 框架加速了早期词汇习得,在较低惊奇度阈值下表现出显著低于 CLM 基线的 nAoA。在较高惊奇度阈值下,TnD 与 CLM 之间的性能差距缩小,表明学习结果最终收敛。TnD 使模型在初始训练阶段能够更快习得词汇,但随着时间的推移,两种模型均达到可比的掌握水平。
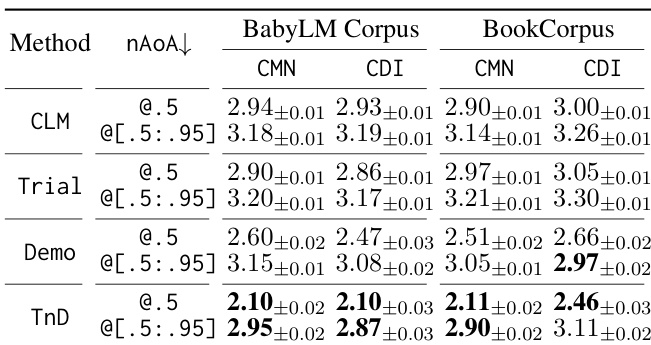
作者对比了不同学习框架在两个语料库和两个测试词汇集上的表现,通过评估学习曲线、神经习得年龄与有效词汇量来衡量其对词汇习得的影响。结果显示,与基线相比,TnD 框架加速了早期词汇学习,尤其在习得速度与词汇量增长方面,尽管性能随时间推移逐渐收敛。这些发现因模型规模与训练条件不同而保持一致,凸显了纠正性反馈在语言学习中的重要性。TnD 框架相比基线模型加速了早期词汇习得。TnD 模型在初始训练阶段显示出更快的词汇量增长,但随时间推移与基线趋同。TnD 框架的优势在不同模型规模与训练语料库中保持一致。
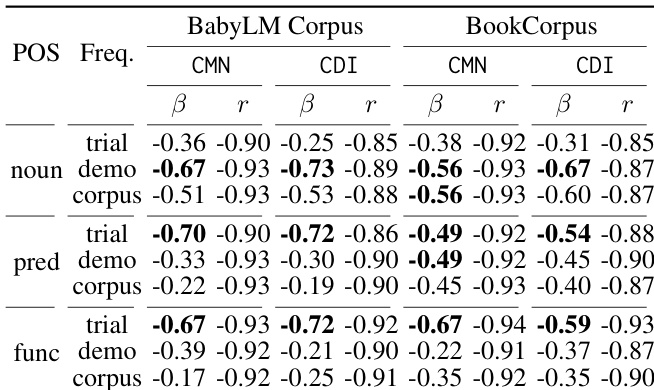
作者分析了不同词汇暴露来源(学生试错、教师演示与语料库频率)对神经语言模型词汇习得的贡献,重点考察这些来源如何与不同词性的学习曲线相关联。研究发现,学生试错中的词汇频率与惊奇度呈显著负相关,尤其对于功能词与谓词,表明主动练习在学习这类词汇中发挥关键作用。这种效应对名词而言不太明显,暗示不同词类可能涉及不同的学习机制。学生试错中的词汇频率与学习曲线显著相关,尤其对功能词与谓词而言。试错对词汇习得的贡献因词性而异,功能词与谓词受到的影响强于名词。与试错相比,教师演示和语料库频率与学习的关联较弱且存在更强的共线性。
作者对比了不同语言模型在两个语料库上的表现,使用神经习得年龄与有效词汇量评估词汇习得情况。TnD 模型相比 CLM 基线在早期学习中表现出改善,尤其在 BabyLM 语料库中,但随着训练推进,性能差异逐渐减小。TnD 模型的掩码版本在两个语料库的早期习得指标上均展现出进一步改进。TnD 模型相比 CLM 基线加速了早期词汇习得,尤其在 BabyLM 语料库上。TnD 与 CLM 之间的性能差距随时间推移逐渐缩小,在训练后期趋于收敛。掩码 TnD 变体在早期习得指标上优于标准 TnD 与 CLM 模型。
实验在多个语料库、下游自然语言理解任务与词汇习得指标上评估 TnD 框架与标准语言模型基线的表现,以检验学习效率与长期掌握程度。下游任务评估验证了 TnD 匹配或略微提升基线性能,并表现出显著的任务特异性差异,而习得分析证实该框架显著加速了早期词汇量增长与学习速度。这些发现表明,主动学生试错驱动了初始语言习得,尤其对功能词与谓词而言,尽管在长期训练中性能逐渐与基线趋同。最终结果表明,针对性的早期反馈提升了初始学习效率,且未改变最终的语言熟练度结果。