Command Palette
Search for a command to run...
RWKV – transformer 与 RNN 的强强联合
摘要
一句话总结
本文评估了中英跨语言结构启动效应,结果表明 Transformer 架构在准确率上优于循环神经网络,增幅超过 25.84% 至 33.33%。该结果挑战了人类句子处理主要依赖循环机制的假设,并凸显了基于线索的检索机制的作用。
核心贡献
- 本研究评估了循环神经网络与多语言自回归 Transformer 模型在中英跨语言结构启动任务上的表现。
- 实验结果表明,Transformer 架构在生成启动句法结构方面优于循环网络,准确率提升幅度达 25.84% 至 33.33%。
- 通过测量源句与目标句之间的概率变化,发现尽管语义内容一致,这些模型仍表现出抽象的结构启动效应。这些发现挑战了人类句子处理主要依赖即时循环机制的传统假设。
引言
结构启动是指接触特定句法模式会增加其后续使用概率的现象,该现象是评估语言模型如何捕捉层级句法并逼近人类句子处理过程的重要探针。尽管循环神经网络与 Transformer 均在单语环境中展现出启动效应,但既往研究尚未系统比较它们在跨语言层面的能力,尤其是在类型学差异较大的语言之间。为填补这一空白,研究在中文至英文的启动任务上评估了这两种架构,并证明 Transformer 能更有效地生成具有结构启动特征的输出。该发现挑战了人类句法处理主要依赖循环机制的长期假设,并为计算模型如何表征不同语系间的句法提供了新见解。
数据集
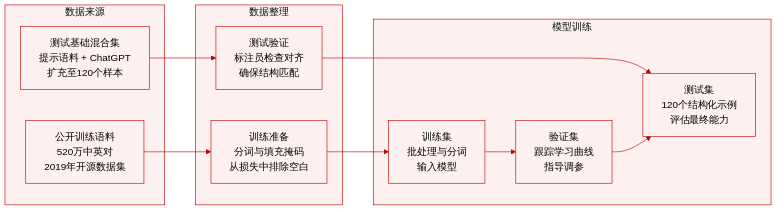
- 研究采用 Xu (2019) 提供的公开中英平行语料库(包含 520 万对句子)作为主要训练数据集。
- 在评估阶段,构建源自 Cross-language Structural Priming Corpus (Michaelov et al., 2023) 的测试集,初始从四种句法结构(主动语态、被动语态、介词宾语结构和双宾语结构)中各抽取五个句子。
- 利用 ChatGPT 3.5 配合单样本学习提示词对该测试集进行增强,将每种结构扩展至 30 个句子,共计 120 个测试实例。
- 每个中文测试句子均搭配一个正确的英文翻译与一个错误的英文翻译,用于评估句法对齐情况。
- 双语标注员手动审查所有大语言模型生成的输出,以验证翻译对等性,并确保正确答案与源中文句子保持严格的句法对应关系。
- 在预处理阶段,训练数据通过标准 DataLoader 进行批次划分,并使用 Helsinki-NLP tokenizer 进行 token 化。
- 配置 tokenizer 上下文管理器以应用目标语言规则,防止英文输出中出现错误的分词。
- 训练序列中的 Padding token 被赋值为 -100,以在模型训练时将其排除在损失计算之外。
- 训练语料库不包含任何人口统计或身份信息数据,但研究指出部分翻译术语可能存在文化细微差异的丢失。
方法
研究采用编码器-解码器架构来考察翻译模型中的结构启动现象,对比循环神经网络 (RNN) 与 Transformer 在将中文输入转换为句法多样的英文输出时的性能。整体框架包含三个主要阶段:训练、实验与测试。在训练阶段,原始双语数据经过预处理,中文句子通过 Helsinki NLP 处理,英文句子则通过英文预处理流程准备。生成的 token 对随后被输入至基于 GRU 的编码器-解码器或基于 Transformer 的编码器-解码器模型中进行训练。
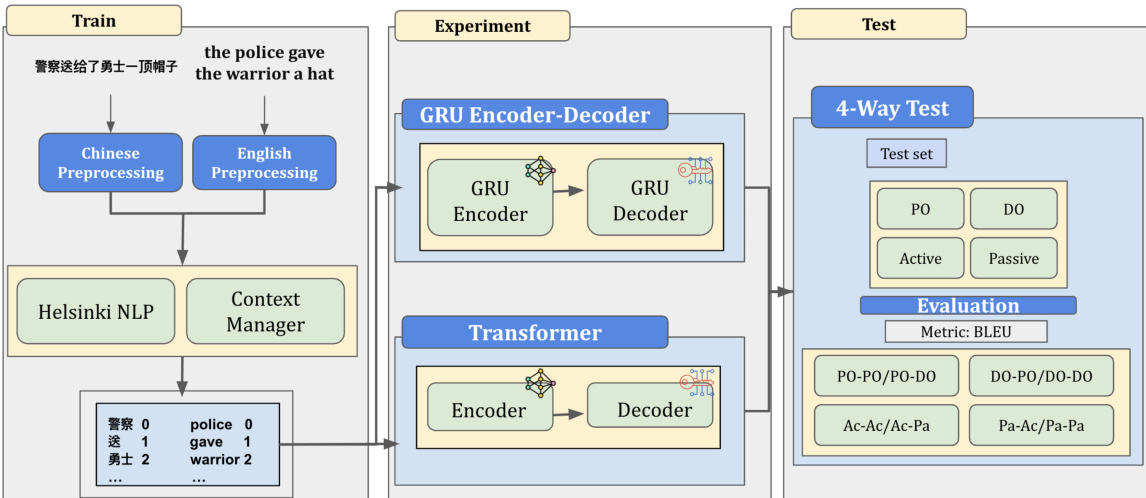
在实验阶段,两种模型在相同数据集上进行训练,GRU 编码器-解码器与 Transformer 编码器-解码器均在相同条件下运行。GRU 编码器-解码器采用门控循环单元,引入更新门与重置门来管理长距离依赖关系并缓解梯度消失问题。更新门控制当前输入与前一隐藏状态的融合程度,使模型能够在解码过程中选择性地吸收相关信息。重置门调节当前输入与前一状态的交互方式,使模型能够遗忘过时信息并聚焦于更相关的特征。此外,GRU 解码器集成了注意力机制,以增强其关注输入序列相关部分的能力,从而提升预测准确率与结构模式识别能力。
Transformer 模型采用自注意力机制,通过识别输入序列中不同位置间的依赖关系来捕捉句子结构。注意力函数定义如下:
Attention(Q,K,V)=softmax(dkQKT)V其中 Q, K, and V 由输入序列的线性变换派生而来,各自包含可学习的权重矩阵。在编码器中,这些矩阵源自同一源序列;而在解码器中,Q 来自目标序列,K 与 V 来自编码器的输出。这使得模型能够同时关注所有位置并捕捉结构关系。为增强特征表示,Transformer 使用多头注意力机制,其中多个注意力头捕捉不同层级的句子特征。多头注意力的输出计算如下:
MH(Q,K,V)=Concat(head1,…,headh)⋅WO其中 WO 为可训练权重矩阵,head1,…,headh 代表每个头的注意力权重。该模型还采用可学习的位置嵌入替代固定的正弦编码,以更准确地捕捉与结构启动相关的相对位置关系。
在测试阶段,采用四向测试评估两种模型在四种句法结构上的表现:介词宾语 (PO)、双宾语 (DO)、主动语态 (Ac) 与被动语态 (Pa)。评估使用 BLEU 指标,将系统生成的英文输出与结构正确的参考译文及错误的参考译文进行对比。两项参考译文之间的 BLEU 分数差异用于量化启动效应。该设置使得能够直接对比各模型在翻译过程中保留输入中文句子句法结构的能力。
实验
本研究通过在中文-英文句子对上进行训练,并测试模型与结构对齐及未对齐的参考句子进行比较时复现跨语言结构启动的能力,来评估基于 GRU 的 RNN 与 Transformer 模型。实验设计验证了模型是否独立于语义内容优先复现启动输入中的句法结构,结果表明两种架构均形成了抽象的跨语言语法表征。定性分析显示,Transformer 始终比 RNN 展现出更强的结构启动效应与更可靠的句法适应能力,这挑战了循环处理更能映射人类句子理解的传统假设。相反,这些结果支持基于注意力的线索检索机制,将其作为认知上合理的框架,用于建模神经网络如何在类型学迥异的语言间捕捉并应用抽象语法模式。
研究对比了基于 GRU 的 RNN 与 Transformer 模型在复现中英跨语言结构启动效应方面的性能。结果表明,Transformer 模型在正确的结构对齐中通常获得更高的 BLEU 分数,尤其在较长 n-gram 上,表明其保留句法结构的能力更强;而 GRU 模型在错误的启动场景下表现出较小的偏差。与 GRU 模型相比,Transformer 模型在正确结构对齐中取得更高的 BLEU 分数。GRU 模型在错误启动结构的预测上比 Transformer 表现出更小的偏差。在跨语言启动任务中,两种模型在主动-被动结构上的表现均优于介词宾语-双宾语结构。
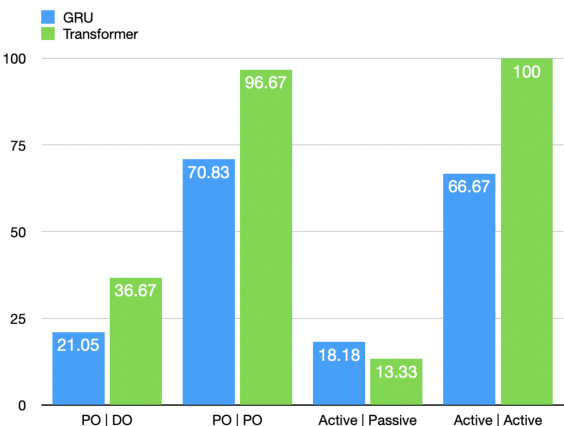
该评估对比了基于 GRU 的 RNN 与 Transformer 架构在复现中英跨语言结构启动效应方面的表现,以验证两者在句法保留与启动适应方面的各自能力。结果表明,Transformer 展现出更强的维持准确结构对齐的内在能力,而 GRU 模型在处理错误启动模式时表现出更高的预测稳定性。总体而言,两种架构均显示出一致的结构偏向,在主动-被动结构上的表现比在介词宾语-双宾语模式上更为可靠。